【python自动化办公(10)】python利用pdfplumber库提取PDF文字以及表格内容(复杂表格字段数据的处理)
利用pdfplumber提取文字
pdfplumber.open(pdf路径)/pdf.pages[页数]/page.extract_text()
import os
os.chdir('D:\\python_major\\auto_office10')
import pdfplumber
with pdfplumber.open("Netease Q2 2019 Earnings Release-Final.pdf") as pdf:
first_page = pdf.pages[0]
print(first_page.extract_text())
–> 输出结果为:该pdf第一页的文字内容
利用pdfplumber提取表格
import os
os.chdir('D:\\python_major\\auto_office10')
import pdfplumber
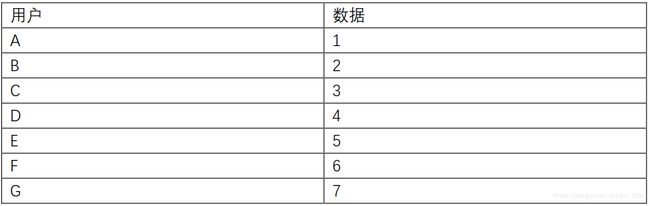
with pdfplumber.open("simple_data.pdf") as pdf:
first_page = pdf.pages[0]
print(first_page.extract_table())
–> 输出结果为:[[‘用户’, ‘数据’], [‘A’, ‘1’], [‘B’, ‘2’], [‘C’, ‘3’], [‘D’, ‘4’], [‘E’, ‘5’], [‘F’, ‘6’], [‘G’, ‘7’]](下面为原图表)
利用pdfplumber提取多个简单的表格
page.extract_tables()
import os
os.chdir('D:\\python_major\\auto_office10')
import pdfplumber
with pdfplumber.open("simple_data.pdf") as pdf:
table_page = pdf.pages[0]
for table in table_page.extract_tables():
print(table)
多个表格的提取就是对所有的表格进行遍历,然后一次输出
表格提取设定 table_setting是extract_tables()的参数
{
'vertical_strategy':"lines",
"horizontal_strategy":"lines",
"explicit_vercital_lines":[],
"explicit_horizontal_lines":[],
"snap_tolerance":3,
"join_tolerance":3,
"edge_min_length":3,
"min_words_vertical":3,
"min_words_horizontal":1,
"keep_blank_chars":False,
"text_tolerance":3,
"text_x_tolerance",None。
"text_y_tolerance",None,
"intersection_tolerance":3,
"intersection_x_tolerance":None,
"intersection_y_tolerance":None,
}
比如提取pdf里面的中间表格----网易的2019年Q2季度报表第十页(对应索引编号为9)如下:
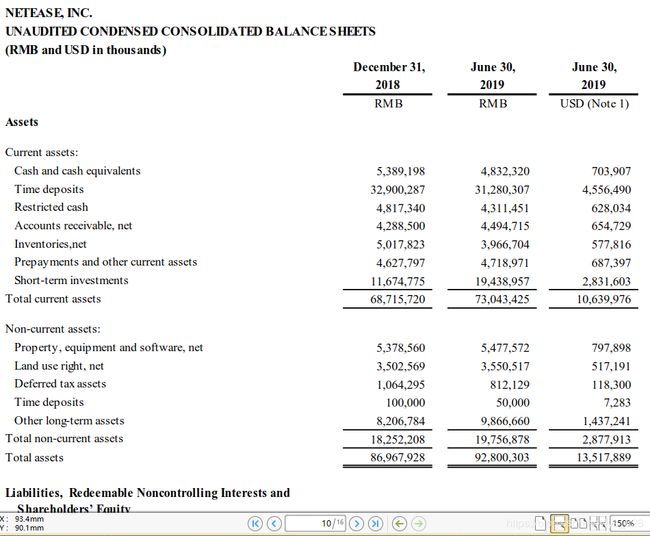
如果按照之前一般的提取表格的方式,也就是上面的代码,将索引0改成9
```python
import os
os.chdir('D:\\python_major\\auto_office10')
import pdfplumber
with pdfplumber.open("simple_data.pdf") as pdf:
table_page = pdf.pages[9]
print(table_page.extract_table())
–> 输出结果为: IndexError: list index out of range
这时候就需要设置一下.extract_table()方法里面的参数了
import os
os.chdir('D:\\python_major\\auto_office10')
import pdfplumber
with pdfplumber.open("Netease Q2 2019 Earnings Release-Final.pdf") as pdf:
table_page = pdf.pages[9]
table = table_page.extract_table(
table_settings = {
'vertical_strategy':"text",
"horizontal_strategy":"text",}
)
print(table)
–> 输出结果为:

将获取的数据写到Excel中
如果对于前面两次的作业有亲自练习的话,这里向Excel中写入数据,就沿袭了python自动化(7)里只用python列表写入数据,上次综合应用里面还特地讲了字典计数和目标数据的格式转化。遗忘的可以再回顾一下
from openpyxl import Workbook
workbook = Workbook()
sheet = workbook.active
for row in table:
sheet.append(row)
workbook.save(filename = "Netease Q2 2019 Earnings Release-Final.xlsx")
–> 输出结果为:
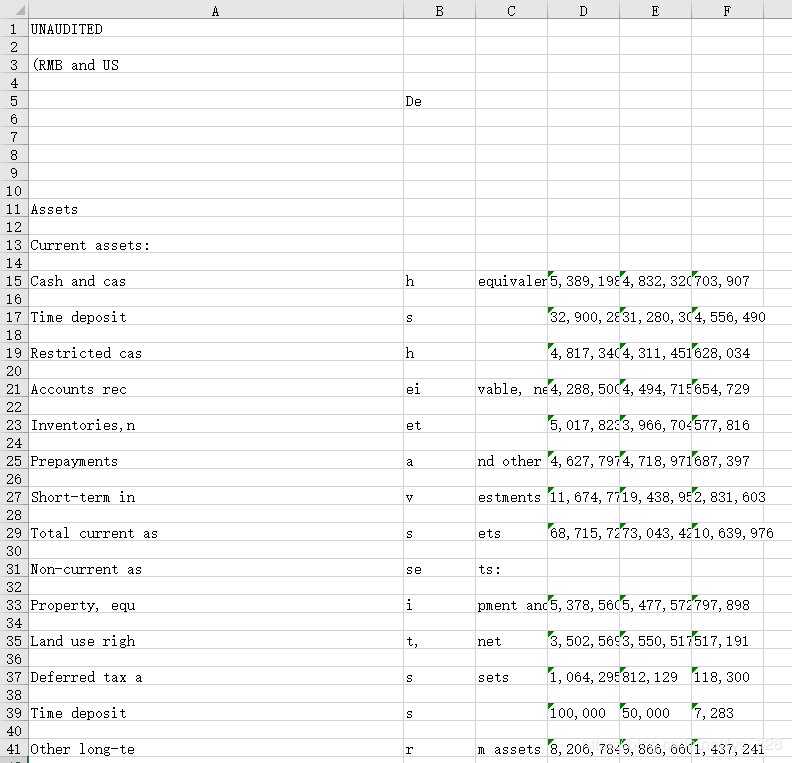
由上输出可知:存在空行和将单词切分到多个不同列的问题
去除空行
简单判断,非空行的才加起来,将列表中每一个元素都连接成一个字符串,如果还是一个空字符串那么肯定就是空行
new_table = []
for row in table:
if not "".join([str(item) for item in row]) == "":
这里涉及到了两个新的知识点,一个是字符串的.join()方法,还有一个就是列表推导式(生成式),在之前的综合应用中也有提到(python自动化办公(6))。其中join方法处理的是字符串,也就是加引号的对象,以什么形式拼合就是看.前面的""中规定的样式,常常配合着循环语句使用。关于列表推导式,也可以成为列表生成式,不同的人叫法不一样,但是在之后的代码中,要用的for循环的,尽量想着用列表推导式怎么完成,只有这样做,这种方法才可能真正的记在心上,成为自己的书写习惯,再往后的学习工作上也将大大的减少代码量和提高效率。
下面这个代码可以背下来,日后很有用的,完成的功能就是将列表中的元素变成字符串
"".join([str(item) for item in row])
将多窗格数据合并成单窗格数据
运行去除空行的代码,然后重新把数据写入
workbook = Workbook()
sheet = workbook.active
for row in table:
if not "".join([str(item) for item in row])== "":
sheet.append(row)
workbook.save(filename = "Netease Q2 2019 Earnings Release-Final.xlsx")
–> 输出结果为:
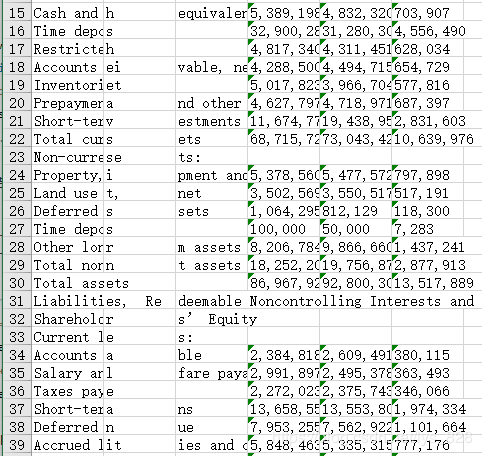
这里加入上一部分代码后,发现所有的字符(非数字)都是在前三列,然后就可以对前三行进行数据连接,将三个窗格的数据合并为一个窗格,以下代码就是实现将前三行非None的内容合并为一个字符串,然后合并到一个列表里面
new_row = []
new_row.append("".join([str(item) if item else "" for item in row[:3]]))
new_row += row[3:]
new_table.append(new_row)
这里的行内条件判断,也是属于列表推导式里的内容,就是为了方便做判断,直接移植到列表推导式中。可以理解为既然遍历循环可以放到列表中,那么判断的语句也是可以的,这就是人类懒的本质,怎么快捷,怎么方便怎么来!
全部代码如下:
import os
os.chdir('D:\\python_major\\auto_office10')
import pdfplumber
from openpyxl import Workbook
with pdfplumber.open("Netease Q2 2019 Earnings Release-Final.pdf") as pdf:
table_page = pdf.pages[9]
table = table_page.extract_table(
table_settings = {
'vertical_strategy':"text",
"horizontal_strategy":"text",}
)
workbook = Workbook()
sheet = workbook.active
for row in table:
if not "".join([str(item) for item in row])== "":
new_row = []
new_row.append("".join([str(item) if item else "" for item in row[:3]]))
new_row += row[3:]
sheet.append(new_row)
workbook.save(filename = "Netease Q2 2019 Earnings Release-Final.xlsx")
–> 输出结果为:
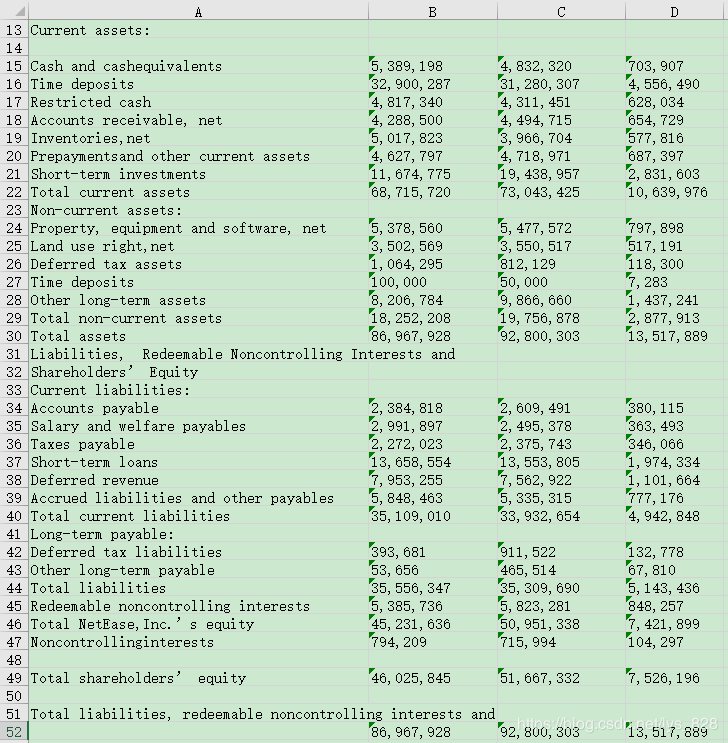
综合应用
编写一个Python程序,要求
(1)打开文件Netease Q2 2019 Earnings Release-Final.pdf
(2)提取第14页的表格
(3)保存到Netease Q2 2019 Earnings Release-Final.xlsx文件中
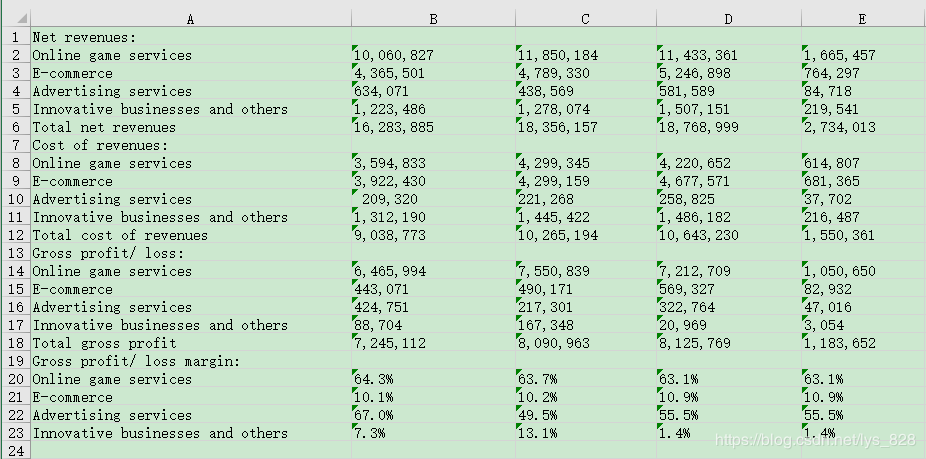
尝试这个将索引里面的9改成13,显然输出的数据结果不满足要求,因此部分代码需要重新编写,也说明针对pdf内容的读取并没有千篇一律的方式,学会的只是一种读取的方式,具体的读取规则需要根据文件的格式和录入文件数据的格式进行修改,直至达到自己满意的程度
下面就是要获取数据的pdf里面的表格
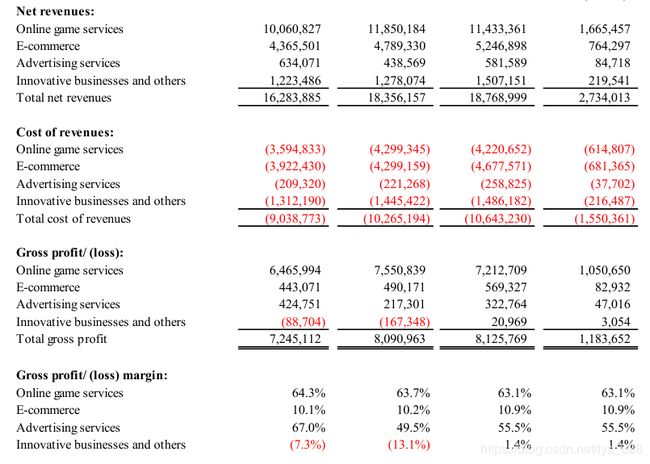
将9改成13后输出的结果为
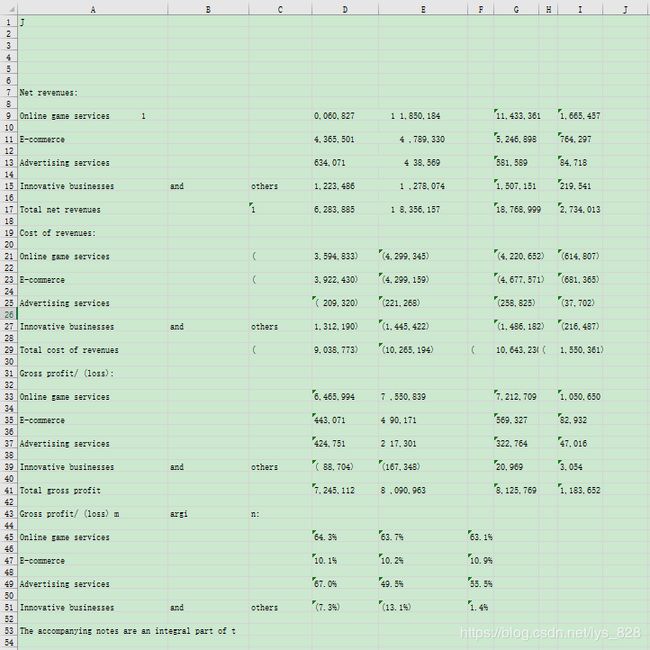
思路梳理
首先,参照原数据,可以发现获取的数据几乎都可以完全的对应上,因此只要对获得的数据进行处理即可,处理的方式,我采用的是先整字符数据,在搞数值内容,最后在处理格式或样式
第一步、前期准备
import os
os.chdir('D:\\python_major\\auto_office10')
import pdfplumber
from openpyxl import Workbook
workbook = Workbook()
sheet = workbook.active
该部分代码完成的功能是:设置程序运行路径、导入相关的库和加载原文件数据和创建新文件表单
第二步、提取表格数据
with pdfplumber.open("Netease Q2 2019 Earnings Release-Final.pdf") as pdf:
table_page = pdf.pages[13]
table = table_page.extract_table(
table_settings = {
'vertical_strategy':"text",
"horizontal_strategy":"text",
}
)
这一步和上面的代码一致,只是将9换成了13
第三步、表格数据进行处理
步骤分解一、删除没有用的数据
通过查看生成的Excel文件数据可知,表头前面几行没有数据,最后一行的数据缺失 ,而且不是我们要求的数据,对这一部分的数据进行删除
del table[:6]
del table[-1]
–> 输出结果为:删除了前6行和最后一行
步骤分解二、对字符、空值以及空行进行处理
通过步骤一之后生成的table数据如下,接下来步骤最重要的就在于自己 调试的过程
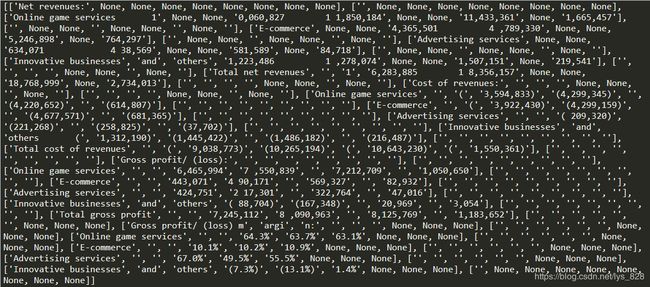
按照视频的思路,先整理字符的问题,可以发现字符的问题都是部分单词未分割完全,都是在前三列。
注意①:其中and others是两个单词进行外部拆分的,而还有一个是将单词进行内部拆分了,这里的处理方式不能直接进行空格合并,而是要分开来处理
注意②:字符处理完成之后,要进行空值以及空行的处理,视频演示上我们不要忽视了最终输出的Excel数据的第48和50行是空行,虽然用代码进行空行的处理,但是没有清理完全,需要对代码进行完善,或者借用上面的方法重新写代码。研究输出的table数据,可以发现空行的标志不是仅仅只用""的数据,有的还有None数据,从而导致了,即使采用上面的代码处理,结果还是输出的有空行
注意③:浏览上面输出的Excel数据,发现括号是一个很让人头疼的问题,这里我采用的是直接将这些不规则出现的括号全部去除,最后如果有需求可以对该部分的数据进行遍历循环,进行format格式化输出即可,至于颜色的问题,也是同理在进行遍历的格式化的时候也可以进行cell.font的设置,具体的操作可以参考之前的文章总结,这里不再进行这两个操作
new_table = []
for row in table:
if 'and' in row:
row = [" ".join(str(x) for x in row[:3])] + row[3:]
if 'argi' in row:
row = ["".join(str(x) for x in row[:3])]
#上面代码是对字符数据的分开处理
new_row = [x.replace("(","") for x in row if (x != None) and (x != "")]
#空行的特征是列表数据中只有None或指""数据,因此有数据的列表就直接取反就行了,顺带进行括号的去除
if len(new_row) != 0:
new_row = [x.replace(")","") for x in new_row if x != ""]
#这里把真正的空行给去除,而且把左右括号全部去除,返回的是一个新列表
new_table.append(new_row)
这一部分代码完成了字符数据的分开处理,对于空值和空行的处理,顺带去掉了左右空格,最后生成了一个新的列表数据
–> table数据输出结果为:
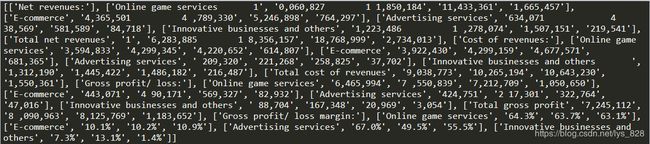
–>存入Excel文件数据输出结果为:
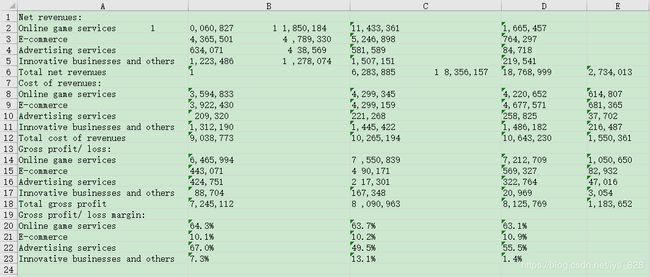
步骤分解三、对数值数据进行处理
注意①:A2格子中存在着数字1,B6格子里存在数字1
注意②:第2-6行的数值里面都存在两个数据合并成为一个数据的现象
注意③:第14-18中每行中都存在格式问题(多余的空格,第10行也有一个,2-6行的空格在处理注意②的时候直接处理)
注意④:第20-23行的第五列数据缺失
new_table[1] = [new_table[1][0].split(" ")[0]] + ["".join((str(new_table[1][0].split(" ")[1]),new_table[1][1],))] + new_table[1][2:]
new_table[5] = [new_table[5][0]] + ["".join((str(new_table[5][1]),new_table[5][2]))] + new_table[5][3:]
#上面的代码就是按照空格将A2和B6里面的数据进行拆分,然后把数据重新组合,生成新的第2行和第六行数据
–> 输出结果为:
![]()
接下来就是进行2-6行里面的数据拆分,顺带着把里面的空格进行去除,为了避免写五条.split()语句,建议进行创建列表进行遍历循环(2-6行里面的空格数量并不是一样长度的)
space_ls = [' ',' ',' ',' ',' ']
for i in range(5):
ls_loc_1_2 = new_table[i+1][1].split(space_ls[i])
#三行代码实现五行split语句的效果,将合并数据拆分
new_table[i+1][1] = ls_loc_1_2[0]
new_table[i+1].insert(2, ls_loc_1_2[1].replace(" ",""))
#这两行代码是将拆分的数据替换原列表的第二个值(就是那个合并的值),然后在第三个位置(索引坐标为2)插入第三个数值,顺带把空格去除
–> 输出结果为:

接下来就是去除第14-18中空格问题(第10行有一个,一样的方式),两行代码就可以搞定,当然这个在Excel里面使用替换的功能也可以完成,但是会破坏整体的格式(存入的是文本数据,如果直接用Excel的替换功能,数据就变成了数值数据,如果还要转换成文本数据,就需要再进行点击其他的命令了)
print("未修改之前的13-18行存在空格的数据:\n{}\n".format(new_table[13:18]))
for i in range(13,18):
new_table[i][1:3] = [x.replace(" ","") for x in new_table[i][1:3]]
print("修改之后的13-18行的数据:\n{}".format(new_table[13:18]))
–> 输出结果为:

最后是处理第23-28行缺失的数据,对比原表格,可知第五列缺失的数据和第四列是一致的,只需要将第四列的值赋予(列表插入)第五列即可
for row in new_table[-4:]:
row.insert(-1,row[-1])
–> 输出结果为:

至此,所有的数据处理工作就全部完成了,接下来就是第四步,进行结果的录入和保存Excel文件数据了
第四步、数据的录入和Excel表格文件的保存
for row in new_table:
sheet.append(row)
workbook.save(filename = "测试.xlsx")
print('finnished!')
–> 输出结果为:
finnished!
全部代码以及结果输出
import os
os.chdir('D:\\python_major\\auto_office10')
import pdfplumber
from openpyxl import Workbook
workbook = Workbook()
sheet = workbook.active
with pdfplumber.open("Netease Q2 2019 Earnings Release-Final.pdf") as pdf:
table_page = pdf.pages[13]
table = table_page.extract_table(
table_settings = {
'vertical_strategy':"text",
"horizontal_strategy":"text",
}
)
del table[:6]
del table[-1]
new_table = []
for row in table:
if 'and' in row:
row = [" ".join(str(x) for x in row[:3])] + row[3:]
if 'argi' in row:
row = ["".join(str(x) for x in row[:3])]
new_row = [x.replace("(","") for x in row if (x != None) and (x != "")]
if len(new_row) != 0:
new_row = [x.replace(")","") for x in new_row if x != ""]
new_table.append(new_row)
#print(new_table)
new_table[1] = [new_table[1][0].split(" ")[0]] + ["".join((str(new_table[1][0].split(" ")[1]),new_table[1][1],))] + new_table[1][2:]
new_table[5] = [new_table[5][0]] + ["".join((str(new_table[5][1]),new_table[5][2]))] + new_table[5][3:]
space_ls = [' ',' ',' ',' ',' ']
for i in range(5):
ls_loc_1_2 = new_table[i+1][1].split(space_ls[i])
new_table[i+1][1] = ls_loc_1_2[0]
new_table[i+1].insert(2, ls_loc_1_2[1].replace(" ",""))
#print(new_table[i])
for i in range(13,18):
new_table[i][1:3] = [x.replace(" ","") for x in new_table[i][1:3]]
for row in new_table[-4:]:
row.insert(-1,row[-1])
for row in new_table:
sheet.append(row)
workbook.save(filename = "综合应用.xlsx")
print('finnished!')
最终保存的Excel文件数据为: