深度学习(tensorflow2)笔记
日月光华-tensorflow笔记
基础

逻辑回归与交叉熵

softmax分类
对数几率回归解决的是二分类的问题,对于多个选项的问题,我们可以使用softmax函数。它是对数几率回归在N个可能不同的值上的推广。
神经网络的原始输出不是一个概率值,实质上只是输入的数值做了复杂的加权和与非线性处理之后的一个值而已,那么如何将这个输出变为概率分布?
——这就是softmax层的作用
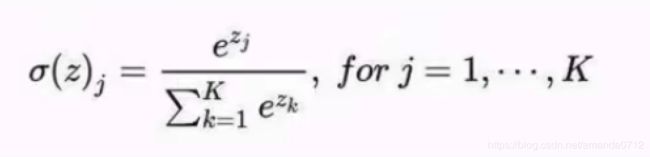
softmax个样本分量之和为1,当只有两个类别时,与对数几率回归完全相同
在tf.keras里,对于多分类问题我们使用categorical_crossentropy和sparse_categorical_crossentropy来计算Softmax交叉熵
Fashion MNIST数据集实战
Fashion MNIST 的作用是成为经典MNIST数据集的建议替换,MNIST数据集包含手写数字(0,1,2等)的图像,这些图像的格式与本节课中使用的服饰图像的格式相同。
数据集相对较小,用于验证某个算法能否如期正常运行。包含70000张灰度图像,涵盖10个类别。
将使用60000张图像训练网络,并使用10000张图像评估经过学习的网络分类图像的准确率
可以从tensorflow直接访问Fashion MNIST,只需导入和加载数据即可。
代码过程见Notebook及github
独热编码
在tf.keras里,对于多分类问题我们使用categorical_crossentropy和sparse_categorical_crossentropy来计算Softmax交叉熵
fashion_MNIST数据集里,一开始使用的是sparse_categorical_crossentropy(顺序数字编码)。
但在另一种情况下(独热编码),使用categorical_crossentropy。
优化函数,学习速率,反向传播算法

梯度下降法
梯度下降法是一种致力于找到函数极值点的算法。
所谓“学习”便是改进模型参数,以便通过大量训练步骤将损失最小化。有了这个概念,将梯度下降法应用于寻找损失函数的极值点。
梯度的输出向量表明了在每个位置损失函数增长最快的方向。可将它视为表示了在函数的每个位置向哪个方向移动函数值可以增长。
学习速率
梯度就是表明损失函数相对参数的变化率
对梯度进行缩放的参数被称为学习速率(learning rate)
学习速率是一种超参数或对模型的一种手工可配置的设置需要为它指定正确的值。如果学习速率太小,则找到损失函数极小值点时可能需要许多轮迭代;如果太大,则算法可能会“跳过”极小值点并且因周期性的“跳跃”而永远无法到达极小值点。
实际上需要调整学习速率不过小或过大
反向传播算法
反向传播算法时一种高效计算数据流图中梯度的技术
每一层的导数都是后一层的导数与前一层输出之积,这正是链式法则的奇妙之处,误差反向传播算法利用了这一点。
前馈时,从输入开始,逐一计算每个隐含层的输出,直到输出层。
然后开始计算导数,并从输出层经各隐含层逐一反向传播。为了减少计算量,还需对所有以完成计算的元素进行复用。这便是反向传播算法名称的由来。
常见的优化函数
优化器是编译 模型的所需的两个参数之一。可以先实例化一个优化器对象,然后将它传入model.compile(),或者可以通过名称来调用优化器。在后一种情况下,将使用优化器的默认参数。
SGD:随机梯度下降优化器
随机梯度下降优化器SGD和min-batch是同一个意思,抽取m个小批量(独立同分布)样本,通过计算他们平梯度均值。
RMSprop:经验上,RMSProp被证明有效且实用的深度学习网络优化算法。增加了一个衰减系数来控制历史信息的获取多少,RMSProp会对学习率进行衰减。
Adam优化器:1.Adam算法可以看作是修正后的Momentum+RMSProp算法。2.Adam通常被认为对超参数的选择相当鲁棒(不敏感) 3.学习率建议为0.001
是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。Adam通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
网络优化与超参数选择
网络容量
网络中的神经单元数越多,层数越多,神经网络的拟合能力越强。
但是训练速度,难度越大,越容易产生过拟合。
可以认为与网络中的可训练参数成正比。
如何选择超参数?
所谓超参数,也就是搭建神经网络中,需要我们自己如选择(不是通过梯度下降算法去优化)的那些参数。比如中间层的神经元个数,学习速率.
如何提高网络的拟合能力
一种显然的想法是增
大网络容量:
1.增加层
2.增加隐藏神经元个数
这两种方法哪种更好呢?
单纯的增加神经元个数对于网络性能的提高并不明显,增加层会大大提高网络的拟合能力
这也是为什么现在深度学习的层越来越深的原因。
单层的神经元个数,不能太小,太小的话,会造成信息瓶颈,使得模型欠拟合。
网络中的神经单元数越多,层数越多,神经网络的拟合能力越强。但是训练速度,难度越大,越容易产生过拟合。
Dropout抑制过拟合与超参数选择
过拟合:在训练数据上得分很高,在测试数据上得分相对比较低
欠拟合:在训练数据上得分比较低,在测试数据上得分相对比较低

为什么dropout可以解决过拟合?
(1)取平均的作用:先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用“5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。
如何选择超参数?
理想的模型是刚好在欠拟合和过拟合的界限上,也就是正好拟合数据。
参数选择原则
首先开发一个过拟合的模型:
(1)添加更多的层。
(2)让每一层变得更大。
(3)训练更多的轮次。
然后,抑制过拟合:
(1)dropout
(2)正则化
(3)图像增强
再次,调节超参数:
学习速率,
隐藏层单元数,
训练轮次
超参数的选择是一个经验与不断测试的结果。
经典机器学习的方法,如特征工程,增加训练数据也要做
交叉验证
减小神经网络规模也是抑制过拟合的一种方法
(见代码05)