论文浅尝 | 中科院百度微软等学者最新综述论文40+最新方法阐述知识图谱提升推荐系统准确性与可解释性...
本文转载自公众号:先知。
【导读】近来,知识图谱用于推荐系统是关注的焦点,能够提升推荐系统的准确性与可解释性。如何将知识图谱融入到推荐系统呢? 最近中科院计算所百度微软等学者最新综述论文《A Survey on Knowledge Graph-Based Recommender Systems》,阐述对基于知识图谱的推荐系统进行了系统的研究。

地址:
https://www.zhuanzhi.ai/paper/90d0d696560bc88ea93f629b478a2128
为了解决各种在线应用中的信息爆炸问题,提高用户体验,推荐系统被提出来进行用户偏好建模。尽管人们已经做出了许多努力来实现更加个性化的推荐,但是推荐系统仍然面临着一些挑战,比如数据稀疏性和冷启动。近年来,以知识图谱作为边信息生成推荐引起了人们的极大兴趣。这种方法不仅可以缓解上述问题,提供更准确的推荐,而且可以对推荐的项目进行解释。本文对基于知识图谱的推荐系统进行了系统的研究。我们收集了这一领域最近发表的论文,并从两个角度进行了总结。一方面,我们通过研究论文如何利用知识图谱进行准确和可解释的推荐来研究所提出的算法。另一方面,我们介绍了这些工作中使用的数据集。最后,我们提出了几个可能的研究方向。
概述
随着互联网的快速发展,数据量呈指数级增长。由于信息量过大,用户在众多的选择中很难找到自己感兴趣的。为了提高用户体验,推荐系统已被应用于音乐推荐[1]、电影推荐[2]、网上购物[3]等场景。
推荐算法是推荐系统的核心要素,主要分为基于协同过滤(CF)的推荐系统、基于内容的推荐系统和混合推荐系统[4]。基于CF的推荐基于用户或交互数据项的相似度来建模用户偏好,而基于内容的推荐利用了物品项的内容特征。基于CF的推荐系统得到了广泛的应用,因为它可以有效地捕获用户的偏好,并且可以很容易地在多个场景中实现,而不需要在基于内容的推荐系统[5]、[6]中提取特征。然而,基于CF的推荐存在数据稀疏性和冷启动问题[6]。为了解决这些问题,提出了混合推荐系统来统一交互级相似度和内容级相似度。在这个过程中,我们探索了多种类型的边信息,如项目属性[7]、[8]、项目评论[9]、[10],以及用户的社交网络[11]、[12]。
近年来,将知识图谱(KG)作为边信息引入推荐系统引起了研究者的关注。KG是一个异构图,其中节点作为实体,边表示实体之间的关系。可以将项目及其属性映射到KG中,以了解项目[2]之间的相互关系。此外,还可以将用户和用户端信息集成到KG中,从而更准确地捕捉用户与物品之间的关系以及用户偏好。图1是一个基于KG的推荐示例,其中电影“Avatar”和“Blood Diamond”被推荐给Bob。此KG包含用户、电影、演员、导演和类型作为实体,而交互、归属、表演、导演和友谊是实体之间的关系。利用KG,电影与用户之间存在不同的潜关系,有助于提高推荐的精度。基于知识的推荐系统的另一个优点是推荐结果[14]的可解释性。在同一个示例中,根据user-item图中的关系序列可以知道向Bob推荐这两部电影的原因。例如,推荐《阿凡达》的一个原因是,《阿凡达》与鲍勃之前看过的《星际穿越》属于同一类型。最近提出了多种KGs,如Freebase[15]、DBpedia[16]、YAGO[17]、谷歌的知识图谱[18],方便了KGs的推荐构建。
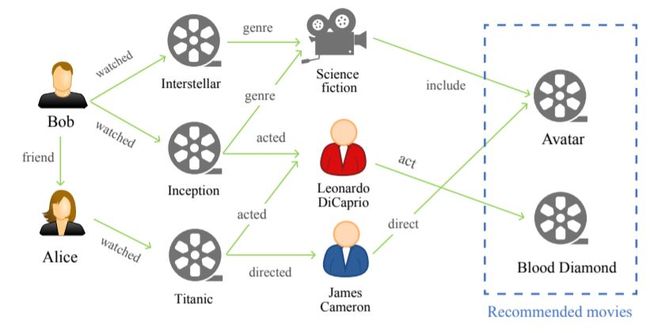
图1 一个基于kg的推荐的例子
本次综述的目的是提供一个全面的文献综述利用KGs作为侧信息的推荐系统。在我们的研究过程中,我们发现现有的基于KG的推荐系统以三种方式应用KGs: 基于嵌入的方法、基于路径的方法和统一的方法。我们详细说明了这些方法的异同。除了更准确的推荐之外,基于KG的推荐的另一个好处是可解释性。我们讨论了不同的作品如何使用KG来进行可解释的推荐。此外,根据我们的综述,我们发现KGs在多个场景中充当了辅助信息,包括电影、书籍、新闻、产品、兴趣点(POIs)、音乐和社交平台的推荐。我们收集最近的作品,根据应用程序对它们进行分类,并收集在这些作品中评估的数据集。
本次综述的组织如下: 在第二部分,我们介绍了KGs和推荐系统的基础;在第3节中,我们介绍了本文中使用的符号和概念;在第4节和第5节中,我们分别从方法和评价数据集的角度对基于知识的推荐系统进行了综述;第六部分提出了该领域的一些潜在研究方向;最后,我们在第7节总结了这次调查。
术语概念
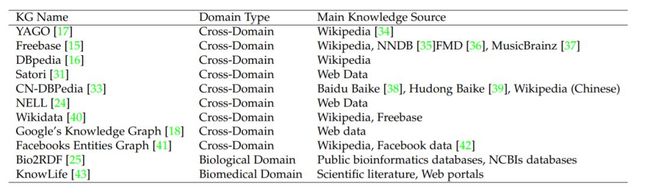 图2 常用知识图谱集合
图2 常用知识图谱集合
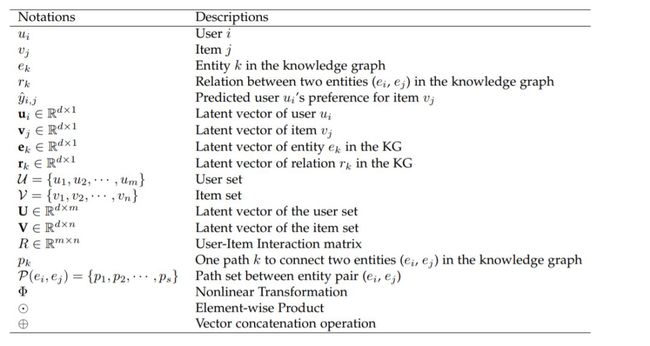 图3 符号
图3 符号
知识图谱推荐系统方法
Embedding-based方法
基于嵌入的方法通常直接使用来自KG的信息来丰富项目或用户的表示。为了利用KG信息,需要使用知识图嵌入(KGE)算法将KG编码为低秩嵌入。KGE算法可分为两类[98]:翻译距离模型,如TransE[99]、TransH[100]、TransR[101]、TransD[102]等;语义匹配模型,如DistMult[103]等。
根据KG中是否包含用户,可以将基于嵌入的方法分为两个类。在第一种方法中,KGs由项目及其相关属性构成,这些属性是从数据集或外部知识库中提取的。我们将这样的图命名为项目图。注意,用户不包括在这样的项目图中。遵循这一策略的论文利用知识图嵌入(KGE)算法对图进行编码,以更全面地表示项目,然后将项目侧信息集成到推荐框架中。其大意可以如下所示。

另一种embedding-based方法直接建立user-item图,用户,项目,以及相关属性函数作为节点。在用户-项目图中,属性级关系(品牌、类别等)和用户级关系(共同购买、共同查看等)都是边。
Path-based Methods
基于路径的方法构建一个用户-项目图,并利用图中实体的连接模式进行推荐。基于路径的方法在2013年就已经开发出来了,传统的论文将这种方法称为HIN中的推荐方法。通常,这些模型利用用户和/或项的连接性相似性来增强推荐。
统一方法
基于嵌入的方法利用KG中用户/项的语义表示进行推荐,而基于路径的方法使用语义连接信息,并且两种方法都只利用图中信息的一个方面。为了更好地利用KG中的信息,提出了将实体和关系的语义表示和连通性信息结合起来的统一方法。统一的方法是基于嵌入传播的思想。这些方法以KG中的连接结构为指导,对实体表示进行细化。
总结:
基于嵌入的方法使用KGE方法对KG(项目图或用户-项目图)进行预处理,以获得实体和关系的嵌入,并将其进一步集成到推荐框架中。然而,这种方法忽略了图中信息的连通性模式,很少有文献能够给出有原因的推荐结果。基于路径的方法利用用户-项图,通过预先定义元路径或自动挖掘连接模式来发现项的路径级相似性。基于路径的方法还可以为用户提供对结果的解释。将基于嵌入的方法与基于路径的方法相结合,充分利用双方的信息是当前的研究趋势。此外,统一的方法还具有解释推荐过程的能力。
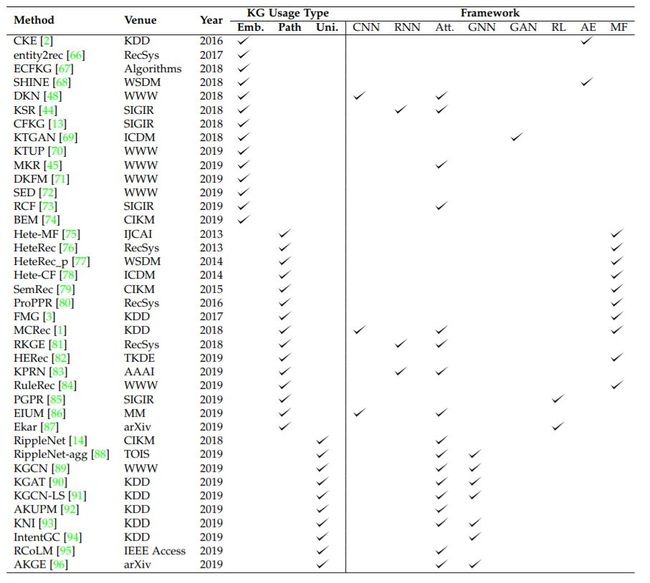 图4 收集论文表。在表格中,Emb代表基于嵌入的方法,Uni代表统一方法,Att’代表注意力机制,’RL’代表强化学习,’AE’代表自动编码器,’MF’代表矩阵分解。
图4 收集论文表。在表格中,Emb代表基于嵌入的方法,Uni代表统一方法,Att’代表注意力机制,’RL’代表强化学习,’AE’代表自动编码器,’MF’代表矩阵分解。
代表数据集
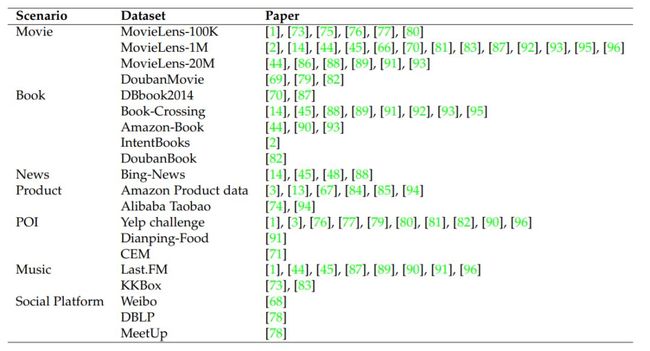 图5 不同应用场景和相应论文的数据集集合
图5 不同应用场景和相应论文的数据集集合
未来方向
在以上几节中,我们从更准确的推荐和可解释性方面展示了基于知识的推荐系统的优势。虽然已经提出了许多利用KG作为侧信息进行推荐的新模型,但仍然存在一些改进的机会。在这一部分中,我们概述并讨论了一些未来的研究方向。
动态推荐。虽然基于KG的推荐系统在GNN或GCN架构下取得了良好的性能,但是训练过程是耗时的。因此,这些模型可以看作是静态的偏好推荐。然而,在某些情况下,如网上购物、新闻推荐、Twitter和论坛,用户的兴趣会很快受到社会事件或朋友的影响。在这种情况下,使用静态偏好建模的推荐可能不足以理解实时兴趣。为了捕获动态偏好,利用动态图网络可以是一个解决方案。最近,Song等[127]设计了一个动态图-注意力网络,通过结合来自朋友的长期和短期兴趣来捕捉用户快速变化的兴趣。按照这种方法,很自然地要集成其他类型的侧信息,并构建一个KG来进行动态推荐。
多任务学习。基于kg的推荐系统可以看作是图中链接预测。因此,考虑到KG的性质,有可能提高基于图的推荐的性能。例如,KG中可能存在缺失的事实,从而导致关系或实体的缺失。然而,用户的偏好可能会被忽略,因为这些事实是缺失的,这可能会恶化推荐结果。[70]、[95]已经证明了联合训练KG完成模块和推荐模块以获得更好的推荐是有效的。其他的工作利用多任务学习,将推荐模块与KGE task[45]和item relation regulation task联合训练[73]。利用从其他kg相关任务(例如实体分类和解析)迁移知识来获得更好的推荐性能,这是很有趣的。
跨域推荐。最近,关于跨域推荐的研究已经出现。其动机是跨域的交互数据不相等。例如,在Amazon平台上,图书评级比其他域更密集。使用迁移学习技术,可以共享来自具有相对丰富数据的源域的交互数据,以便在目标域内进行更好的推荐。Zhang等[128]提出了一种基于矩阵的跨域推荐方法。后来,Zhao等人[129]引入了PPGN,将来自不同领域的用户和产品放在一个图中,并利用user item交互图进行跨领域推荐。虽然PPGN的性能显著优于SOTA,但是user item图只包含交互关系,并不考虑用户和项目之间的其他关系。通过将不同类型的用户和项目端信息合并到用户-项目交互图中,以获得更好的跨域推荐性能。
知识增强语言表示。为了提高各种自然语言处理任务的性能,有将外部知识集成到语言表示模型中的趋势。知识表示和文本表示可以相互细化。例如,Chen等人[130]提出了短文本分类的STCKA,利用来自KGs(如YAGO)的先验知识,丰富了短文本的语义表征。Zhang等人[131]提出了ERNIE,该方法融合了Wikidata的知识,增强了语言的表示能力,该方法已被证明在关系分类任务中是有效的。虽然DKN模型[48]既利用了文本嵌入,也利用了新闻中的实体嵌入,但这两种嵌入方式只是简单地串联起来,得到新闻的最终表现形式,而没有考虑两个向量之间的信息融合。因此,将知识增强的文本表示策略应用于新闻推荐任务和其他基于文本的推荐任务中,能够更好地表示学习,从而获得更准确的推荐结果,是很有前景的。
知识图谱嵌入方法。基于不同约束条件的KGE方法有两种:翻译距离模型和语义匹配模型。在本次综述中,这两种类型的KGE方法被用于三种基于KGE的推荐系统和推荐任务中。但是,还没有全面的工作建议在什么情况下,包括数据源、推荐场景和模型架构,应该采用特定的KGE方法。因此,另一个研究方向是比较不同KGE方法在不同条件下的优势。
用户端信息。目前,大多数基于KG的推荐系统都是通过合并项目侧信息来构建图的,而很少有模型考虑用户侧信息。然而,用户侧信息,如用户网络和用户的人口统计信息,也可以很自然地集成到当前基于KGbased的推荐系统框架中。最近,Fan等人[132]使用GNN分别表示用户-用户社交网络和用户-项目交互图,该方法在用户社交信息方面优于传统的基于cf的推荐系统。在我们最近的调查[96]中,一篇论文将用户关系整合到图表中,并展示了这种策略的有效性。因此,在KG中考虑用户侧信息可能是另一个研究方向。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。