CVPR 2020 | 旷视研究院提出新方法,优化解决遮挡行人重识别问题

IEEE国际计算机视觉与模式识别会议 CVPR 2020 (IEEE Conference on Computer Vision and Pattern Recognition) 将于 6 月 14-19 日在美国西雅图举行。近日,大会官方论文结果公布,旷视研究院 16 篇论文被收录,研究领域涵盖物体检测与行人重识别(尤其是遮挡场景),人脸识别,文字检测与识别,实时视频感知与推理,小样本学习,迁移学习,3D感知,GAN与图像生成,计算机图形学,语义分割,细粒度图像等众多领域,取得多项领先的技术研究成果,这与即将开源的旷视AI平台Brain++密不可分。
本文是旷视CVPR2020论文系列解读第 3 篇,为了获得遮挡ReID更加鲁棒的对齐能力,本文提出了一种新的框架,来学习具有判别力特征和人体拓扑信息的高阶关系。

论文名称:High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification
论文链接:https://arxiv.org/abs/2003.08177
目录
导语
简介
方法
语义特征提取
高阶关系学习
高阶人体拓扑学习
推理与训练
实验
遮挡(Occluded)数据集结果
半身(Partial)数据集结果
全身(Holistic)数据集结果
结论
参考文献
往期解读
导语
行人重识别(ReID)任务的目标是去匹配不同摄像机拍摄到的同一个人的图像,它广泛应用于视频分析、智慧城市等领域。虽然人们近来提出了多种针对ReID的方法,然而,它们大多侧重于人的全身图像,忽略了更具挑战性且也是实际应用中经常出现的行人遮挡问题。
如图1所示,人们很容易会被一些障碍物(如行李、柜台、人群、汽车、树木)遮挡,或者由于部分身体走出了摄像机拍摄区域而造成遮挡。因此,有必要去准确匹配只具有局部可观测的行人图片,这就是所谓的遮挡行人重识别(Occluded Person Re-Identification)问题。
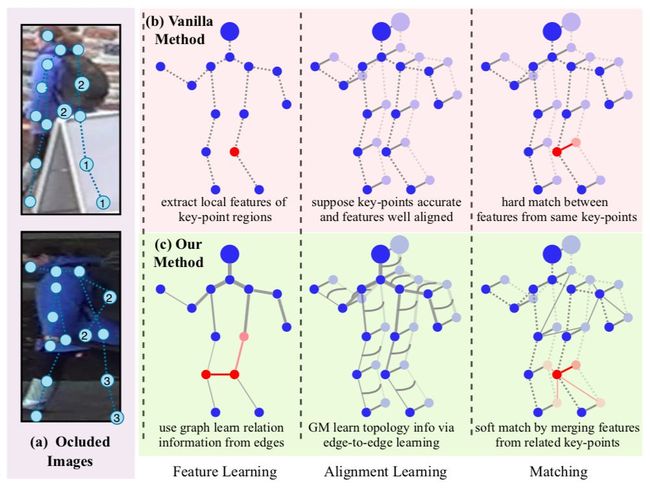
图1:使用高阶信息来解决遮挡行人重识别
与匹配出现人整体信息的情况相比,遮挡情况下的ReID更具挑战性,原因如下:(1)在遮挡区域中,图像包含的辨别信息较少,使得更容易被匹配到错误的人身上去。(2) 基于身体部位之间的特征信息做匹配虽然有效,但需要事先进行严格的人体对齐,因此遮挡严重时效果不佳。
近年来,人们提出了许多针对遮挡或具体部位的ReID方法,然而大多数只考虑了特征学习和对齐的一阶信息。本文认为,除此之外,高阶信息同样应被考虑,且可能会使遮挡ReID问题得到更好的解决。
在图1(a)中,可以看到关键点信息会受遮挡(1, 2)和异常值(3)所影响。比如,关键点1和2被遮挡,导致无意义特征;关键点3是异常值,导致对其偏差。
图1(b)展示的是一个常见的解决方案。它提取关键点区域的局部特征,并假设所有关键点准确且局部特征对齐良好。在这里,所有三个阶段(特征提取、对齐、匹配)都依赖于关键点的一阶信息,鲁棒性不强。
简介
在本文方法中,如1(c)所示,旷视研究院提出了一个新的框架,用于更具判别力的特征学习和鲁棒的特征对齐。在特征学习阶段,研究员通过将一张图像的一组局部特征视为图(graph)的节点(node)来学习关系信息。通过在图中传递信息,因关键点被遮挡而导致的无意义特征问题,可以通过其相邻的有意义的特征进行改善。
在对齐阶段,研究员使用图匹配算法(graph matching)来学习鲁棒的对齐能力。这种方法除了能用点到点的对应关系进行对齐外,它还能对边到边的对应关系进行建模。然后,通过构造一个跨图像的图,我们可以将对齐信息嵌入进特征。正因如此,异常关键点的特征才能通过其在另一幅图像上的相应特征来修复。最后,在验证损失的监督下,研究人员用网络来学习相似度,而不是使用预先定义的距离来计算相似度。
具体地说,为了解决行人重识别场景下的遮挡问题,旷视研究院提出了一个新的框架来联合建模高阶关系和人体拓扑信息。如图2所示,本工作框架包括三个模块,一阶语义模块(S)、高阶关系模块(R)和高阶人体拓扑模块(T)。
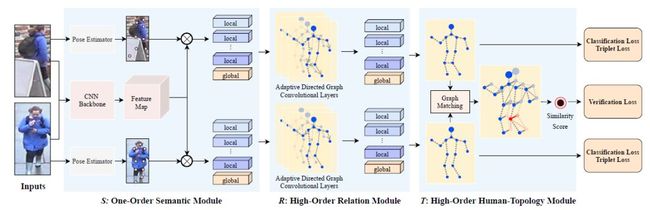
图2:本文方法总体架构
(1) 在S中,首先利用CNN backbone学习特征图,用人体关键点估计模型来学习关键点,然后,提取对应关键点的语义信息;
(2)在R中,人们将习得的图像语义特征看作图的节点,然后提出了一个方向自适应的图卷积层(ADGC/Adaptive-Direction Graph Convolutional)层来学习和传递边缘特征信息。ADGC层可以自动决定每个边的方向和度。从而促进语义特征的信息传递,抑制无意义和噪声特征的传递。最后,学习到的节点包含语义和关系信息。
(3) 在T中,提出一个跨图嵌入对齐(CGEA/cross-graph embedded-alignment)层。它以两个图(graph)作为输入,利用图匹配策略学习其之间节点的对应关系,然后将学习到的对应关系视为邻接矩阵来传递信息。正因如此,相关联的特征才能被增强,对齐信息才能被嵌入到特征中去。最后,为了避免强行一对一对齐的情况,研究员会通过将两个图映射到到一个logit模型并用一个验证损失进行监督来预测其相似性。
方法
旷视研究院提出的框架,包括一个一阶语义模块(S),它可以取人体关键点区域的语义特征;一个高阶关系模块(R),它能对不同语义局部特征之间的关系信息进行建模;一个高阶人类拓扑模块(T),它可以学习到鲁棒的对齐能力,并预测两幅图像之间的相似性。这三个模块以端到端的方式进行联合训练。图2展示了方法的总体框架。
语义特征提取
该模块的目标是提取关键点区域的一阶语义特征。这样做是因为,很多方法已经证明,基于身体局部的特征表示对行人重识别是有效的;其次,局部特征的准确对齐对于针对遮挡或具体部位的ReID也是必要的。
在上述思想,与近来行人重识别、人体关键点预测研究的启发下,研究员利用一个卷积神经网络来提取不同关键点的局部特征。需要注意的是,虽然人体关键点预测已经能够达到很高的精度,但他们依然会因为画面中存在遮挡和只出现部分身体而性能依然不佳,导致关键点的位置和其置信度不准确。因此,才需要接下来的两个模块。
高阶关系学习
虽然通过语义特征提取能够获得不同关键点区域的一阶语义信息,但是这依然无法应对由于行人画面不完整所带来的被遮挡ReID问题。为了获取更具判别力的特征,研究人员引入了图神经网络(GCN)方法来建模高阶关系信息。
在GCN中,不同关键点区域的语义特征被视为节点。通过在节点之间传递信息,一阶语义信息(节点特征)和高阶特征(边特征)都可以被照顾到。虽然如此,被遮挡的ReID还是存在一个问题,即被遮挡区域的特征经常是无意义甚至噪声干扰。当在这些特征再图中进行传递时,甚至可能带来更多噪声,对被遮挡ReID产生副作用。
因此,研究员新提出了一个方向自适应的图卷积层ADGC,用它来动态学习信息传递的方向和degree。借助它,研究员可以自动抑制无意义特征信息,促进有效语义特征信息的传递。
给出两张行人图片(x1,x2),它们基于关系信息相似度可以由公式6计算。K是关键点个数,\beta是对应人体关键关键点的置信度,v经过高阶关系学习优化后,对应的关键点的特征。
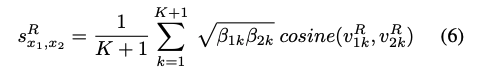
高阶人体拓扑学习
在基于身体部位的特征表示已经被证明对行人重识别是有效的。一种简单的对齐策略是直接去匹配同样关键点之间的特征。然而这种一阶对齐策略并不能应对异常值,特别是当画面人物有大面积遮挡的情况。
相反,图匹配策略(graph matching)可以自然地将人体拓扑的高阶信息也考虑进去。但它只能学习一对一的对应关系,导致这种硬对齐策略对于异常值仍然十分敏感,性能容易受到干扰。为此,研究员提出了一个跨图的嵌入对齐层,它不仅能够充分利用经图匹配算法习得的人体拓扑信息,还能避免来自一对一对齐的干扰。
给出两张行人图片(x1,x2),它们的基于人体拓扑信息的相似度可以由公(式1)0计算。V是经过高阶人体拓扑学习优化后的所有特征的连接,f是一个全连接层,\sigma 是sigmoid激活函数。
![]()
训练与推理
在训练阶段,本文框架的总体目标函数为:

其中λ代表对应项的权重。研究人员通过最小化L来对框架进行端到端训练。
对于相似度计算,给定一对图像(x1,x2),人们可以由公式6计算出的相似度![]() 以得到其之间的关系信息,由公式10得到的相似度
以得到其之间的关系信息,由公式10得到的相似度![]() 得到拓扑结构信息。在计算最终相似度时,可以结合这两个相似度来计算。
得到拓扑结构信息。在计算最终相似度时,可以结合这两个相似度来计算。

在推理阶段,给定一张查询图像x_q,首先计算其与库中所有图像的相似度x^R,得到分数最高的n张,然后用公式13计算最终的相似度 s以修正这n张图片的选择。征表示为图的节点,并提出了一种自适应方向图卷积(ADGC)层,以促进语义特征的信息传递,抑制无意义和噪声特征的信息传递。
为了学习拓扑信息,旷视研究院提出了一种具有验证损失的交叉图嵌入对齐(CGEA)层,它可以避免敏感的硬一对一对齐,并执行鲁棒的软对齐。最后,在封闭、平行和整体数据集上的大量实验证明了旷视研究院提出的框架的有效性。
实验
遮挡(Occluded)数据集结果
研究人员用本文框架在在两个遮挡数据集(Occluded-Duke and Occluded-ReID)上进行了实验。通过和另外4种方法(vanilla holistic ReI]、 holistic ReID methods with key-points information]、partial ReI]、occluded ReI])进行性能对比,结果如表2所示。
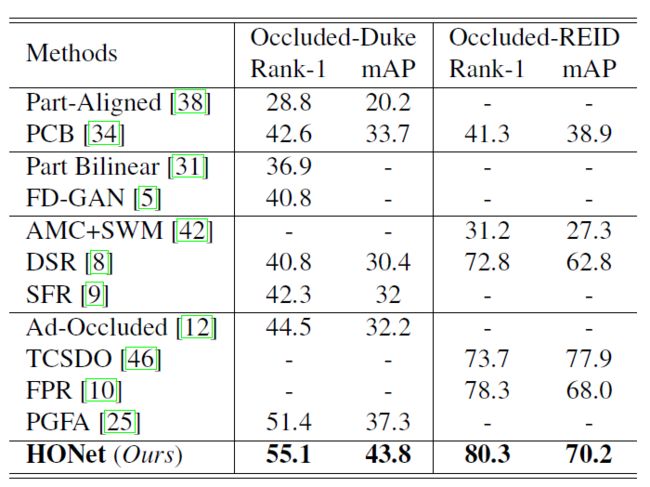
表2 在遮挡(occluded)数据集上的实验结果
可以发现本文提出的框架 HONet 分别在Occluded- Duke和Occluded-ReID上取得了Rank-1 55.1%和80.4%的最佳性能,证明了方法的有效性。
另外,vanilla holistic ReID和holistic ReID methods with key-points information的效果并没有明显差异,这意味着仅仅基于关键点信息并不能在被遮挡ReID任务上取得很好效果。相反,对于partial ReID和occluded ReID方法来说,它们在被遮挡数据集上取得了显著效果。这也说明,这两种ReID方法在学习有判别力度的特征和进行特征对齐时有类似的问题。
半身(Partial)数据集结果
在实际应用中,被遮挡和出现部分身体的情况经常发生,所以为了进一步测试本文框架性能,研究人员也在两个partial 数据集(Partial-REID,Partial-iLIDS)上进行了实验。需要说明的是,由于这两个数据集太小,所以研究人员用Market-1501作为训练集,将这两个数据集作为测试集。从结果可以看到,本文提出的框架显著超越了其他方法。
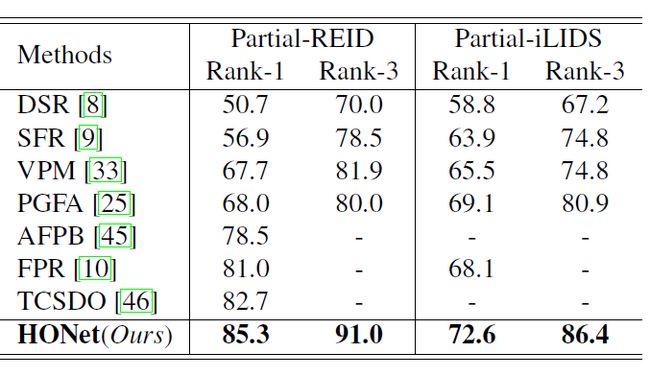
表3:在半身(partial)数据集上的实验结果
全身(Holistic)数据集结果
虽然近来的针对遮挡或具体身体部位的ReID方法取得了一定成果,但是它们却在出现整体人体(holistic)的数据集上表现不佳。这是因为特征训练和对齐时有噪声干扰。为此,研究人员也将本文方法在两个holistic数据集(Market-1501和DuekMTMTC-reID)上进行了实验。

表4:在全身(holistic)数据集上的实验结果
通过与3种vanilla ReID方],3种基于human-parsing信息的ReID方],以及4种基于关键点信息的ReID方]的性能对比,见表4。
可以发现3种vanilla ReID方法性能表现相当,而使用human-parsing和关键点这些外部信息的方法表现较差。这说明简单地利用这些外部信息可能不会让模型的性能在holistic数据集上有所改善。这是因为holistic ReID数据集中大部分的图像都能被很好地检测,vanilla holistic ReID方法足以学习到具有判别力的特征。
最后,由于本文提出的ADGC层可以抑制噪声特征,CGEA层可以避免僵硬的一对一对齐,所以能够发现框架在这两个holistic ReID数据集上也取得了颇具竞争力的性能表现。
结论
为了获得鲁棒的对齐能力,本文提出了一种新的框架,来学习具有判别力特征和人体拓扑信息的高阶关系。为了学习关系信息,旷视研究院将图像的局部特征表示为图(graph)的节点(node),并提出了一种自适应方向图卷积(ADGC)层来促进语义特征的信息传递,抑制无意义和噪声特征的信息传递。
对于学习拓扑信息,研究人员提出了跨图(graph)的嵌入对齐层(CGEA),它以两个图(graph)作为输入,利用图匹配策略学习其之间节点的对应关系,然后将学习到的对应关系视为邻接矩阵来传递信息。它可以避免敏感地硬一对一对齐,并执行鲁棒的软对齐。最后,在occluded、partial和holistic三种数据集上进行的大量实验证明了本文提出的框架的有效性。
入群交流
欢迎加入旷视人脸识别技术交流群

或添加微信farman7230入群
参考文献
Shaogang Gong, Marco Cristani, Shuicheng Yan, and Chen Change Loy. Person Re-Identification. 2014.
Liang Zheng, Yi Yang, and Alexander G Hauptmann. Per- son re-identification: Past, present and future. arXiv preprint arXiv:1610.02984, 2016.
Jiaxuan Zhuo, Zeyu Chen, Jianhuang Lai, and Guangcong Wang. Occluded person re-identification. In 2018 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2018.
Jiaxu Miao, Yu Wu, Ping Liu, Yuhang Ding, and Yi Yang. Pose-guided feature alignment for occluded person re-identification. In ICCV, 2019.
Lingxiao He, Jian Liang, Haiqing Li, and Zhenan Sun. Deep spatial feature reconstruction for partial person re- identification: Alignment-free approach. pages 7073–7082, 2018.
Lingxiao He, Yinggang Wang, Wu Liu, Xingyu Liao, He Zhao, Zhenan Sun, and Jiashi Feng. Foreground-aware pyra- mid reconstruction for alignment-free occluded person re- identification. arXiv: Computer Vision and Pattern Recogni- tion, 2019.
往期解读
CVPR2020 | 旷视研究院提出PVN3D:基于3D关键点投票网络的单目6DoF位姿估计算法
CVPR2020 | 旷视研究院提出SAT:优化解决半监督视频物体分割问题
传送门
欢迎大家关注如下 旷视研究院 官方微信号????
