tensorflow学习(5)之CNN
莫凡2017tensorflow(使用更简便版)https://github.com/MorvanZhou/Tensorflow-Tutorial
CNN卷积神经网络(Convolutional Neural Networks)
https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/5-03-A-CNN/
在前面的分类学习中(17),MNIST库求出的精确度达到87%多,这个准确率对于目前的技术来说相对较低。如果想要提升准确率,就要用到CNN,可达到96%。
卷积神经网络是近些年逐步兴起的一种人工神经网络结构, 因为利用卷积神经网络在图像和语音识别方面能够给出更优预测结果, 这一种技术也被广泛的传播可应用. 卷积神经网络最常被应用的方面是计算机的图像识别。
我们先把卷积神经网络这个词拆开来看. “卷积” 和 “神经网络”. 卷积也就是说神经网络不再是对每个像素的输入信息做处理了,而是图片上每一小块像素区域进行处理, 这种做法加强了图片信息的连续性. 使得神经网络能看到图形, 而非一个点. 这种做法同时也加深了神经网络对图片的理解. 具体来说, 卷积神经网络有一个批量过滤器, 持续不断的在图片上滚动收集图片里的信息,每一次收集的时候都只是收集一小块像素区域, 然后把收集来的信息进行整理, 这时候整理出来的信息有了一些实际上的呈现。
如果是彩色照片, 就可能有红绿蓝三种颜色的信息, 这时的高度为3. 我们以彩色照片为例子. 过滤器就是影像中不断移动的东西, 他不断在图片收集小批小批的像素块, 收集完所有信息后, 输出的值, 我们可以理解成是一个高度更高,长和宽更小的”图片”. 这个图片里就能包含一些边缘信息. 然后以同样的步骤再进行多次卷积, 将图片的长宽再压缩, 高度再增加, 就有了对输入图片更深的理解. 将压缩,增高的信息嵌套在普通的分类神经层上,我们就能对这种图片进行分类了.
卷积神经网络包含输入层、隐藏层和输出层,隐藏层又包含卷积层和池化(pooling)层,图像输入到卷积神经网络后通过卷积来不断的提取特征,每提取一个特征就会增加一个feature map,所以会看到视频教程中的立方体不断的增加厚度,那么为什么厚度增加了但是却越来越瘦了呢,哈哈这就是pooling层的作用喽,pooling层也就是下采样(图像尺寸减半),通常采用的是最大值pooling和平均值pooling,因为参数太多喽,所以通过pooling来稀疏参数,使我们的网络不至于太复杂。
padding:决定在进行卷积或池化操作时,是否对输入的图像矩阵边缘补0,'SAME' 为补零,'VALID' 则不补,其原因是因为在这些操作过程中过滤器可能不能将某个方向上的数据刚好处理完。也就是说,决定卷积后的长宽是否要与原图一致。
pooling:池化层又称下采样,它的作用是减小数据处理量同时保留有用信息。池化层的作用可以描述为模糊图像,丢掉了一些不是那么重要的特征.(https://www.cnblogs.com/fydeblog/p/7450413.html)
tf.nn.max_pool()最大池化
tf.nn.avg_pool平均池化
(https://www.cnblogs.com/White-xzx/p/9497029.html)
- 池化(pooling)

研究发现, 在每一次卷积的时候, 神经层可能会无意地丢失一些信息. 这时, 池化 (pooling) 就可以很好地解决这一问题. 而且池化是一个筛选过滤的过程, 能将 layer 中有用的信息筛选出来, 给下一个层分析. 同时也减轻了神经网络的计算负担 (具体细节参考). 也就是说在卷积的时候, 我们不压缩长宽, 尽量地保留更多信息, 压缩的工作就交给池化了,这样的一项附加工作能够很有效的提高准确性. 有了这些技术,我们就可以搭建一个属于我们自己的卷积神经网络啦.
- 流行的CNN结构
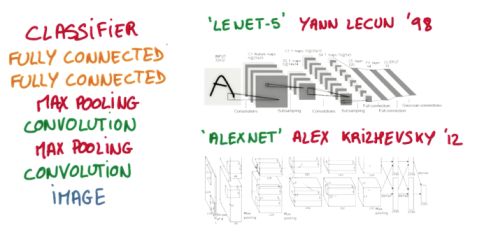
比较流行的一种搭建结构是这样, 从下到上的顺序, 首先是输入的图片(image), 经过一层卷积层 (convolution), 然后在用池化(pooling)方式处理卷积的信息, 这里使用的是 max pooling 的方式. 然后在经过一次同样的处理, 把得到的第二次处理的信息传入两层全连接的神经层 (fully connected),这也是一般的两层神经网络层,最后在接上一个分类器(classifier)进行分类预测. 这仅仅是对卷积神经网络在图片处理上一次简单的介绍.
"""
Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly.
"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# number 1 to 10 data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
def compute_accuracy(v_xs, v_ys):
global prediction
y_pre = sess.run(prediction, feed_dict={xs: v_xs, keep_prob: 1})
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(v_ys,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys, keep_prob: 1})
return result
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
# stride [1, x_movement, y_movement, 1]
# Must have strides[0] = strides[3] = 1
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
# stride [1, x_movement, y_movement, 1]
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
# define placeholder for inputs to network
xs = tf.placeholder(tf.float32, [None, 784]) # 28x28
ys = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
x_image = tf.reshape(xs, [-1, 28, 28, 1])
# print(x_image.shape) # [n_samples, 28,28,1]
## conv1 layer ##
W_conv1 = weight_variable([5,5, 1,32]) # patch 5x5, in size 1, out size 32
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # output size 28x28x32
h_pool1 = max_pool_2x2(h_conv1) # output size 14x14x32
## conv2 layer ##
W_conv2 = weight_variable([5,5, 32, 64]) # patch 5x5, in size 32, out size 64
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # output size 14x14x64
h_pool2 = max_pool_2x2(h_conv2) # output size 7x7x64
## func1 layer ##
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
# [n_samples, 7, 7, 64] ->> [n_samples, 7*7*64]
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
## func2 layer ##
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# the error between prediction and real data
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
sess = tf.Session()
# important step
sess.run(tf.initialize_all_variables())
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: 0.5})
if i % 50 == 0:
print(compute_accuracy(
mnist.test.images, mnist.test.labels))
'''
部分结果如下:
2019-04-12 15:19:39.539000: W T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation of 1003520000 exceeds 10% of system memory.
0.0984
2019-04-12 15:19:55.002000: W T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation of 1003520000 exceeds 10% of system memory.
0.7757
2019-04-12 15:20:09.438000: W T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation of 1003520000 exceeds 10% of system memory.
0.8684
2019-04-12 15:20:23.888000: W T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation of 1003520000 exceeds 10% of system memory.
0.9047
可见准确率越来越高,且超过90%
'''分步详解:
我们定义Weight变量,输入shape,返回变量的参数。其中我们使用tf.truncted_normal产生随机变量来进行初始化:
tf.truncted_normal(shape, mean, stddev) :shape表示生成张量的维度,mean是均值,stddev是标准差。这个函数产生正态分布,均值和标准差自己设定。
def weight_variable(shape):
inital=tf.truncted_normal(shape,stddev=0.1)
return tf.Variable(initial)同样的定义biase变量,输入shape ,返回变量的一些参数。其中我们使用tf.constant常量函数来进行初始化:
def bias_variable(shape):
initial=tf.constant(0.1,shape=shape)
return tf.Variable(initial)定义卷积,tf.nn.conv2d函数是tensoflow里面的二维的卷积函数,x是图片的所有参数,W是此卷积层的权重,然后定义步长strides=[1,1,1,1]值,strides[0]和strides[3]的两个1是默认值,中间两个1代表padding时在x方向运动一步,y方向运动一步,padding采用的方式是SAME。
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME') 接着定义池化pooling,为了得到更多的图片信息,padding时我们选的是一次一步,也就是strides[1]=strides[2]=1,这样得到的图片尺寸没有变化,而我们希望压缩一下图片也就是参数能少一些从而减小系统的复杂度,因此我们采用pooling来稀疏化参数,也就是卷积神经网络中所谓的下采样层。pooling 有两种,一种是最大值池化,一种是平均值池化,本例采用的是最大值池化tf.max_pool()。池化的核函数大小为2x2,因此ksize=[1,2,2,1],步长为2,因此strides=[1,2,2,1]:
def max_poo_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1])图片处理
首先定义一下输入的placeholder
xs=tf.placeholder(tf.float32,[None,784])
ys=tf.placeholder(tf.float32,[None,10])我们还定义了dropout的placeholder,它是解决过拟合的有效手段
keep_prob=tf.placeholder(tf.float32)接着呢,我们需要处理我们的xs,把xs的形状变成[-1,28,28,1],-1代表先不考虑输入的图片例子多少这个维度,后面的1是channel的数量,因为我们输入的图片是黑白的,因此channel是1,例如如果是RGB图像,那么channel就是3。
x_image=tf.reshape(xs,[-1,28,28,1])建立卷积层
接着我们定义第一层卷积,先定义本层的Weight,本层我们的卷积核patch的大小是5x5,因为黑白图片channel是1所以输入是1,输出是32个featuremap
W_conv1=weight_variable([5,5,1,32])接着定义bias,它的大小是32个长度,因此我们传入它的shape为[32]
b_conv1=bias_variable([32])定义好了Weight和bias,我们就可以定义卷积神经网络的第一个卷积层h_conv1=conv2d(x_image,W_conv1)+b_conv1,同时我们对h_conv1进行非线性处理,也就是激活函数来处理喽,这里我们用的是tf.nn.relu(修正线性单元)来处理,要注意的是,因为采用了SAME的padding方式,输出图片的大小没有变化依然是28x28,只是厚度变厚了,因此现在的输出大小就变成了28x28x32
h_conv1=tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1)最后我们再进行pooling的处理就ok啦,经过pooling的处理,输出大小就变为了14x14x32
h_pool=max_pool_2x2(h_conv1)接着呢,同样的形式我们定义第二层卷积,本层我们的输入就是上一层的输出,本层我们的卷积核patch的大小是5x5,有32个featuremap所以输入就是32,输出呢我们定为64
W_conv2=weight_variable([5,5,32,64])
b_conv2=bias_variable([64])接着我们就可以定义卷积神经网络的第二个卷积层,这时的输出的大小就是14x14x64
h_conv2=tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2)最后也是一个pooling处理,输出大小为7x7x64
建立全连接层
接下来我们定义我们的 fully connected layer,进入全连接层时, 我们通过tf.reshape()将h_pool2的输出值从一个三维的变为一维的数据, -1表示先不考虑输入图片例子维度, 将上一个输出结果展平.
#[n_samples,7,7,64]->>[n_samples,7*7*64]
h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64]) 此时weight_variable的shape输入就是第二个卷积层展平了的输出大小: 7x7x64, 后面的输出size我们继续扩大,定为1024
W_fc1=weight_variable([7*7*64,1024])
b_fc1=bias_variable([1024])然后将展平后的h_pool2_flat与本层的W_fc1相乘(注意这个时候不是卷积了)
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1)如果我们考虑过拟合问题,可以加一个dropout的处理
h_fc1_drop=tf.nn.dropout(h_fc1,keep_drop)接下来我们就可以进行最后一层的构建了,好激动啊, 输入是1024,最后的输出是10个 (因为mnist数据集就是[0-9]十个类),prediction就是我们最后的预测值
W_fc2=weight_variable([1024,10]) b_fc2=bias_variable([10])然后呢我们用softmax分类器(多分类,输出是各个类的概率),对我们的输出进行分类
prediction=tf.nn.softmax(tf.matmul(h_fc1_dropt,W_fc2),b_fc2)优选化方法
接着呢我们利用交叉熵损失函数来定义我们的cost function
cross_entropy=tf.reduce_mean(
-tf.reduce_sum(ys*tf.log(prediction),
reduction_indices=[1]))我们用tf.train.AdamOptimizer()作为我们的优化器进行优化,使我们的cross_entropy最小
train_step=tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)接着呢就是和之前视频讲的一样喽 定义Session
sess=tf.Session()初始化变量
# tf.initialize_all_variables() 这种写法马上就要被废弃
# 替换成下面的写法:
sess.run(tf.global_variables_initializer())好啦接着就是训练数据啦,我们假定训练1000步,每50步输出一下准确率, 注意sess.run()时记得要用feed_dict给我们的众多 placeholder 喂数据哦.