你一定要知道的分布式架构演化史|干货满满
文章目录
- 一、前言
- 二、混沌初现
- 三、负载均衡器诞生
- 四、分布式架构走向成熟
- 4.1、分布式用户诞生
- 4.2、分布式系统诞生
- 五、总结
一、前言
截止到今年3月份,咱们国家的网民数量已达9.04亿。面对如此庞大的用户规模,各种微服务技术,分布式架构成为了当代程序员的必修课。随着新基建的提出,大数据中心,数据湖的概念也越来越热。那么分布式架构作为这一切技术的核心点,它又是如何演化而来的呢?下面就让我们一起追本溯源,从遥远的2001年开始说起。

二、混沌初现
在咱们互联网的最早期,用户量很少,网络速度也很慢,用单节点的服务器搭建一个网站系统没有任何问题。可是随着互联网的普及,用户量越来越多,并发负载也随着越来越高,这时候单节点的服务器就开始承受不了了。
知识点一:为什么单节点服务器承受不了高并发负载呢?
以用户登陆请求Tomcat为例,Tomcat默认的HTTP实现是采用阻塞式的Socket通信,也就是每个请求都需要创建一个线程来处理。默认Tomcat的最大请求数是150,也就是说同时支持150个并发访问。当然这是可以配置的,但是最大并发数与硬件性能和CPU数量都是有很大关系的,所以一般情况下一个进程有500个以上线程在抢夺资源的时候,整体性能就已经非常低了。所以当用户量增多,并发变大,线程越来越多,服务器就会越来越慢,我们称之为负载过大。
那么,如何解决这个问题呢?
由于单进程有最大线程数限制,同时单个server的并发是有上限的,那我们可以在服务器上多启动几个server,也就是多搞几个进程。一个server上限是1000,那我们搞2个不就是2000了吗?这就是最早期的解决方案。
以登陆为例,我们希望扩展登陆服务器的并发能力,然后综合考虑后我们选择水平扩展的方式,如下在一台服务器启动3个server,作为一个整体来处理用户登陆请求。解决后的方案雏形如下图:

但是这样又会出现一个问题:如果希望3个server都处理用户登陆请求,那这些server需要完全一样,但是我们知道进程的端口是不能重复的!也就是说三个server里面有两个要改变端口,可是对于用户来说,他们依然访问的是之前固定的端口,那两外两个server并不会被访问到。
这个问题该如何解决呢?我们接着往下看。
三、负载均衡器诞生
为了解决前面的问题,我们不能让用户直接去访问server,而是需要把用户的所有请求汇总到一起,然后把这些负载均匀的分配给这些server,负责干这件事的程序,我们命名为负载均衡器。
引入负载均衡器后,上面的问题得到了解决,到底用户的请求交给哪一个server处理,完全由负载均衡器来根据server的状态控制。改进后的架构图如下所示:

知识点二:如何做到均衡分配呢?
看到均衡分配我们就想到了散列,也就是Hash。咱们技术的世界里,很多都是相通的,均衡分配也是。比如HashMap根据key的Hash值选择对应的数组下标,把数据分配到内置的key数组上,有效的降低了过高的key冲突。再比如redis经典的16384,它把集群的内存分为16384个slots,然后在放数据的时候会根据hash计算要放入的数据对应slots的索引位置,范围是0-16383。说到slots也会想到Flink,其实技术都是相通的。
在实际的使用中,这样的架构还会遇到问题。熟悉Tomcat的小伙伴应该知道session的概念,假如用户a第一次访问咱们的服务器,然后被负载均衡器分配给了server1,用户a的一些信息存放到了server1里面。然后用户a离线,过一会再次访问咱们的服务器,这次可能被分配给了server2。我们知道server1和server2是两个不同的进程,那我们如何拿到上一次登陆时存放在server1里面的数据呢?
这就要涉及到进程间数据交互了,我们接着往下看。
四、分布式架构走向成熟
我们知道进程间数据交互是非常非常慢的,大概比线程间的交互慢了1000倍!同时互联网早期的进程间交互是存在很多问题的,在那个满是C++程序员的年代,Java程序员是非常稀有珍贵的,同时那时候的技术也是非常难的。在一批批程序员的艰难探索下,最终诞生了璀璨的新星–Spring!
知识点三:Spring是怎么诞生的?
为了解决进程间的数据通信问题,我们现在所熟知的RPC协议在2001年的时候Java工程师根据这个协议可以使用RMI规则来实现,但是由于RMI非常非常难,所以那时候会RMI的Java工程师可以说是千里挑一,薪资自然也高,可以拿到2万每月,要知道那时候北京每平米的房价也只有1000多块钱!也正是因为这样,在2001开始Java被越来越多的人重视,开始登上历史舞台,持续至今。
但是由于RMI实在太难了,不利于推广,所以后来sun公司基于RMI封装了EJB框架。虽然EJB相比RMI简单了很多,但是还是不方便学习,也不方便使用。当时的技术圈还是很淳朴的,大家在抨击的同时还能给出自己的建议及解决方案。其中最著名的就是Rod Johnson为了表达自己对EJB的不满,专门出了一本书《Expert One-On-One J2EE Development Without EJB》在抨击的同时还表达了自己的观点和建议,其中最著名的观点就是:如何让应用程序能以超出当时大众所惯于接受的易用性和稳定性与J2EE平台上的不同组件合作。
然后这本书引起了整个技术圈大佬的共鸣,所以一大批技术大佬自愿和Rod Johnson一起拓展他在2000年写出来的spring雏形代码,在他们一起奋斗了一年之后,于2004年发布了Spring的1.0版本,就此一颗璀璨的新星诞生在了Java的星河之中!
4.1、分布式用户诞生
下面回到咱们的分布式架构的演变上面来,怎么处理前面介绍的进程间数据传输问题呢?一共有三种方案:
- 当前server去之前存在用户数据的server上去获取。由于进程间通信过慢,舍弃;
- 某个server保存用户数据后,同步保存到别的server里面。由于这样会造成数据的冗余,同时进程间通信不可过于频繁的特性,难以处理用户频繁的数据更改需求,且性能较低,所以也舍弃了。
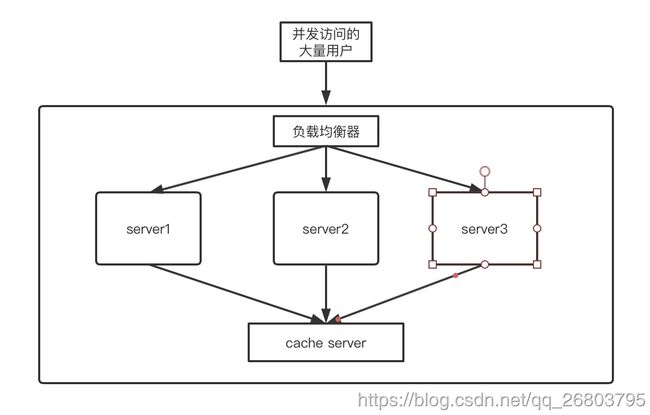
- 用户的请求被分配给某台server后,保存数据到外部的cache server里,同时cache server对所有server共享。 cache server就相当于缓存服务器,数据保存在内存里,面向所有server共享。当用户访问某台server时,它只需要去内存里获取数据就可以了。这时候大家应该会联想到redis,是的,redis处理订单之类的信息的时候,就充当了缓存服务器的作用。
这种把用户分布式处理的结构,我们称之为分布式用户,架构图大致如下:
4.2、分布式系统诞生
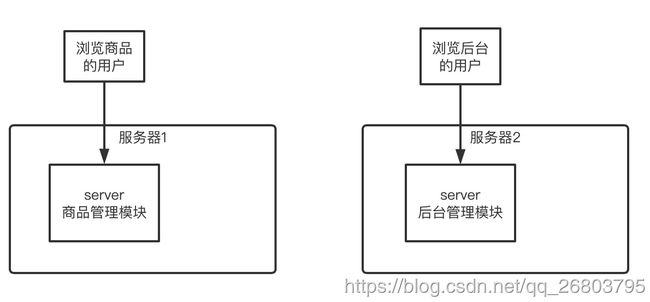
一个完整的系统肯定是有很多功能的,比如订单模块,商品模块,支付模块,后台管理模块。如果我们和前面一样把所有这些模块放在一个服务器资源里,由于不同模块的线程肯定是不一样的,比如5万个用户在看商品,2个管理员在看后台管理。
这时候2个人的线程肯定是抢不过5万个人的线程的,那这个问题该如何解决呢?
为了解决这个问题,同时考虑到单服务器性能存在瓶颈,扩展成本高昂。所以最好的办法就是水平扩展,多搞几台服务器还是比较容易实现的,且成本比较低。我们只能把服务器给拆开了,采用多台机器来提供服务,每个模块分配到不同的机器上,这样就不会存在线程争夺资源的情况了!
线程的问题解决了,还会有带宽的问题,比如我们的多台机器共享某个贷款,商品模块这个机器用户量非常大,带宽占用很高,这时候即使别的机器用户少,也会出现阻塞的现象,所以把服务器拆分后,我们还要把网络给拆分,采用不同的带宽来彻底解决用户分布不均匀的问题。
这种把一个系统拆分为多台服务器上运行的多个子系统的架构就是分布式系统。大致如下图所示:
同时我们把不同模块通用的功能给单独抽取出来,采用前面介绍的负载均衡器来均衡负载给各个模块集群就可以了,这种模式其实就是现在流行的微服务的概念。这时候采用负载均衡器有两种方案:服务端负载均衡和客户端负载均衡。
其中服务端负载均衡的架构图如下:

通过上面这个图我们可以发现,服务器端负载均衡一般采用负载均衡器集群,这是因为服务器端负载均衡的压力非常大,因此一般不进行服务器端负载均衡,而是采用客户端负载均衡。
为了实现客户端负载均衡,引入了注册中心的概念。以登陆为例,客户端向注册中心发送登陆请求,然后注册中心告诉客户端可以访问哪台机器上的服务,然后客户端采用轮询的方式去对应机器上访问即可。大致的结构图如下:

比如eureka,zookeeper等都可以作为注册中心如上图所示那样来使用。不过咱们联系一下redis,它是没有这类注册中心或者负载均衡器的,那么它就相当于采用去中心化的方式来处理的数据。
知识点四:什么是去中心化?
概括的来说,去中心化就相当于没有负载均衡器,没有这个中心,每个服务器节点都保留别的节点的信息,客户端访问任意一个节点,都可以知道别的节点的信息。
五、总结
当下正处于信息大爆炸的时代,分布式架构伴随着我们使用的每一款应用,每一个网站,逐渐成为了我们必知必会的架构模式。本文我们回溯了分布式的成因和发展,可以说分布式的发展壮大正是一批批程序员前赴后继,遇到问题并解决问题,不断迭代得到的技术成果,为所有程序员点赞!

如果您对我的文章感兴趣,欢迎关注点赞收藏,如果您有疑惑或发现文中有不对的地方,还请不吝赐教,非常感谢!!