Python爬虫从入门到精通——爬虫实战:爬取猫眼电影排行Top100
分类目录:《Python爬虫从入门到精通》总目录
本文为实战篇,需提前学习Python爬虫从入门到精通中《基本库requests的使用》和《解析库re的使用:正则表达式》的内容。
我们需要抓取的目标为猫眼电影-榜单-TOP100榜,其地址为:https://maoyan.com/board/4。我们希望爬取各个电影的排名、名称、主演、上映时间、上映地区等信息。最后保存为一张Excel表格。

首先,我们定义一个get_page(url)函数,用于返回url的HTML源码。这里我们对status_code进行判断,若status_code取值为200,说明正常获取到HTML源码,则函数将HTML源码返回,若weight正常获取到HTML源码,则返回'Crawl Failed'。
import requests
import re
def get_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return 'Crawl Failed'
print(get_page('https://maoyan.com/board/4'))
通过打印response.text我们在IDE中可以看到站点的HTML源码。

IDE中显示的源码和浏览器中显示的源码一致,说明我们获取成功。
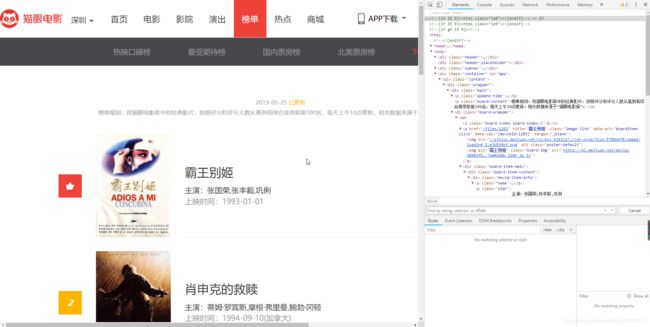
我们先来看《霸王别姬》这一段的源码:
1

![霸王别姬]()
9.5


通过比对其它电影的HTML源码片段就可以发现,我们需要的电影的排名、名称、主演、上映时间、上映地区等信息就是图示红框中的信息。但是,部分电影没有上映地区字段(如图中的《霸王别姬》),而另外有上映地区字段的电影将上映信息接在了上映日期的后部(如《肖申克的旧书》HTML源码中1994-09-10(加拿大)),这就需要我们对这两种情况分别进行处理。
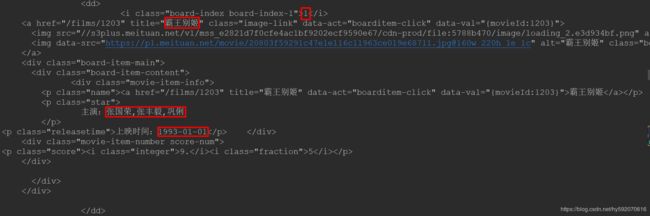
首先,我们可以根据《基本库re的使用:正则表达式》中的介绍匹配这一段的字符串的正则表达式。从网页的HTML源码中可以看到,一部电影信息对应的源代码是一个dd节点。首先,需要提取它的排名信息。而它的排名信息是在class为board-index的i节点内,这里利用非贪婪匹配来提取i节点内的信息。
import requests
import re
def get_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return 'Crawl Failed'
def parse_html(html):
pattern = re.compile('.*?board-index.*?>(\d+)', re.S)
result = re.findall(pattern, html)
return result
html = get_page('https://maoyan.com/board/4')
result = parse_html(html)
print(result)
我们定义了parse_html(html)函数解析参数html的HTML源码。在正则表达式中我们描述了
['1', '2', '3', '4', '5', '6', '7', '8', '9', '10']
紧接着我们匹配电影名称,可以发现,电影名称字段被title=" "包裹,字符串后端还是有非常多的引号,所以匹配电影名称我们仍然采用非贪婪匹配。
import requests
import re
def get_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return 'Crawl Failed'
def parse_html(html):
pattern = re.compile('.*?board-index.*?>(\d+).*?title="(.*?)"', re.S)
result = re.findall(pattern, html)
return result
html = get_page('https://maoyan.com/board/4')
result = parse_html(html)
print(result)
从结果可以看出,本次匹配成功。
[('1', '霸王别姬'), ('2', '肖申克的救赎'), ('3', '罗马假日'), ('4', '这个杀手不太冷'), ('5', '泰坦尼克号'), ('6', '唐伯虎点秋香'), ('7', '魂断蓝桥'), ('8', '乱世佳人'), ('9', '天空之城'), ('10', '辛德勒的名单')]
用相同的方法我们就可以继续匹配其它信息。但是需要注意的是,在用正则表达式的时候尽量使用非贪婪匹配.*?,且可以适当地增加匹配的字段(如title、star、releasetime)而不是仅仅匹配我们期望匹配字段的前后字段,这样可以加快正则表达式匹配的速度。
import requests
import re
def get_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return 'Crawl Failed'
def parse_html(html):
pattern = re.compile('.*?board-index.*?>(\d+).*?name.*?title="(.*?)".*?star.*?主演:(.*?).*?releasetime.*?上映时间:(.*?)', re.S)
result = re.findall(pattern, html)
return result
html = get_page('https://maoyan.com/board/4')
result = parse_html(html)
print(result)
运行完上述的代码我们就可以得到结果:
[('1', '霸王别姬', '张国荣,张丰毅,巩俐\n ', '1993-01-01'), ('2', '肖申克的救赎', '蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿\n ', '1994-09-10(加拿大)'), ('3', '罗马假日', '格利高里·派克,奥黛丽·赫本,埃迪·艾伯特\n ', '1953-09-02(美国)'), ('4', '这个杀手不太冷', '让·雷诺,加里·奥德曼,娜塔莉·波特曼\n ', '1994-09-14(法国)'), ('5', '泰坦尼克号', '莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩\n ', '1998-04-03'), ('6', '唐伯虎点秋香', '周星驰,巩俐,郑佩佩\n ', '1993-07-01(中国香港)'), ('7', '魂断蓝桥', '费雯·丽,罗伯特·泰勒,露塞尔·沃特森\n ', '1940-05-17(美国)'), ('8', '乱世佳人', '费雯·丽,克拉克·盖博,奥利维娅·德哈维兰\n ', '1939-12-15(美国)'), ('9', '天空之城', '寺田农,鹫尾真知子,龟山助清\n ', '1992'), ('10', '辛德勒的名单', '连姆·尼森,拉尔夫·费因斯,本·金斯利\n ', '1993-12-15(美国)')]
其中,电影排行、电影名称与期望的一致,但演员信息的尾部有换行符和空格,上映日期字段和地区字段也没有区分开,所以我们需要将其处理后在保存到表格中。
import re
import requests
import pandas as pd
def get_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return 'Crawl Failed'
def parse_html(html):
pattern = re.compile('.*?board-index.*?>(\d+).*?name.*?title="(.*?)".*?star.*?主演:(.*?).*?releasetime.*?上映时间:(.*?)', re.S)
result = re.findall(pattern, html)
return result
html = get_page('https://maoyan.com/board/4')
result = parse_html(html)
data = pd.DataFrame([], columns=['Name', 'Actors', 'Date', 'Region'])
for item in result:
rank = item[0]
name = item[1]
actors = item[2].strip()
temp = item[3].split('(')
if len(temp) == 1:
date = temp[0]
data.loc[rank, 'Date'] = date
else:
date = temp[0]
region = temp[1][:-1]
data.loc[rank, 'Date'] = date
data.loc[rank, 'Region'] = region
data.loc[rank, 'Name'] = name
data.loc[rank, 'Actors'] = actors
查看data我们就可以看到我们爬取的数据:
Name Actors Date Region
1 霸王别姬 张国荣,张丰毅,巩俐 1993-01-01 NaN
2 肖申克的救赎 蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿 1994-09-10 加拿大
3 罗马假日 格利高里·派克,奥黛丽·赫本,埃迪·艾伯特 1953-09-02 美国
4 这个杀手不太冷 让·雷诺,加里·奥德曼,娜塔莉·波特曼 1994-09-14 法国
5 泰坦尼克号 莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩 1998-04-03 NaN
6 唐伯虎点秋香 周星驰,巩俐,郑佩佩 1993-07-01 中国香港
7 魂断蓝桥 费雯·丽,罗伯特·泰勒,露塞尔·沃特森 1940-05-17 美国
8 乱世佳人 费雯·丽,克拉克·盖博,奥利维娅·德哈维兰 1939-12-15 美国
9 天空之城 寺田农,鹫尾真知子,龟山助清 1992 NaN
10 辛德勒的名单 连姆·尼森,拉尔夫·费因斯,本·金斯利 1993-12-15 美国
此时,我们已经对爬取猫眼电影排行Top100中第一页进行了爬取,接着我们可以使用for循环依次爬取1~10页的电影并保存到数据集中。通过观察URL可以发现,猫眼电影排行Top100的URL中通过参数offset控制页码,如第一页为https://maoyan.com/board/4?offset=0,第二页为https://maoyan.com/board/4?offset=10。所以,我们可以通过构建一个for循环爬取所有TOP100的内容。
import re
import requests
import pandas as pd
def get_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return 'Crawl Failed'
def parse_html(html):
pattern = re.compile('.*?board-index.*?>(\d+).*?name.*?title="(.*?)".*?star.*?主演:(.*?).*?releasetime.*?上映时间:(.*?)', re.S)
result = re.findall(pattern, html)
return result
url = 'https://maoyan.com/board/4?offset='
data = pd.DataFrame([], columns=['Name', 'Actors', 'Date', 'Region'])
for i in range(10):
page_url = url + str(i * 10)
html = get_page(page_url)
result = parse_html(html)
for item in result:
rank = item[0]
name = item[1]
actors = item[2].strip()
temp = item[3].split('(')
if len(temp) == 1:
date = temp[0]
data.loc[rank, 'Date'] = date
else:
date = temp[0]
region = temp[1][:-1]
data.loc[rank, 'Date'] = date
data.loc[rank, 'Region'] = region
data.loc[rank, 'Name'] = name
data.loc[rank, 'Actors'] = actors
data.to_csv('猫眼电影TOP100.csv', encoding='gbk')
最后,将pandas.DataFrame保存为CSV格式的数据文件即可得到我们期望爬取的猫眼电影排行Top100的电影信息了。
