手把手教你用Python实现决策树模型
本文始发于个人公众号:TechFlow,原创不易,求个关注
今天是机器学习专题的第21篇文章,我们一起来看一个新的模型——决策树。
决策树的定义
决策树是我本人非常喜欢的机器学习模型,非常直观容易理解,并且和数据结构的结合很紧密。我们学习的门槛也很低,相比于那些动辄一堆公式的模型来说,实在是简单得多。
其实我们生活当中经常在用决策树,只是我们自己没有发现。决策树的本质就是一堆if-else的组合,举个经典的例子,比如我们去小摊子上买西瓜。水果摊的小贩都是怎么做的?拿起西瓜翻滚一圈,看一眼,然后伸手一拍,就知道西瓜甜不甜。我们把这些动作相关的因素去除,把核心本质提取出来,基本上是这么三条:
- 西瓜表面的颜色,颜色鲜艳的往往比较甜
- 西瓜拍打的声音,声音清脆的往往比较甜
- 西瓜是否有瓜藤,有藤的往往比较甜
这三条显然不是平等的,因为拍打的声音是最重要的,可能其次表面颜色,最后是瓜藤。所以我们挑选的时候,肯定也是先听声音,然后看瓜藤,最后看颜色。我们把其中的逻辑抽象出来然后整理一下,变成一棵树结构,于是这就成了决策树。
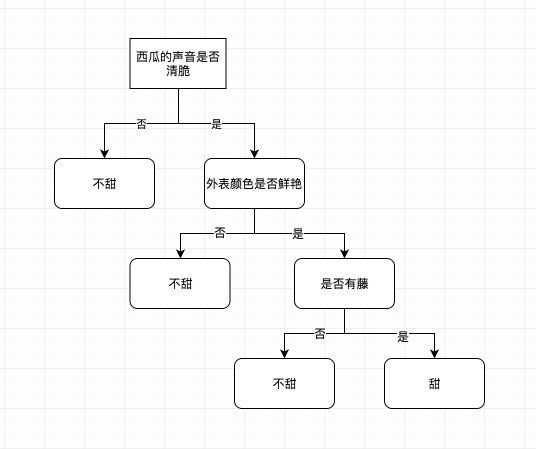
这个决策树本质上做的还是分类的工作,将西瓜分成了甜的和不甜的。也就是说决策树是一个树形的分类器,这个也是决策树的基本定义。另外从图中我们还有一个启示,在这个问题当中,决策树的特征都是离散值,而不是连续值。也就是说决策树可以接受像是类别、标识这样非数值型的特征,而逻辑回归这些模型则不太行。
如果你对这些细节还理解不深刻也没有关系,我们可以先放一放,至少我们明白了决策树的大概结构以及工作原理。
对于每一条数据来说,它分类的过程其实就是在决策树上遍历的过程。每到一个中间节点都会面临一次判断,根据判断的结果选择下一个子树。而树上的叶子节点代表一种分类,当数据到了叶子节点,这个叶子节点的值就代表它的分类结果。
决策树的训练
明白了决策树的结构和工作原理之后,下面就是训练的过程了。
在理清楚原理之前,我们先来看下数据。我们根据上面决策树的结构,很容易发现,训练数据应该是这样的表格:
| 分类 | 声音是否清脆 | 是否有瓜藤 | 是否有光泽 |
|---|---|---|---|
| 甜 | 是 | 是 | 是 |
| 甜 | 是 | 是 | 否 |
| 不甜 | 否 | 否 | 是 |
| 不甜 | 否 | 否 | 否 |
那么最后我们想要实现什么效果呢?当然是得到的准确率越高越好,而根据决策树的原理,树上的每一个叶子节点代表一个分类。那么我们显然希望最后到达叶子节点的数据尽可能纯粹,举个例子,如果一个叶子节点代表甜,那么我们肯定希望根据树结构被划归到这里的数据尽可能都是甜的,不甜的比例尽可能低。
那么我们怎么实现这一点呢?这就需要我们在越顶层提取规则的时候,越选择一些区分度大的特征作为切分的依据。所谓区分度大的特征,也就是能够将数据很好分开的特征。这是明显的贪心做法,使用这样的方法,我们只可以保证在尽可能高层取得尽可能好的分类结果,但是并不能保证这样得到的模型是最优的。生成最优的决策树本质上也是一个NP问题,我们当前的做法可以保证在尽量短的时间内获得一个足够优秀的解,但是没办法保证是最优解。
回到问题本身,我们想要用区分度大的特征来进行数据划分。要做到这一点的前提就是首先定义区分度这个概念,将它量化,这样我们才好进行选择。否则总不能凭感觉去衡量区分度,好在这个区分度还是很好解决的,我们只需要再一次引入信息熵的概念就可以了。
信息熵与信息增益
信息熵这个词很令人费解,它英文原文是information entropy,其实一样难以理解。因为entropy本身是物理学和热力学当中的概念,用来衡量物体分散的不均匀程度。也就是说熵越大,说明物体分散得程度越大,可以简单理解成越散乱。比如我们把房间里一盒整理好的乒乓球打翻,那么里面的乒乓球显然会散乱到房间的各个地方,这个散乱的过程可以理解成熵增大的过程。
信息熵也是一样的含义,用来衡量一份信息的散乱程度。熵越大,说明信息越杂乱无章,否则说明信息越有调理。信息熵出自大名鼎鼎的信息学巨著《信息论》,它的作者就是赫赫有名的香农。但是这个词并不是香农原创,据说是计算机之父冯诺依曼取的,他去这个名字的含义也很简单,因为大家都不明白这个词究竟是什么意思。
之前我们曾经在介绍交叉熵的时候详细解释过这个概念,我们来简单回顾一下。对于一个事件X来说,假设它发生的概率是P(X),那么这个事件本身的信息量就是:
I ( X ) = − l o g 2 P ( X ) I(X) = -log_2P(X) I(X)=−log2P(X)
比如说世界杯中国队夺冠的概率是1/128,那么我们需要用8个比特才能表示,说明它信息量很大。假如巴西队夺冠的概率是1/4,那么只要2个比特就足够了,说明它的信息量就很小。同样一件事情,根据发生的概率不同,它的信息量也是不同的。
那么信息熵的含义其实就是信息量的期望,也就是用信息量乘上它的概率:
H ( X ) = − P ( X ) l o g 2 P ( X ) H(X) = -P(X)log_2P(X) H(X)=−P(X)log2P(X)
同样,假设我们有一份数据集合,其中一共有K类样本,每一类样本所占的比例是 P ( K ) P(K) P(K),那么我们把这个比例看成是概率的话,就可以写出这整个集合的信息熵:
H ( D ) = − ∑ i = 1 K P ( K ) l o g 2 ( P ( K ) ) H(D)=-\sum_{i=1}^K P(K)log_2(P(K)) H(D)=−i=1∑KP(K)log2(P(K))
理解了信息熵的概念之后,再来看信息增益就很简单了。信息增益说白了就是我们划分前后信息熵的变化量,假设我们选择了某一个特征进行切分,将数据集D切分成了D1和D2。那么 H ( D ) − ( H ( D 2 ) + H ( D 1 ) ) H(D) - (H(D_2) + H(D_1)) H(D)−(H(D2)+H(D1))就叫做信息增益,也就是切分之后信息熵与之前的变化量。
我们根据熵的定义可以知道,如果数据变得纯粹了,那么信息熵应该会减少。减少得越多,说明切分的效果越好。所以我们就找到了衡量切分效果的方法,就是信息增益。我们根据信息增益的定义,可以很简单地理出整个决策树建立的过程。就是我们每次在选择切分特征的时候,都会遍历所有的特征,特征的每一个取值对应一棵子树,我们通过计算信息增益找到切分之后增益最大的特征。上层的结构创建好了之后, 通过递归的形式往下继续建树,直到切分之后的数据集变得纯粹,或者是所有特征都使用结束了为止。
这个算法称为ID3算法,它也是决策树最基础的构建算法。这里有一个小细节, 根据ID3算法的定义,每一次切分选择的是特征,而不是特征的取值。并且被选中作为切分特征的特征的每一个取值都会建立一棵子树,也就是说每一个特征在决策树当中都只会最多出现一次。因为使用一次之后,这个特征的所有取值就都被使用完了。
举个例子,比如拍打声音是否清脆这个特征,我们在一开始就选择了它。根据它的两个取值,是和否都建立了一棵子树。那么如果我们在子树当中再根据这个特征拆分显然没有意义,因为子树中的所有数据的这个特征都是一样的。另外,ID3算法用到的所有特征必须是离散值,因为连续值无法完全切分。如果西瓜的重量是一个特征,那么理论上来说所有有理数都可能是西瓜的质量,我们显然不可能穷尽所有的取值。
这一点非常重要,不仅关系到我们实现的决策树是否正确,也直接关系到我们之后理解其他的建树算法。
代码实现
理解了算法原理和流程之后,就到了我们紧张刺激的编码环节。老实讲决策树的算法实现并不难,比之前的FP-growth还要简单,大家不要有压力。
首先,我们来创造实验数据:
import numpy as np
import math
def create_data():
X1 = np.random.rand(50, 1)*100
X2 = np.random.rand(50, 1)*100
X3 = np.random.rand(50, 1)*100
def f(x):
return 2 if x > 70 else 1 if x > 40 else 0
y = X1 + X2 + X3
Y = y > 150
Y = Y + 0
r = map(f, X1)
X1 = list(r)
r = map(f, X2)
X2 = list(r)
r = map(f, X3)
X3 = list(r)
x = np.c_[X1, X2, X3, Y]
return x, ['courseA', 'courseB', 'courseC']
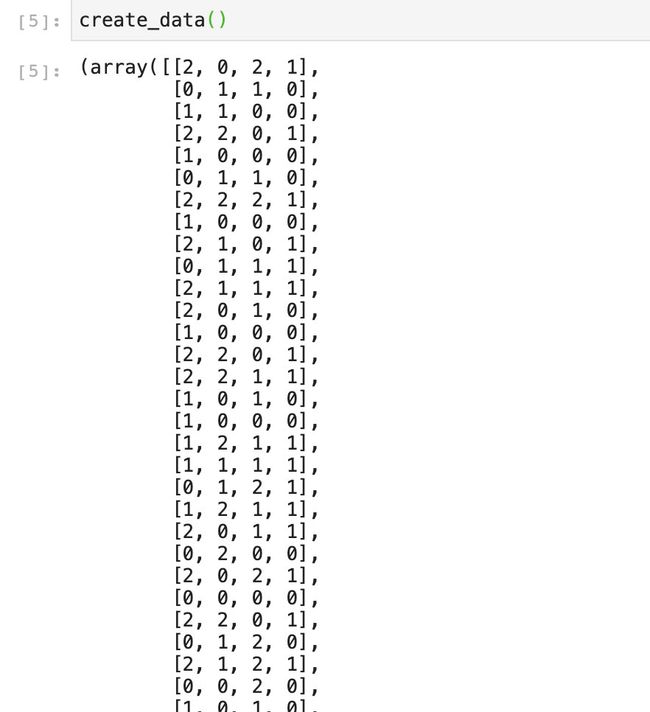
这份数据模拟的是学生考试,一共考三门,一共要考到150分以上才算是通过。由于ID3算法只能接受离散值的特征,所以我们要先将连续值转成离散值,我们根据每一门的考试分数,生成三个档次。大于70分的是2档,40到70分的是1档,小于40分的是0档。
为了方便编码,我们把预测值Y放在特征的最后,并且返回这三个特征的名称,方便以后用来建树。
我们运行一下数据查看一下结果:
下面,我们实现计算集合信息熵的函数。这个函数也很简单,我们只需要计算出每个类别的占比,然后套用一下信息熵的公式即可。
from collections import Counter
def calculate_info_entropy(dataset):
n = len(dataset)
# 我们用Counter统计一下Y的数量
labels = Counter(dataset[:, -1])
entropy = 0.0
# 套用信息熵公式
for k, v in labels.items():
prob = v / n
entropy -= prob * math.log(prob, 2)
return entropy
有了信息熵的计算函数之后,我们接下来实现拆分函数,也就是根据特征的取值将数据集进行拆分的函数。
def split_dataset(dataset, idx):
# idx是要拆分的特征下标
splitData = defaultdict(list)
for data in dataset:
# 这里删除了idx这个特征的取值,因为用不到了
splitData[data[idx]].append(np.delete(data, idx))
return list(splitData.values()), list(splitData.keys())
本质上就是根据特征取值归类的过程,我们可以随便调用测试一下:
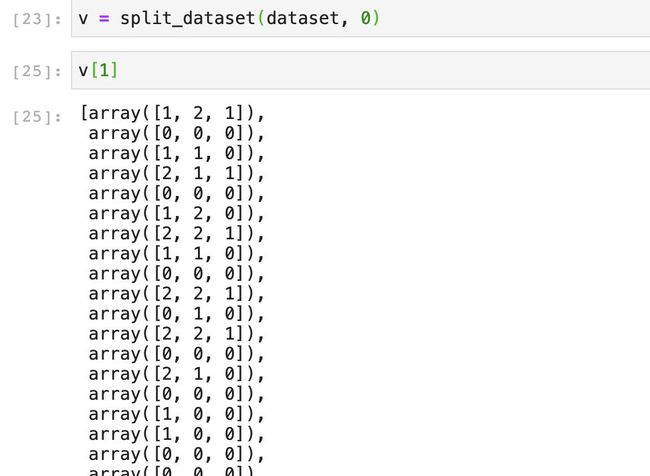
和我们预期一样,根据特征的取值将数据分成了若干份。接下来我们就要实现核心的特征的选择函数了,也就是要选择信息增益最大的特征对数据进行切分。
def choose_feature_to_split(dataset):
n = len(dataset[0])-1
m = len(dataset)
# 切分之前的信息熵
entropy = calculate_info_entropy(dataset)
bestGain = 0.0
feature = -1
for i in range(n):
# 根据特征i切分
split_data, _ = split_dataset(dataset, i)
new_entropy = 0.0
# 计算切分后的信息熵
for data in split_data:
prob = len(data) / m
new_entropy += prob * calculate_info_entropy(data)
# 获取信息增益
gain = entropy - new_entropy
if gain > bestGain:
bestGain = gain
feature = i
return feature
到这里,我们所有工具方法都已经开发完了,下面就到了我们紧张刺激的建树部分了。建树其实并没有什么大不了的,无非是通过递归来重复调用上面的方法来创造每一个分支节点而已。如果你熟悉树形数据结构,会发现它和其他树形数据结构的构建过程并没有什么两样。
我们来看下代码,整个过程也只有十几行而已。
def create_decision_tree(dataset, feature_names):
dataset = np.array(dataset)
counter = Counter(dataset[:, -1])
# 如果数据集值剩下了一类,直接返回
if len(counter) == 1:
return dataset[0, -1]
# 如果所有特征都已经切分完了,也直接返回
if len(dataset[0]) == 1:
return counter.most_common(1)[0][0]
# 寻找最佳切分的特征
fidx = choose_feature_to_split(dataset)
fname = feature_names[fidx]
node = {fname: {}}
feature_names.remove(fname)
# 递归调用,对每一个切分出来的取值递归建树
split_data, vals = split_dataset(dataset, fidx)
for data, val in zip(split_data, vals):
node[fname][val] = create_decision_tree(data, feature_names[:])
return node
我们运行一下这段代码,会得到一份dict,这个dict当中的层次结构其实就是决策树的结构:

我们这样看可能不太清楚,但是我们把这个dict展开就得到了下图的这棵树结构:

我们观察一下上图当中红圈的部分,这个节点只有两个分叉,而其他的节点都有三个分叉。这并不是代码有bug,而是说明数据当中缺失了这种情况,所以少了一个分叉。这其实非常正常,当我们训练数据的样本量不够的时候,很有可能无法覆盖所有的情况,就会出现这种没有分叉的情况。
到这里虽然决策树是实现完了,但是还没有结束,还有一个关键的部分我们没有做,就是预测。我们训练完了,总得把模型用起来,显然需要一个预测的函数。这个预测的函数也简单,它介绍一条数据以及我们训练完的树结构,返回分类的结果。其实也是一个递归调用的过程:
def classify(node, feature_names, data):
# 获取当前节点判断的特征
key = list(node.keys())[0]
node = node[key]
idx = feature_names.index(key)
# 根据特征进行递归
pred = None
for key in node:
# 找到了对应的分叉
if data[idx] == key:
# 如果再往下依然还有子树,那么则递归,否则返回结果
if isinstance(node[key], dict):
pred = classify(node[key], feature_names, data)
else:
pred = node[key]
# 如果没有对应的分叉,则找到一个分叉返回
if pred is None:
for key in node:
if not isinstance(node[key], dict):
pred = node[key]
break
return pred
我们来创造一些简单的数据测试一下:


基本上和我们的预期一致,说明我们决策树就实现完了。
总结
我们的决策树虽然构建完了,但是仍然有很多不完美的地方。比如说,目前我们的模型只能接受离散值的特征,如果是连续值则无法进行拆分。而且我们每个特征只能用一次,有时候我们希望能够多次使用同一个特征。在这种情况下ID3就无法实现了。所以我们还需要引入其他的优化。
在后序的文章当中我们将会讨论这些相关的优化,以及决策树这个模型本身的一些特性。如果对此感兴趣,一定不要错过。
文章就到这里,喜欢的话给个关注呗~
