Linux中ELK集群搭建
如需转载分享,请标明出处,且不用于盈利为目的,谢谢合作!
[Linux中ELK集群搭建]
| 本elk集群版本采用V5.4.3 搭建elk集群需要安装如下软件 elasticsearch-sql-5.4.3.0 elasticserach-5.4.3 elasticsearch-head es-sql-sit-standalone kibana-5.4.3-linux-x86_64 logstash-5.4.3 npm (事先安装好,这里不做介绍) nodejs (事先安装好,这里不做介绍) jdk1.8(事先安装好,这里不做介绍) |
1 ELK安装详解
1.1 ElasticSearch安装部署
参考文档
ELK官网:https://www.elastic.co/
ELK官网文档:https://www.elastic.co/guide/index.html
ELK中文手册:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
ELK中文社区:https://elasticsearch.cn/
ELK-API :https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/transport-client.html
(1)、下载安装包
访问elasticSearch官网地址 https://www.elastic.co/
(2)、规划安装目录
(3)、上传安装包到指定目录
(4)、解压安装包
tar -zxvf elasticsearch-5.4.3.tar.gz -C /bigdata
(5)、修改配置文件
进入到es安装目录下的config文件夹中,修改elasticsearch.yml 文件
扩展:
YML文件格式是YAML (YAML Aint Markup Language)编写的文件格式,YAML是一种直观的能够被电脑识别的的数据数据序列化格式,并且容易被人类阅读,容易和脚本语言交互的。
它的基本语法规则如下。
| 大小写敏感 使用缩进表示层级关系 缩进时不允许使用Tab键,只允许使用空格。 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可 # 表示注释,从这个字符一直到行尾,都会被解析器忽略
|
修改的主要内容:
| #配置es的集群名称,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。 cluster.name: shly #节点名称 node.name: node-1 #设置索引数据的存储路径 path.data: /bigdata/servers/data #设置日志的存储路径 path.logs: /bigdata/servers/logs #设置当前的ip地址,通过指定相同网段的其他节点会加入该集群中 network.host: 192.168.17.134 #设置对外服务的http端口 http.port: 9200 #设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点 discovery.zen.ping.unicast.hosts: ["node-1","node-2","node-3"] |
(6)、创建用户
useradd shly
(7)、赋予权限
Chown -R shly:shly /bigdata
(8)、在非root用户下运行es
bigdata/elasticsearch-5.4.3/bin/elasticsearch -d
#出现错误
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法:
#用户最大可创建文件数太小
sudo vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
#查看可打开文件数量
ulimit -Hn
#最大虚拟内存太小
sudo vi /etc/sysctl.conf
vm.max_map_count=262144
#查看虚拟内存的大小
sudo sysctl -p
(9)、使用scp拷贝到其他节点
scp -r /bigdata/elasticsearch-5.4.3 root@node-2:/bigdata/elasticsearch-5.4.3
scp -r /bigdata/elasticsearch-5.4.3 root@node-3:/bigdata/elasticsearch-5.4.3
(10)、非root用户下启动es
每台机器都起:/bigdata/elasticsearch-5.4.3/bin/elasticsearch -d
(11)、非root用户下启动es
用浏览器访问es所在机器的9200端口
http://192.168.17.134:9200/

1.2 kibana安装部署
(1)、下载安装包
访问elasticSearch官网地址 https://www.elastic.co/
(2)、规划安装目录
(3)、上传安装包到指定目录
(4)、解压安装包
tar -zxvf kibana-5.4.3-linux-x86_64.tar.gz -C /bigdata
(5)、修改配置文件
进入到kibana安装目录下的config文件夹中,修改kibana.yml 文件
| server.host: "node1" elasticsearch.url: "http://node-1:9200" |
(6)、授权
chown -R shly:shly /bigdata
- 、启动kibana
nohup /bigdata/kibana-5.4.3-linux-x86_64/bin/kibana
(8)、访问kibana界面
http://node-1:5601
1.3 logstash安装部署
(1)、下载安装包
访问elasticSearch官网地址 https://www.elastic.co/
(2)、规划安装目录
(3)、上传安装包到指定目录
(4)、解压安装包
tar -zxvf logstash-5.4.3.tar.gz -C /bigdata
(5)、重命名安装目录
mv logstash-6.1.1 logstash
logstash入门案例
Logstash 提供了一个 shell 脚本叫 logstash 方便快速运行,-e意指执行
| bin/logstash -e 'input { stdin { } } output { stdout {} }' |
I love you(输入)经过 Logstash 管道(过滤)变成:
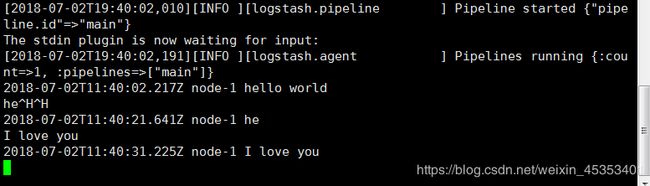
2018-07-02T11:40:31.225Z node-1 I love you(输出)。
/bigdata/logstash-5.4.3/bin/logstash -f /bigdata/test/logstash-sample.conf --config.reload.automatic &
1.4 elasticsearch-head安装部署
git clone git://github.com/mobz/elasticsearch-head.git
#将源码包下载后剪切到/bigdata目录,并改所属用户和组
sudo chown -R xiaoniu:xiaoniu /bigdata/elasticsearch-head
#进入到elasticsearch-head中
cd elasticsearch-head
#编译安装
npm install
打开elasticsearch-head-master/Gruntfile.js,找到下面connect属性,新增hostname: '0.0.0.0',
connect: {
server: {
options: {
hostname: '0.0.0.0',
port: 9100,
base: '.',
keepalive: true
}
}
}
编辑elasticsearch-5.4.3/config/elasticsearch.yml,加入以下内容:
http.cors.enabled: true
http.cors.allow-origin: "*"
#运行服务
npm run start
访问es-head:http://192.168.17.135:9100/

1.5 IK分词器安装部署
下载对应版本的插件
https://github.com/medcl/elasticsearch-analysis-ik/releases
首先下载es对应版本的ik分词器的zip包,上传到es服务器上,在es的安装目录下有一个plugins的目录,在这个目录下创建一个叫ik的目录
然后将解压好的内容,拷贝到ik目录
将ik目录拷贝到其他的es节点
重新启动所有的es
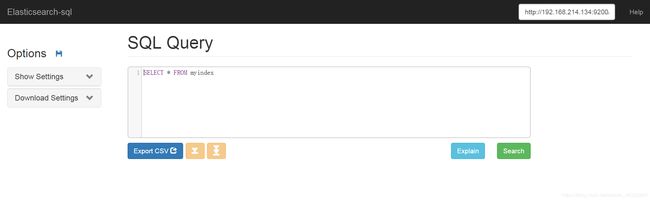
1.6 ES SQL安装部署
./bin/elasticsearch-plugin install https://github.com/NLPchina/elasticsearch-sql/releases/download/5.4.3.0/elasticsearch-sql-5.4.3.0.zip
#然后将解压到plugins目录下的内容拷贝到其他es的节点的plugins目录
1.7 SQL的Server安装部署
wget https://github.com/NLPchina/elasticsearch-sql/releases/download/5.4.1.0/es-sql-site-standalone.zip
用npm编译安装
unzip es-sql-site-standalone.zip
cd site-server/
npm install express --save
修改SQL的Server的端口(我修改为9998)
vi site_configuration.json
启动服务
node node-server.js &
访问http://192.168.17.135:9998/