Linux指令(五)
文章目录
- 软件包管理
- 存储媒介
- 网络系统
- traceroute
- netstat
- 网络中传输文件
- 与远程主机安全通信
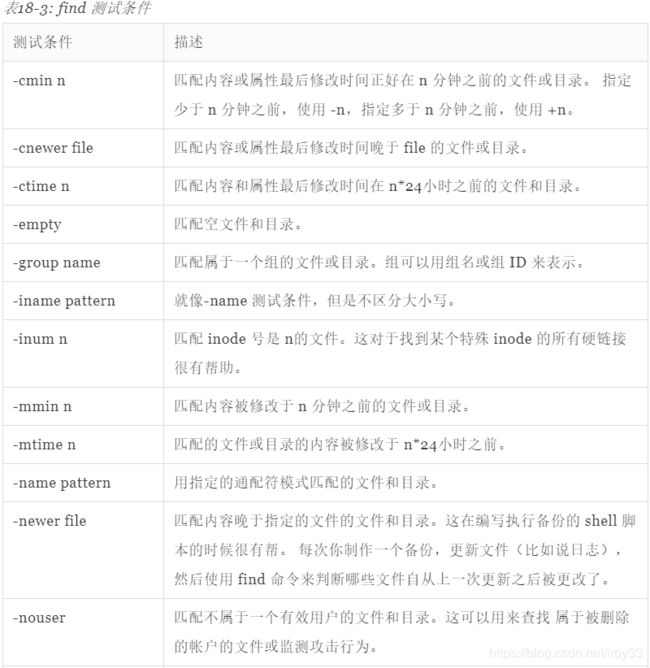
- 查找文件
- locate - 查找文件的简单方法
- find - 查找文件的复杂方式
- 操作符
- 预定义的操作
- 用户定义的行为
- 提高效率
- xargs
- stat 显示文件或文件系统状态
- 归档和备份
- gzip
- 归档文件
- zip
- 同步文件和目录
- 正则表达式
- 元字符和原义字符
- POSIX字符集
- 交替
- 文件处理
- cat
- sort
- uniq
- 切片和切块
- paste
- join
- comm 逐行比较两个有序的文件
- diff 逐行比较文件
- patch 给原始文件打补丁
- tr
- sed 用于筛选和转换文本的流编辑器
- aspell 交互式拼写检查器
- 格式化输出
- 编译程序
- make
软件包管理
不同的 Linux 发行版使用不同的打包系统,一般而言,大多数发行版分别属于两大包管理技术阵营: Debian 的”.deb”,和红帽的”.rpm”。也有一些重要的例外,比方说 Gentoo, Slackware,和 Foresight,但大多数会使用这两个基本系统中的一个。
Linux 系统中几乎所有的软件都可以在互联网上找到。其中大多数软件由发行商以 包文件的形式提供,剩下的则以源码形式存在,可以手动安装。
在包管理系统中软件的基本单元是包文件。包文件是一个构成软件包的文件压缩集合。一个软件包可能由大量程序以及支持这些程序的数据文件组成。除了安装文件之外,软件包文件也包括 关于这个包的元数据,如软件包及其内容的文本说明。另外,许多软件包还包括预安装和安装后脚本, 这些脚本用来在软件安装之前和之后执行配置任务。
系统发行版的用户可以在一个中心资源库中得到这些软件包,这个资源库可能 包含了成千上万个软件包,每一个软件包都是专门为这个系统发行版建立和维护的。
程序很少独立工作;他们需要依靠其他程序的组件来完成他们的工作。程序所共有的活动,如输入/输出, 就是由一个被多个程序调用的子例程处理的。这些子例程存储在动态链接库中。动态链接库为多个程 序提供基本服务。如果一个软件包需要一些共享的资源,如一个动态链接库,它就被称作有一个依赖。 现代的软件包管理系统都提供了一些依赖项解析方法,以确保安装软件包时,其所有的依赖也被安装。

软件包管理系统通常由两种工具类型组成:
- 底层工具用来处理这些任务,比方说安装和删除软件包文件
- 上层工具,完成元数据搜索和依赖解析。
虽然所有基于 Red Hat 风格的发行版都依赖于相同的底层程序(rpm), 但是它们却使用不同的上层工具。


例如:从一个 apt 资源库来安装 emacs 文本编辑器:
apt-get update; apt-get install emacs


Linux 软件生态系统是基于开放源代码理念。如果一个程序开发人员发布了一款产品的 源码,那么与系统发行版相关联的开发人员可能就会把这款产品打包,并把它包含在 他们的资源库中。这种方法保证了这款产品能很好地与系统发行版整合在一起,同时为用户 “一站式采购”软件提供了方便,从而用户不必去搜索每个产品的网站。
存储媒介
这个 mount 命令被用来挂载文件系统。执行这个不带参数的命令,将会显示 一系列当前挂载的文件系统:
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
udev on /dev type devtmpfs (rw,nosuid,relatime,size=978644k,nr_inodes=244661,mode=755)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000)
tmpfs on /run type tmpfs (rw,nosuid,noexec,relatime,size=200600k,mode=755)
/dev/sda1 on / type ext4 (rw,relatime,errors=remount-ro)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev)
这个列表的格式是:设备 on 挂载点 type 文件系统类型(选项)。
/dev/sda1 on / type ext4 (rw,relatime,errors=remount-ro)
/dev/sda2作为根文件系统被挂载,文件系统类型是ext4,并且可读可写
网络系统
当谈及到网络系统层面,几乎任何东西都能由 Linux 来实现。Linux 被用来创建各式各样的网络系统和装置, 包括防火墙,路由器,名称服务器,网络连接式存储设备等等。
traceroute
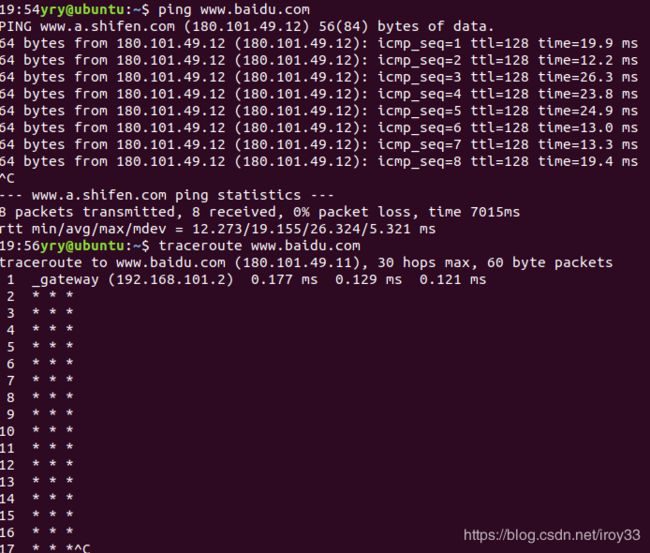
对于那些没有提供标识信息的路由器(由于路由器配置,网络拥塞,防火墙等 方面的原因),我们会看到几个星号,正如行中所示。去百度要经过30跳
netstat
netstat 程序被用来检查各种各样的网络设置和统计数据。通过此命令的许多选项,我们 可以看看网络设置中的各种特性。使用“-ie”选项,我们能够查看系统中的网络接口:
和ifconfig效果一样
使用这个“-r”选项会显示内核的网络路由表。这展示了系统是如何配置网络之间发送数据包的。
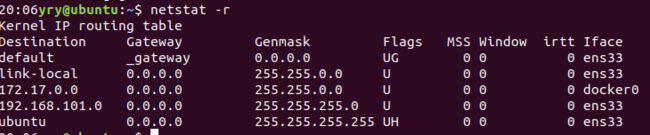
第一列目的地址里是广播地址,Gateway是路由器的名字或IP地址,用它来连接当前的主机和目的地网络。若这个字段显示一个*,说明不需要网关。
网络中传输文件
wget
若想从网络和 FTP 网站两者上都能下载数据,wget 是很有用处的。 不只能下载单个文件,多个文件,甚至整个网站都能下载。
这个程序的许多选项允许 wget 递归地下载,在后台下载文件(你退出后仍在下载),能完成未下载 全的文件。这些特性在其优秀的命令手册中有着详尽地说明
与远程主机安全通信
通过网络来远程操控类 Unix 的操作系统已经有很多年了。早些年,在因特网普遍推广之前,有 一些受欢迎的程序被用来登录远程主机。它们是 rlogin 和 telnet 程序。然而这些程序,拥有和 ftp 程序 一样的致命缺点;它们以明码形式来传输所有的交流信息(包括登录命令和密码)。这使它们完全不 适合使用在因特网时代。
SSH 解决了这两个基本的和远端主机安全交流的问题。首先,它要认证远端主机是否为它 所知道的那台主机(这样就阻止了所谓的“中间人”的攻击),其次,它加密了本地与远程主机之间 所有的通讯信息。
SSH 由两部分组成。SSH 服务端运行在远端主机上,在端口 22 上监听收到的外部连接,而 SSH 客户端用在本地系统中,用来和远端服务器通信
远端 shell 会话一直存在,直到用户输入 exit 命令后,则关闭了远程连接。这时候,本地的 shell 会话 恢复,本地 shell 提示符重新出现。
也有可能使用不同的用户名连接到远程系统。例如,如果本地用户“me”,在远端系统中有一个帐号名 “bob”,则用户 me 能够用 bob 帐号登录到远端系统,如下所示:
[me@linuxbox ~]$ ssh bob@remote-sys
bob@remote-sys's password:
Last login: Sat Aug 30 13:03:21 2008
[bob@remote-sys ~]$
[me@linuxbox ~]$ ssh remote-sys 'ls \*' > dirlist.txt
me@twin4's password:
[me@linuxbox ~]$
上面的例子中使用了单引号。这样做是因为我们不想路径名展开操作在本地执行,而希望 它在远端系统中被执行。
如果我们想要把输出结果重定向到远端主机的文件中,我们可以 把重定向操作符和文件名都放到单引号里面。
ssh remote-sys 'ls * > dirlist.txt'
查找文件
- locate – 通过名字来查找文件
- find – 在一个目录层次结构中搜索文件
- xargs – 从标准输入生成和执行命令行
- touch – 更改文件时间
- stat – 显示文件或文件系统状态
locate - 查找文件的简单方法
locate bin/zip
locate zip | grep bin
locate 数据库由另一个叫做 updatedb 的程序创建。通常,这个程序作为一个定时任务(jobs)周期性运转。大多数装有 locate 的系统会每隔一天运行一回 updatedb 程序。因为数据库不能被持续地更新,所以当使用 locate 时,你会发现 目前最新的文件不会出现。为了克服这个问题,通过更改为超级用户身份,在提示符下运行 updatedb 命令, 可以手动运行 updatedb 程序。
find - 查找文件的复杂方式
find 命令接收一个或多个目录名来执行搜索。
。因为这张列表被发送到标准输出, 我们可以把这个列表管道到其它的程序中。让我们使用 wc 程序来计算出文件的数量:
20:27yry@ubuntu:~$ find ~ | wc -l
11222
想在我们的搜索中得到目录列表
20:28yry@ubuntu:~$ find ~ -type d | wc -l
2833
20:29yry@ubuntu:~$ find ~ -type f | wc -l
8237
所以还有152个

find ~ -type f -name "*.JPG" -size +1M | wc -l
在这个例子里面,我们加入了 -name 测试条件,后面跟通配符模式。注意,我们把它用双引号引起来, 从而阻止 shell 展开路径名。紧接着,我们加入 -size 测试条件,后跟字符串“+1M”。开头的加号表明 我们正在寻找文件大小大于指定数的文件。若字符串以减号开头,则意味着查找小于指定数的文件。 若没有符号意味着“精确匹配这个数”。结尾字母“M”表明测量单位是兆字节。下面的字符可以 被用来指定测量单位:
操作符
即使拥有了 find 命令提供的所有测试条件,我们还需要一个更好的方式来描述测试条件之间的逻辑关系。例如, 如果我们需要确定是否一个目录中的所有的文件和子目录拥有安全权限,怎么办呢? 我们可以查找权限不是0600的文件和权限不是0700的目录。幸运地是,find 命令提供了 一种方法来结合测试条件,通过使用逻辑操作符来创建更复杂的逻辑关系。 为了表达上述的测试条件,我们可以这样做:find ~ \( -type f -not -perm 0600 \) -or \( -type d -not -perm 0700 \)
find ~ ( -type f -not -perms 0600 ) -or ( -type d -not -perms 0700 )
因为圆括号对于 shell 有特殊含义,我们必须转义它们,来阻止 shell 解释它们。在圆括号字符 之前加上一个反斜杠字符来转义它们。

expr1 -operator expr2
在所有情况下,总会执行表达式 expr1;然而操作符将决定是否执行表达式 expr2。和C语言逻辑是一样的
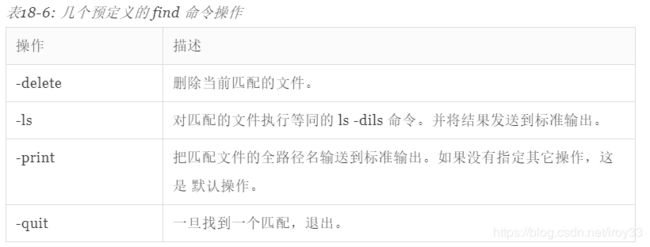
预定义的操作
find 命令允许基于搜索结果来执行操作。有许多预定义的操作和几种方式来 应用用户定义的操作
find ~ -type f -name '*.BAK' -delete
警告:当使用 -delete 操作时,不用说,你应该格外小心。每次都应该首先用 -print 操作代替 -delete 测试一下命令,来确认搜索结果。
find ~ -print -and -type f -and -name '*.BAK'
这个命令会打印出每个文件(-print行为总是为真)
用户定义的行为
除了预定义的行为之外,我们也可以调用任意的命令。传统方式是通过 -exec 行为。这个 行为像这样工作:-exec command {} ;
{}是当前路径名的符号表示,分号是必要的分隔符 表明命令的结束。这里是一个使用 -exec 行为的例子,其作用如之前讨论的 -delete 行为:
-exec rm '{}' ';'
因为花括号和分号对于 shell 有特殊含义,所以它们必须被引起来或被转义。
我们也可以交互式地执行一个用户定义的行为。通过使用 -ok 行为来代替 -exec,在执行每个指定的命令之前, 会提示用户:
20:57yry@ubuntu:~$ find ~ -type f -name 'foo*' -ok ls -l "{}" ";"
< ls ... /home/yry/foo.txt > ? y
-rw-rw-r-- 1 yry yry 46 Feb 20 17:17 /home/yry/foo.txt
提高效率
当 -exec 行为被使用的时候,若每次找到一个匹配的文件,它会启动一个新的指定命令的实例。 我们可能更愿意把所有的搜索结果结合起来,再运行一个命令的实例。例如,与其像这样执行命令:
ls -l file1
ls -l file2
不如ls -l file1 file2,命令只被执行一次而不是多次。
21:01yry@ubuntu:~$ find ~ -type f -name 'foo*' -exec ls -l "{}" +
-rw-rw-r-- 1 yry yry 0 Feb 20 21:00 /home/yry/foo2.txt
-rw-rw-r-- 1 yry yry 46 Feb 20 17:17 /home/yry/foo.txt
-ok 不支持
xargs
它从标准输入接受输入,并把输入转换为一个特定命令的 参数列表
21:02yry@ubuntu:~$ find ~ -type f -name 'foo*' | xargs ls -l
-rw-rw-r-- 1 yry yry 0 Feb 20 21:00 /home/yry/foo2.txt
-rw-rw-r-- 1 yry yry 46 Feb 20 17:17 /home/yry/foo.txt
看到 find 命令的输出被管道到 xargs 命令,之后,xargs 会为 ls 命令构建 参数列表,然后执行 ls 命令。
注意:当被放置到命令行中的参数个数相当大时,参数个数是有限制的。有可能创建的命令 太长以至于 shell 不能接受。当命令行超过系统支持的最大长度时,xargs 会执行带有最大 参数个数的指定命令,然后重复这个过程直到耗尽标准输入。执行带有 –show–limits 选项 的 xargs 命令,来查看命令行的最大值。
find 命令提供的 -print0 行为, 则会产生由 null 字符分离的输出,并且 xargs 命令有一个 –null 选项,这个选项会接受由 null 字符 分离的输入。find ~ -iname ‘*.jpg’ -print0 xargs –null ls -l.使用这项技术,我们可以保证所有文件,甚至那些文件名中包含空格的文件,都能被正确地处理。
21:04yry@ubuntu:~$ mkdir -p playground/dir-{00{1..9},0{10..99},100}
21:07yry@ubuntu:~$ touch playground/dir-{00{1..9},0{10..99},100}/file-{A..Z}
21:08yry@ubuntu:~$ find playground -type f -name 'file-A'
playground/dir-088/file-A
playground/dir-083/file-A
playground/dir-051/file-A
playground/dir-067/file-A
playground/dir-092/file-A
playground/dir-061/file-A
playground/dir-033/file-A
playground/dir-062/file-A
playground/dir-043/file-A
注意不同于 ls 命令,find 命令的输出结果是无序的。其顺序由存储设备的布局决定。
touch playground/timestamp
find playground -type f -name 'file-B' -exec touch '{}' ';'
21:31yry@ubuntu:~$ find playground -type f -newer playground/timestamp
playground/dir-088/file-B
playground/dir-083/file-B
playground/dir-051/file-B
playground/dir-067/file-B
playground/dir-092/file-B
playground/dir-061/file-B
playground/dir-033/file-B
playground/dir-062/file-B
playground/dir-043/file-B
playground/dir-068/file-B
playground/dir-081/file-B
find playground \( -type f -not -perm 0600 \) -or \( -type d -not -perm 0700 \)
注意括号前后要有空格!!!
21:34yry@ubuntu:~$ find playground \( -type f -not -perm 0600 -exec chmod 0600 '{}' ';' \) -or \( -type d -not -perm 0700 -exec chmod 0700 '{}' ';' \)
21:36yry@ubuntu:~$ find playground \( -type f -not -perm 0600 \) -or \( -type d -not -perm 0700 \)
21:36yry@ubuntu:~$
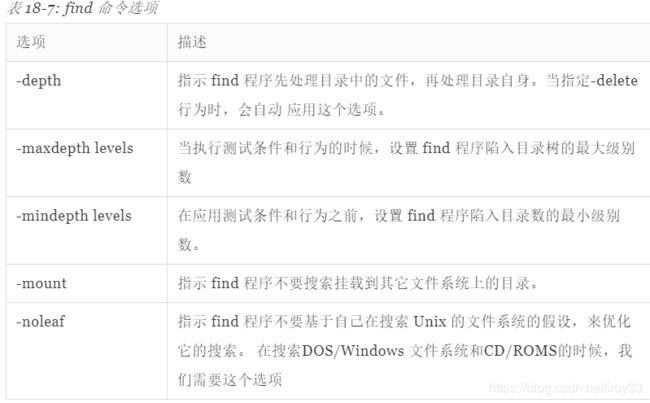
stat 显示文件或文件系统状态
加大码力的ls
归档和备份
- gzip – 压缩或者展开文件
- bzip2 – 块排序文件压缩器
- tar – 磁带打包工具
- zip – 打包和压缩文件
- rsync – 同步远端文件和目录
gzip
21:47yry@ubuntu:~$ gzip foo.txt
21:48yry@ubuntu:~$ ls -l foo.*
-rw-rw-r-- 1 yry yry 2696 Feb 20 21:47 foo.txt.gz
21:48yry@ubuntu:~$ gunzip foo.txt.gz
21:49yry@ubuntu:~$ ls -l foo.*
-rw-rw-r-- 1 yry yry 13061 Feb 20 21:47 foo.txt

1:55yry@ubuntu:~$ gzip foo.txt
21:55yry@ubuntu:~$ gzip -tv foo.txt.gz
foo.txt.gz: OK
21:55yry@ubuntu:~$ gzip -d foo.txt.gz #解压缩
21:55yry@ubuntu:~$ ls
Desktop Downloads foo2.txt Music playground snap Videos
Documents examples.desktop foo.txt Pictures Public Templates
21:55yry@ubuntu:~$ ls -l foo.*
-rw-rw-r-- 1 yry yry 13061 Feb 20 21:47 foo.txt
21:57yry@ubuntu:~$ ls -l /etc | gzip > foo.txt.gz
21:57yry@ubuntu:~$ ls -l foo.*
-rw-rw-r-- 1 yry yry 13061 Feb 20 21:47 foo.txt
-rw-rw-r-- 1 yry yry 2688 Feb 20 21:57 foo.txt.gz
21:57yry@ubuntu:~$
21:58yry@ubuntu:~$ gunzip foo.txt.gz
gzip: foo.txt already exists; do you wish to overwrite (y or n)? y
21:58yry@ubuntu:~$ less foo.ttx
foo.ttx: No such file or directory
21:58yry@ubuntu:~$ less foo.txt
21:58yry@ubuntu:~$
归档文件
tar 程序是用来归档文件的经典工具。它的名字,是 tape archive 的简称,揭示了它的根源,它是一款制作磁带备份的工具。而它仍然被用来完成传统任务, 它也同样适用于其它的存储设备。我们经常看到扩展名为 .tar 或者 .tgz 的文件,它们各自表示“普通” 的 tar 包和被 gzip 程序压缩过的 tar 包。一个 tar 包可以由一组独立的文件,一个或者多个目录,或者 两者混合体组成。
tar mode[options] pathname...
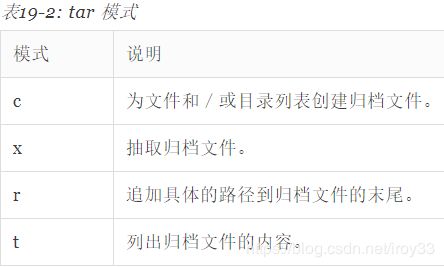
22:08yry@ubuntu:~$ tar cf playground.tar playground
我们 可以看到模式 c 和选项 f,其被用来指定这个 tar 包的名字,模式和选项可以写在一起,而且不 需要开头的短横线。注意,然而,必须首先指定模式,然后才是其它的选项。
想列出归档文件的内容,我们可以这样做:
tar tf playground.tar
tar tvf playground.tar #更详细的信息列表
现在,抽取 tar 包 playground 到一个新位置。我们先创建一个名为 foo 的新目录,更改目录, 然后抽取 tar 包中的文件
22:55yry@ubuntu:~$ cd foo/
22:55yry@ubuntu:~/foo$ ls
22:55yry@ubuntu:~/foo$ tar xf ../playground.tar
22:55yry@ubuntu:~/foo$ ls
playground
如果我们检查 ~/foo/playground 目录中的内容,会看到这个归档文件已经被成功地安装了,也即创建了 一个精确的原始文件的副本。然而,这里有一个警告:除非你是超级用户,要不然从归档文件中抽取的文件 和目录的所有权由执行此复原操作的用户所拥有,而不属于原始所有者。
tar 命令另一个有趣的行为是它处理归档文件路径名的方式。默认情况下,路径名是相对的,而不是绝对 路径。
22:59yry@ubuntu:~$ tar cf playground2.tar ~/playground
tar: Removing leading `/' from member names
22:59yry@ubuntu:~$ ls
Desktop Downloads foo foo.txt Pictures playground2.tar Public Templates
Documents examples.desktop foo2.txt Music playground playground.tar snap Videos
22:59yry@ubuntu:~$ cd foo
22:59yry@ubuntu:~/foo$ tar xf ../playground2.tar
23:00yry@ubuntu:~/foo/home/yry$ ls
playground
它重新创建了 home/me/playground 目录, 相对于我们当前的工作目录,~/foo,而不是相对于 root 目录,作为带有绝对路径名的案例。这样就允许我们抽取文件 到任意位置,而不是强制地把抽取的文件放置到原始目录下。
当抽取一个归档文件时,有可能限制从归档文件中抽取什么内容。例如,如果我们想要抽取单个文件, 可以这样实现:
tar xf archive.tar pathname
[me@linuxbox ~]$ cd foo
[me@linuxbox foo]$ tar xf ../playground2.tar --wildcards 'home/me/playground/dir-\*/file-A'
这里我们使用 find 命令来匹配 playground 目录中所有名为 file-A 的文件,然后使用-exec 行为,来 唤醒带有追加模式(r)的 tar 命令,把匹配的文件添加到归档文件 playground.tar 里面。
find playground -name 'file-A' -exec tar rf playground.tar '{}' '+'
23:13yry@ubuntu:~$ find playground -name 'file-A' -exec tar cf playground3.tar '{}' '+'
23:15yry@ubuntu:~$ ls
Desktop examples.desktop foo.txt playground playground.tar Templates
Documents foo Music playground2.tar Public Videos
Downloads foo2.txt Pictures playground3.tar snap
23:15yry@ubuntu:~$ tar xf playground3.tar
23:15yry@ubuntu:~$ ls
Desktop examples.desktop foo.txt playground playground.tar Templates
Documents foo Music playground2.tar Public Videos
Downloads foo2.txt Pictures playground3.tar snap
23:15yry@ubuntu:~$ cd fo
bash: cd: fo: No such file or directory
23:15yry@ubuntu:~$ cd foo
23:15yry@ubuntu:~/foo$ ls
home playground
23:15yry@ubuntu:~/foo$ tar xf ../playground3.tar
23:16yry@ubuntu:~/foo$ ls
home playground
并不work?
不管tar包的名字是什么,解压出来的名字和yy相同(tar cf xx yy )??
使用 tar 和 find 命令,来创建逐渐增加的目录树或者整个系统的备份,是个不错的方法。通过 find 命令匹配新于某个时间戳的文件,我们就能够创建一个归档文件,其只包含新于上一个 tar 包的文件, 假定这个时间戳文件恰好在每个归档文件创建之后被更新了
如果指定了文件名“-”,则其被看作是标准输入或输出,正是所需(顺便说一下,使用“-”来表示 标准输入/输出的惯例,也被大量的其它程序使用
find playground -name 'file-A' | tar cf playground4.tar --files-from=-
将find的结果归档入playground4.tar。生成的是playground文件夹,每个子文件夹中只有file-A
yry@ubuntu:~$ sudo find playground -name 'file-A' | tar cf - --files-from=-
tar: Refusing to write archive contents to terminal (missing -f option?)
tar: Error is not recoverable: exiting now
find playground -name 'file-A' | tar cf - --files-from=- | gzip > playground.tgz
这个 --file-from 选项(也可以用 -T 来指定) 导致 tar 命令从一个文件而不是命令行来读入它的路径名列表。最后,这个由 tar 命令产生的归档 文件被管道到 gzip 命令中,然后创建了压缩归档文件 playground.tgz。此 .tgz 扩展名是命名 由 gzip 压缩的 tar 文件的常规扩展名。有时候也会使用 .tar.gz 这个扩展名。
虽然我们使用 gzip 程序来制作我们的压缩归档文件,但是现在的 GUN 版本的 tar 命令 ,gzip 和 bzip2 压缩两者都直接支持,各自使用 z 和 j 选项。
find playground -name 'file-A' | tar czf playground.tgz -T -
find playground -name 'file-A' | tar cjf playground.tbz -T -
假定我们有两台机器,每台都运行着类 Unix,且装备着 tar 和 ssh 工具的操作系统。 在这种情景下,我们可以把一个目录从远端系统(名为 remote-sys)传输到我们的本地系统中:
ssh remote-sys 'tar cf - Documents' | tar xf -
zip
这个 zip 程序既是压缩工具,也是一个打包工具。这程序使用的文件格式,Windows 用户比较熟悉, 因为它读取和写入.zip 文件。然而,在 Linux 中 gzip 是主要的压缩程序,而 bzip2则位居第二。
zip options zipfile file...
除非我们包含-r 选项,要不然只有 playground 目录(没有任何它的内容)被存储。虽然会自动添加 .zip 扩展名,但为了清晰起见,我们还是包含文件扩展名。
zip -r playground.zip playground
add files to the archive using one of two storage methods: either it will “store” a file without compression, as shown here, or it will “deflate” the file which performs compression. The numeric value displayed after the storage method indicates the amount of compression achieved. Since our playground only contains empty files, no compression is performed on its contents.
对于 zip 命令(与 tar 命令相反)要注意一点,就是如果指定了一个已经存在的文件包,其被更新 而不是被替代。这意味着会保留此文件包,但是会添加新文件,同时替换匹配的文件。
使用-l 选项,导致 unzip 命令只是列出文件包中的内容而没有抽取文件。如果没有指定文件, unzip 程序将会列出文件包中的所有文件。添加这个-v 选项会增加列表的冗余信息。注意当抽取的 文件与已经存在的文件冲突时,会在替代此文件之前提醒用户。
yry@ubuntu:~$ unzip -l playground.zip playground/dir-087/file-Z
Archive: playground.zip
Length Date Time Name
--------- ---------- ----- ----
0 2020-02-20 21:08 playground/dir-087/file-Z
--------- -------
0 1 file
find playground -name 'file-A' | zip -@ file-A.zip
这里我们使用 find 命令产生一系列与“file-A”相匹配的文件列表,并且把此列表管道到 zip 命令, 然后创建包含所选文件的文件包 file-A.zip。
zip 命令也支持把它的输出写入到标准输出,但是它的使用是有限的,因为很少的程序能利用输出。 不幸地是,这个 unzip 程序,不接受标准输入。这就阻止了 zip 和 unzip 一块使用,像 tar 命令那样, 来复制网络上的文件。zip 命令也支持把它的输出写入到标准输出,但是它的使用是有限的,因为很少的程序能利用输出。 不幸地是,这个 unzip 程序,不接受标准输入。这就阻止了 zip 和 unzip 一块使用,像 tar 命令那样, 来复制网络上的文件。
yry@ubuntu:~$ ls -l /etc/ | zip ls-etc.zip -
adding: - (deflated 80%)
我们讨论了一些 zip/unzip 可以完成的基本操作。它们两个都有许多选项,其增加了 命令的灵活性,虽然一些选项只针对于特定的平台。zip 和 unzip 命令的说明手册都相当不错, 并且包含了有用的实例。然而,这些程序的主要用途是为了和 Windows 系统交换文件, 而不是在 Linux 系统中执行压缩和打包操作,tar 和 gzip 程序在 Linux 系统中更受欢迎。
同步文件和目录
在类 Unix 系统的世界里,能完成此任务且 备受人们喜爱的工具是 rsync。这个程序能同步本地与远端的目录,通过使用 rsync 远端更新协议,此协议 允许 rsync 快速地检测两个目录的差异,执行最小量的复制来达到目录间的同步。
rsync options source destination
我们包括了-a 选项(递归和保护文件属性)和-v 选项(冗余输出), 来在 foo 目录中制作一个 playground 目录的镜像。当这个命令执行的时候, 我们将会看到一系列的文件和目录被复制。
yry@ubuntu:~$ rsync -av playground f00
sending incremental file list
sent 21,553 bytes received 129 bytes 43,364.00 bytes/sec
total size is 0 speedup is 0.00
正则表达式
grep [options] regex [file...]

yry@ubuntu:~/test2$ ls
dirlist-bin.txt dirlist-sbin.txt dirlist-usr-bin.txt dirlist-usr-sbin.txt
yry@ubuntu:~/test2$ grep bzip dirlist*.txt
dirlist-bin.txt:bzip2
dirlist-bin.txt:bzip2recover
#如果我们只是对包含匹配项的文件列表,而不是对匹配项本身感兴趣 的话,我们可以指定-l 选项:
yry@ubuntu:~/test2$ grep -l bzip dirlist*.txt
dirlist-bin.txt
#如果我们只想查看不包含匹配项的文件列表
yry@ubuntu:~/test2$ grep -L bzip dirlist*.txt
dirlist-sbin.txt
dirlist-usr-bin.txt
dirlist-usr-sbin.txt
元字符和原义字符
字符串“bzip”中的所有字符都是原义字符,因此 它们匹配本身
正则表达式元字符由以下字符组成:
^ $ . [ ] { } - ? * + ( ) | \
注意:正如我们所见到的,当 shell 执行展开的时候,许多正则表达式元字符,也是对 shell 有特殊 含义的字符。当我们在命令行中传递包含元字符的正则表达式的时候,把元字符用引号引起来至关重要, 这样可以阻止 shell 试图展开它们。
- . 匹配任意一个字符
我们在文件中查找包含正则表达式“.zip”的文本行。对于搜索结果,有几点需要注意一下。 注意没有找到这个 zip 程序。这是因为在我们的正则表达式中包含的圆点字符把所要求的匹配项的长度 增加到四个字符,并且因为字符串“zip”只包含三个字符,所以这个 zip 程序不匹配。
另外,如果我们的文件列表 中有一些文件的扩展名是.zip,则它们也会成为匹配项,因为文件扩展名中的圆点符号也会被看作是 “任意字符”。
# -h应用于多文件搜索,不输出文件名。
yry@ubuntu:~/test2$ grep -h '.zip' dirlist*.txt
bunzip2
bzip2
bzip2recover
gunzip
gzip
funzip
gpg-zip
mzip
preunzip
prezip
prezip-bin
unzip
unzipsfx
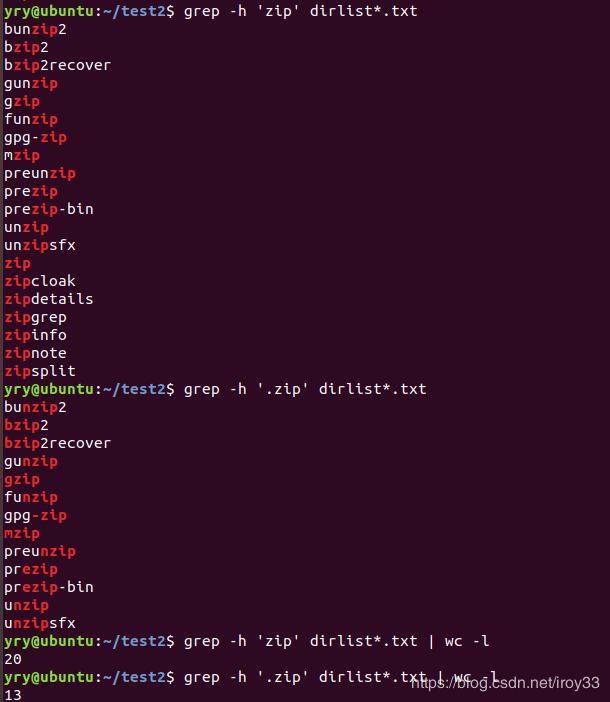
- ^锚点
^zipzip只有在文本行的开头被找到才算匹配 ;
'zip$'zip只有在文本行的末尾被找到才算匹配l;
正则表达式‘^$’(行首和行尾之间没有字符)会匹配空行。
一个 有五个字母的单词,它的第三个字母是‘j’,最后一个字母是‘r’,是哪个单词
yry@ubuntu:~/test2$ grep -i '^..j.r$' /usr/share/dict/words
Major
major
- 中括号表达式和字符类
除了能够在正则表达式中的给定位置匹配任意字符之外,通过使用中括号表达式, 我们也能够从一个指定的字符集合中匹配单个字符。
grep -h '[bg]zip' dirlist*.txt
bzip2
bzip2recover
gzip
元字符被放置到中括号里面后会失去了它们的特殊含义。然而,在两种情况下,会在中括号表达式中使用元字符,并且有着不同的含义。第一个元字符 是插入字符(^),其被用来表示否定;第二个是连字符字符(-),其被用来表示一个字符范围。
如果在中括号表示式中的第一个字符是一个插入字符(^),则剩余的字符被看作是不会在给定的字符位置出现的 字符集合
yry@ubuntu:~/test2$ grep -h '[^bg]zip' dirlist*.txt
bunzip2
gunzip
funzip
gpg-zip
mzip
preunzip
prezip
prezip-bin
unzip
unzipsfx
并且“zip”的前一个字符 是除了“b”和“g”之外的任意字符。注意文件 zip 没有被发现。一个否定的字符集仍然在给定位置要求一个字符, 但是这个字符必须不是否定字符集的成员。
yry@ubuntu:~/test2$ grep -h '^[A-Z]' dirlist*.txt
GET
HEAD
POST
VGAuthService
X
X11
Xephyr
Xorg
Xwayland
ModemManager
NetworkManager
grep -h '[-AZ]' dirlist*.txt
上面的表达式会匹配包含一个连字符,或一个大写字母“A”,或一个大写字母“Z”的文件名。
POSIX字符集

yry@ubuntu:~/test2$ ls /usr/sbin/[[:upper:]]*
/usr/sbin/ModemManager /usr/sbin/NetworkManager
#记住,然而,这不是一个正则表达式的例子,而是 shell 正在执行路径名展开操作。我们在这里展示这个例子, 是因为 POSIX 规范的字符集适用于二者。
POSIX 把正则表达式的实现分成了两类: 基本正则表达式(BRE)和扩展的正则表达式(ERE)
交替
我们把 echo 的输出管道给 grep,然后看到输出结果。当出现 一个匹配项时,我们看到它会打印出来;当没有匹配项时,我们看到没有输出结果。
yry@ubuntu:~/test2$ echo "AAA" | grep AAA
AAA
yry@ubuntu:~/test2$ echo "BBB" | grep AAA
echo "AAA" | grep -E 'AAA|BBB|CCC'
AAA
配字符串 AAA 或者是字符串 BBB
yry@ubuntu:~/test2$ echo "BBB" | grep 'AAA|BBB'
yry@ubuntu:~/test2$ echo "BBB" | grep -E 'AAA|BBB'
BBB
-E, --extended-regexp PATTERN is an extended regular expression
yry@ubuntu:~/test2$ grep -Eh '^(bz|gz|zip)' dirlist*.txt
bzcat
bzcmp
bzdiff
bzegrep
bzexe
bzfgrep
bzgrep
bzip2
bzip2recover
bzless
bzmore
gzexe
gzip
zip
zipcloak
zipdetails
zipgrep
zipinfo
zipnote
zipsplit
如果删除了(),会变成匹配任意以“bz”开头,或包含“gz”,或包含“zip”的文件名。
yry@ubuntu:~/test2$ echo "(555) 123-4567" | grep -E '^\(?[0-9][0-9][0-9]\)? [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]$'
(555) 123-4567
yry@ubuntu:~/test2$ echo "555) 123-4567" | grep -E '^\(?[0-9][0-9][0-9]\)? [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]$'
文件处理
一些命令除了接受命令行参数之外,还能够接受标准输入。
cat
其中许多选项用来帮助更好的可视化文本内容。
一个例子是-A 选项, 其用来在文本中显示非打印字符。有些时候我们想知道是否控制字符嵌入到了我们的可见文本中。 最常用的控制字符是 tab 字符(而不是空格)和回车字符,在 MS-DOS 风格的文本文件中回车符经常作为 结束符出现。另一种常见情况是文件中包含末尾带有空格的文本行。
yry@ubuntu:~$ cat > foo.txt
The quick brown fox jumped over the lazy dog.
yry@ubuntu:~$ cat foo.txt
The quick brown fox jumped over the lazy dog.
yry@ubuntu:~$ cat -A foo.txt
The quick brown fox jumped over the lazy dog.$
-n 给文本添加行号
-s 禁止输出多个空白行
yry@ubuntu:~$ cat > foo.txt
The quick brown fox
jumped over the lazy dog.
yry@ubuntu:~$ cat -ns foo.txt
1 The quick brown fox
2
3 jumped over the lazy dog.
sort
yry@ubuntu:~$ sort > foo.txt
k
ds
nij
yry@ubuntu:~$
yry@ubuntu:~$ cat foo.txt
ds
k
nij
把多个文件合并成一个有序文件
sort file1.txt file2.txt file3.txt > final_sorted_list.txt
du 命令可以 确定最大的磁盘空间用
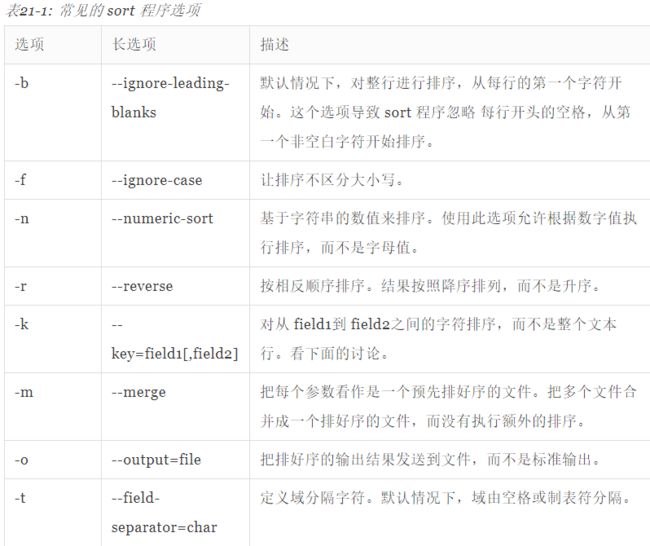
我们看一下 -n 选项,被用做数值排序。
yry@ubuntu:~$ du -s /usr/share/* | sort -nr | head
173884 /usr/share/fonts
85336 /usr/share/icons
76640 /usr/share/doc
40940 /usr/share/ibus
39376 /usr/share/libreoffice
37792 /usr/share/help
37360 /usr/share/backgrounds
34772 /usr/share/locale
34604 /usr/share/man
31796 /usr/share/vim
# -k 5指定field=5 对第5列按照大小排序
ls -l /usr/bin | sort -nr -k 5 | head
sort程序把此行看作两个字段
William Shotts
sort --key=1,1 --key=2n distros.txt
们使用了选项的长格式,但是 -k 1,1 -k 2n 格式是等价的。我们指定了 1,1, 意味着“始于并且结束于第一个字段。”在第二个实例中,我们指定了 2n,意味着第二个字段是排序的键值, 并且按照数值排序。
sort -k 3.7nbr -k 3.1nbr -k 3.4nbr distros.txt
Fedora 10 11/25/2008
Ubuntu 8.10 10/30/2008
SUSE 11.0 06/19/2008
通过指定 -k 3.7,我们指示 sort 程序使用一个排序键值,其始于第三个字段中的第七个字符,对应于 年的开头。同样地,我们指定 -k 3.1和 -k 3.4来分离日期中的月和日。 我们也添加了 n 和 r 选项来实现一个逆向的数值排序。这个 b 选项用来删除日期字段中开头的空格( 行与行之间的空格数迥异,因此会影响 sort 程序的输出结果)。
# 通过-t来定义分隔符
sort -t ':' -k 7 /etc/passwd | head
root:x:0:0:root:/root:/bin/bash
yry:x:1000:1000:gogo_linux,,,:/home/yry:/bin/bash
gdm:x:121:125:Gnome Display Manager:/var/lib/gdm3:/bin/false
gnome-initial-setup:x:120:65534::/run/gnome-initial-setup/:/bin/false
hplip:x:118:7:HPLIP system user,,,:/var/run/hplip:/bin/false
speech-dispatcher:x:111:29:Speech Dispatcher,,,:/var/run/speech-dispatcher:/bin/false
whoopsie:x:112:117::/nonexistent:/bin/false
sync:x:4:65534:sync:/bin:/bin/sync
_apt:x:104:65534::/nonexistent:/usr/sbin/nologin
avahi-autoipd:x:106:112:Avahi autoip daemon,,,:/var/lib/avahi-autoipd:/usr/sbin/nologin
uniq
输入必须是排好序的数据
sort foo.txt | uniq
切片和切块
从文本行中抽取文本,并把其输出到标准输出。它能够接受多个文件参数或者 标准输入。
cut能提取某个字段
paste
添加一个或多个文本列到文件中。通过读取多个文件,然后把每个文件中的字段整合成单个文本流,输入到标准输出。 paste 接受多个文件参数和 / 或标准输入
join
它会往文件中添加列,但是它使用了独特的方法来完成。 一个 join 操作通常与关系型数据库有关联,在关系型数据库中来自多个享有共同关键域的表格的 数据结合起来,得到一个期望的结果。这个 join 程序执行相同的操作。它把来自于多个基于共享 关键域的文件的数据结合起来。
comm 逐行比较两个有序的文件
diff 逐行比较文件
软件开发员经常使用 diff 程序来检查不同程序源码 版本之间的更改,diff 能够递归地检查源码目录,经常称之为源码树。diff 程序的一个常见用例是 创建 diff 文件或者补丁,它会被其它程序使用,例如 patch 程序(我们一会儿讨论),来把文件 从一个版本转换为另一个版本。
yry@ubuntu:~$ diff -c file1.txt file2.txt
*** file1.txt 2020-02-21 16:27:10.435731730 +0800
--- file2.txt 2020-02-21 16:27:19.875952537 +0800
***************
*** 1,4 ****
- a # 这一行在第一个文件中有,第二个文件中没有
b # 前面是空白,不表示两个文件建的差异
c
d
--- 1,4 ----
b
c
d
+ e # 第一个文件中没有,第二个文件中有
#简短格式
yry@ubuntu:~$ diff -u file1.txt file2.txt
--- file1.txt 2020-02-21 16:27:10.435731730 +0800
+++ file2.txt 2020-02-21 16:27:19.875952537 +0800
@@ -1,4 +1,4 @@
-a
b
c
d
+e
patch 给原始文件打补丁
这个 patch 程序被用来把更改应用到文本文件中。它接受从 diff 程序的输出,并且通常被用来 把较老的文件版本转变为较新的文件版本。让我们考虑一个著名的例子。Linux 内核是由一个 大型的,组织松散的贡献者团队开发而成,这些贡献者会提交固定的少量更改到源码包中。 这个 Linux 内核由几百万行代码组成,虽然每个贡献者每次所做的修改相当少。对于一个贡献者 来说,每做一个修改就给每个开发者发送整个的内核源码树,这是没有任何意义的。相反, 提交一个 diff 文件。一个 diff 文件包含先前的内核版本与带有贡献者修改的新版本之间的差异。 然后一个接受者使用 patch 程序,把这些更改应用到他自己的源码树中。使用 diff/patch 组合提供了 两个重大优点:
一个 diff 文件非常小,与整个源码树的大小相比较而言。
一个 diff 文件简洁地显示了所做的修改,从而允许程序补丁的审阅者能快速地评估它
-a, --text treat all files as text
-u, -U NUM, --unified[=NUM] output NUM (default 3) lines of unified context
-r, --recursive recursively compare any subdirectories found
-N, --new-file treat absent files as empty
yry@ubuntu:~$ diff -Naur file1.txt file2.txt > patchfile.txt
yry@ubuntu:~$ cat patchfile.txt
--- file1.txt 2020-02-21 16:27:10.435731730 +0800
+++ file2.txt 2020-02-21 16:27:19.875952537 +0800
@@ -1,4 +1,4 @@
-a
b
c
d
+e
yry@ubuntu:~$ patch < patchfile.txt
patching file file1.txt
yry@ubuntu:~$ cat file1.txt
b
c
d
e
在这个例子中,我们创建了一个名为 patchfile.txt 的 diff 文件,然后使用 patch 程序, 来应用这个补丁。注意我们没有必要指定一个要修补的目标文件,因为 diff 文件(在统一模式中)已经 在标题行中包含了文件名。一旦应用了补丁,我们能看到,现在 file1.txt 与 file2.txt 文件相匹配了。
tr
我们对于文本编辑器的经验是它们主要是交互式的,意思是我们手动移动光标,然后输入我们的修改。 然而,也有非交互式的方法来编辑文本。有可能,例如,通过单个命令把一系列修改应用到多个文件中。
echo "lowercase letters" | tr a-z A-Z
LOWERCASE LETTERS
tr 命令操作标准输入,并把结果输出到标准输出。tr 命令接受两个参数:要被转换的字符集以及 相对应的转换后的字符集。
- 枚举列表。例如, ABCDEFGHIJKLMNOPQRSTUVWXYZ
- 字符域。例如,A-Z 。注意这种方法有时候面临与其它命令相同的问题,归因于 语系的排序规则,因此应该谨慎使用。
- POSIX 字符类。例如,[:upper:]
yry@ubuntu:~$ echo "lo9787wercase letters" | tr [:lower:] A
AA9787AAAAAAA AAAAAAA
-d, --delete delete characters in SET1, do not translate
#转换 MS-DOS 文本文件为 Unix 风格文本的问题。为了执行这个转换,每行末尾的回车符需要被删除。 这个可以通过 tr 命令来执行
tr -d '\r' < dos_file > unix_file
使用-s 选项,tr 命令能“挤压”重复的字符实例,不相邻则不行
yry@ubuntu:~$ echo "aaabbbccc" | tr -s ab
abccc
yry@ubuntu:~$ echo "abbbaccc" | tr -s ab
abaccc
sed 用于筛选和转换文本的流编辑器
aspell 交互式拼写检查器
格式化输出
printf 并不用于流水线执行(不接受标准输入)。在命令行中,它也鲜有运用(它通常被用于自动执行指令中)。所以为什么它如此重要?因为它被广泛使用。
在 bash 中, printf 是内置的。 printf 这样工作:
printf “format” arguments
yry@ubuntu:~$ printf "I formatted '%s' as a string.\n" foo
I formatted 'foo' as a string.
yry@ubuntu:~$ printf "I formatted '%s' as a string.\n" 'foo'
I formatted 'foo' as a string.
![]()
编译程序
make
编译就是把源码(一个由程序员编写的人类可读的程序的说明)翻译成计算机处理器的语言的过程。用高级语言编写的程序,经过另一个称为编译器的程序的处理,会转换成机器语言。一些编译器把 高级指令翻译成汇编语言,然后使用一个汇编器完成翻译成机器语言的最后阶段。
大多数程序通过一个简单的,两个命令的序列构建:
./configure
make
这个 configure 程序是一个 shell 脚本,由源码树提供。它的工作是分析程序构建环境。大多数源码会设计为可移植的。 也就是说,它被设计成能够在不止一种类 Unix 系统中进行构建。但是为了做到这一点,在建立程序期间,为了适应系统之间的差异, 源码可能需要经过轻微的调整。configure 也会检查是否安装了必要的外部工具和组件。让我们运行 configure 命令。 因为 configure 命令所在的位置不是位于 shell 通常期望程序所呆的地方,我们必须明确地告诉 shell 它的位置,通过 在命令之前加上 ./ 字符,来表明程序位于当前工作目录
Makefile 是一个配置文件, 指示 make 程序究竟如何构建程序。没有它,make 程序就不能运行。Makefile 是一个普通文本文件,所以我们能查看它
这个 make 程序把一个 makefile 文件作为输入(通常命名为 Makefile),makefile 文件 描述了包括最终完成的程序的各组件之间的关系和依赖性。