让cephfs单客户端在垃圾硬件上每秒写入几万个文件
之前业界一直误会了分布式文件系统。 都认为对象存储的优越性好于NAS。业界部分人认为:对象存储是扁平的,而文件系统是树型的,不够扁平,所以对于海量小文件的性能上,对象存储要比文件存储性能好。在分布式文件系统兴起后,这个结论是错的。原因如下:
1,把对象存储和传统NAS比,传统NAS是在块设备上做xfs+nfs,nfs流量是单点的。 新型的NAS早就以分布式文件系统cephfs代替。cephfs随着mds增多,性能线性扩展。
2,拿树型结构做为文件系统的缺陷也没有依据,这完全看用户需要。用户如果只使用一个目录,那cephfs也是扁平的。且cephfs大部分inode元数据都读缓存了,树型结构已经不是缺陷,而是优点。因为对象存储的元数据大,对rocksdb压力大,元数据大当然没法完全内存缓存。
3,真正的扁平型存储系统,应该以谷歌论文为主的小文件系统haystack,seaweedfs,tfs 等。这些系统文件仅仅是硬盘上的一个id+offset。这边不多做解释,可以查阅haystack相关论文。
在这里不是要褒文件系统,贬对象存储。其实各有优势,对象存储在外网app 场景。 例如外网上传下载,网盘等领域作用比较大的。下面我们看怎么从机械盘的服务器上,单客户端访问让cephfs跑出几万文件每秒。
一,硬件配置:
1,服务器10台,每台服务器2SSD+8SATA。
2,万兆网卡+万兆网络。
3,ceph-12.2.7 ,内核版本4.19.15
4,2块SSD盘,做bluestore(DB,WAL)。剩余的SSD分区做cephfs的元数据池(cephfs_metadata)
5, 8块SATA盘,做OSD, 做成cephfs的数据池cephfs_data
6,做12个mds,10个active mds,2个standby mds。
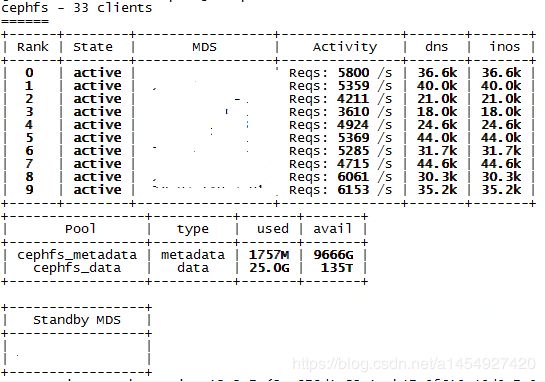
得到集群如下:95个 active osd,10个mds。

二,配置文件和准备工作
1,修改/etc/ceph/ceph.conf,加入 mds_bal_min_rebalance=1000 ,让cephfs多mds之间缓存数据不迁移,使用静态负载均衡,如果不知道静态负载均衡,请参考我之前的博客。
2,创建30个目录,做为挂载点。(就是本地的挂载目录/mnt/cephfs0~/mnt/cephfs29)
为什么要创建30个挂载点?这里是重点,因为cephfs客户端在内核是单线程的,如果只有一个挂载点,不能并发的读写,所以我们要在一台服务器上创建30个cephfs挂载点,并且产生30个cephfs客户端,来产生并发性。
3,在cephfs里面创建30个目录(cephfs0~cephfs29),把cephfs 30个目录分别挂载本地的(/mnt/cephfs0~/mnt/cephfs29)上。
#df -h 命令查看如下:

挂载完之后,我们可以在/sys/kernel/debug/ceph目录下看到,产生了30个客户端句柄。每个客户端在内核是单线程的,所以我们通过30个挂载点,产生30个客户端,来产生30个并发。

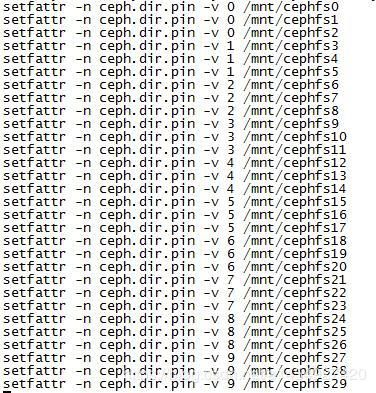
4,把挂载目录绑定到mds。
一共有30个挂载目录,10个mds,所以我们每3个目录绑定1个mds。
5,准备测试程序
测试程序开30个线程,每个线程对应一个cephfs挂载目录,每个线程写入6万文件,一共写入cephfs集群180万文件。
------------------------------------------------------------------------
#include
#include
#include
#include
#include
#include
#include
#include "time.h"
#define THREAD_MAX_NUM 30
#define FILE_COUNTS 60000
pthread_mutex_t mut = PTHREAD_MUTEX_INITIALIZER;
pthread_t thread[THREAD_MAX_NUM];
char path[]="/mnt/cephfs";
int open_write(int count,int index)
{
int fd,i;
char path_name[128];
char s[16384];
memset(s,'a',16384);
printf("begin write %d now!\n",index);
for(i=0;i { memset(path_name,0,128); sprintf(path_name,"%s%d/%dhello%d",path,index,index,i); fd=open(path_name,O_WRONLY|O_CREAT); write(fd,s,16384); close(fd); } } void* sub_thread(void *arg) { printf("thread proc %d\n",(int)arg); open_write(FILE_COUNTS,(int)arg); return(0); } int create_thread() { int i=0; for(i=0;i { pthread_create(&thread[i],NULL,sub_thread,(void*)i); printf("creating thread %d\n",i); } for(i=0;i { pthread_join(thread[i],NULL); } return 0; } int main() { clock_t start, finish; double duration; start = clock(); pthread_mutex_init(&mut,NULL); create_thread(); finish = clock(); duration = (double)(finish - start) / CLOCKS_PER_SEC; printf( "%f seconds\n", duration ); return 0; } ------------------------------------------------------------------------ 三,测试结果: 1,执行测试程序的时候查看mds状态,感受mds性能。 可以看到每个mds平均产生了5000个文件系统请求。 整个集群大约有50000个mds请求。 2,根据程序的执行时间,计算每秒写入的文件数。 测试程序跑完后,查看测试程序跑了多长时间。 一共跑了97秒。 写入了180万文件。 180万/97秒=18556 files/秒。 即每秒1万8千个文件。 3,验证写入文件数量的正确性。 一个mds对应3个目录,每个目录6万文件,那一个mds就是18万文件,图片显示一个mds 180K inode,正确!