Tensorflow2.0用FPN(图像金字塔网络)提取特征
一、FPN 的作用
当我们在使用卷积神经网络的提取图像特征的时候,最后一个 feature map 的长宽会比原始图片小很多,比如原始图片大小为 100x100,feature map 大小为 10x10,这就说明,其实我们是在用 feature map 中的一个特征点来表示原始图片中一个 10x10 的像素区域。然而,在目标检测中,我们可能要对原始图片中的一个 1x1 的像素点中包含的物体进行检测,这样的话我们就很有可能将这个小物体忽略掉。于是,为了解决多尺度检测的问题,引入了特征金字塔网络,它可以在这张原始图片的不同尺度上提取特征,从而得到原始图片的更多、更细节的信息。
二、 FPN 的原理
在进行多尺度检测时,有以下几种特征提取的方法:
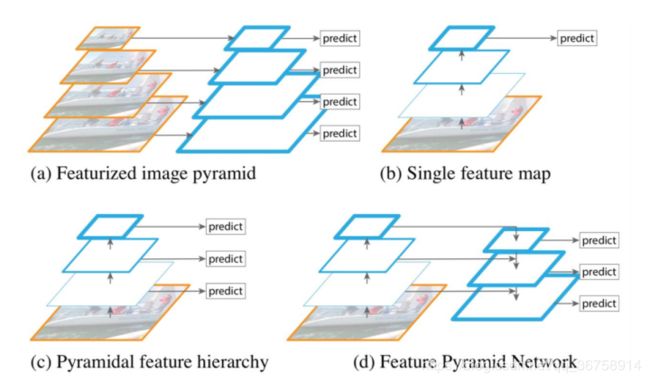
图(a)被称为 featurized image pyramid,它先将原始图片进行多尺度放缩,然后在不同尺度上提取特征,这样就解决了上面介绍的多尺度问题了。但是这样相当于训练了多个模型,计算量巨大。
图(b)就是 CNN,有多尺度问题。
图(c)重利用了前向过程计算出的来自多层的多尺度特征图,因此这种形式是不消耗额外的资源的。这种网络就是 SSD 方法所使用的,但是 SSD 为了避免使用低级的特征,放弃了浅层的 feature map,而是从 conv4_3 开始建立金字塔,而且加入了一些新的层。因此 SSD 放弃了重利用更高分辨率的 feature map,但是这些 feature map 对检测小目标非常重要。这就是 SSD 与 FPN 的区别。
图(4)就是 FPN 的结构了,FPN 是为了自然地利用 CNN 层级特征的金字塔形式,同时生成在所有尺度上都具有强语义信息的特征金字塔。所以 FPN 的结构设计了 top-down 结构和横向连接,以此融合具有高分辨率的浅层 feature map 和具有丰富语义信息的深层 feature map。这样就实现了从单尺度的单张输入图像,快速构建在所有尺度上都具有强语义信息的特征金字塔,同时不产生明显的代价。
1、down-top
自下而上的计算过程实际上就是 CNN 计算,feature map 经过卷积核计算越来越小。
2、top-down 和横向连接
自上而下的计算过程就是把更抽象,语义更强的高层特征图进行上取样,然后把该特征横向连接至前一层特征,因此高层特征可以得到加强。
下图显示连接细节。把高层特征做两次上采样(最邻近上采样法),然后将其和对应的前一层特征结合(前一层要经过 1x1 的卷积核才能用,目的是改变改变形状到和上采样后的形状相同),结合方式就是做像素间的加法。
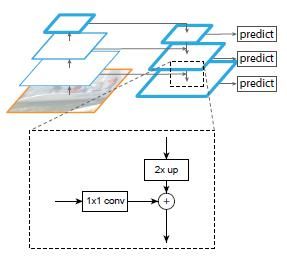 具体的网络结构为:
具体的网络结构为:

其中 down-top 过程的 feature map 用 C 表示;down-top 过程的 feature map 用 M 表示;最终得到的特征用 P 表示。
三、代码实现
1、BasicBlock 模块
这个模块和残差网络中的 Residual + ResnetBlock 模块很像,它主要用在 down-top 过程中。具体实现过程如下:
import tensorflow as tf
class BasicBlock(tf.keras.Model):
def __init__(self, in_channels, out_channels, strides=1):
super(BasicBlock, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(out_channels, kernel_size=3, strides=strides,
padding="same", use_bias=False)
self.bn1 = tf.keras.layers.BatchNormalization()
self.conv2 = tf.keras.layers.Conv2D(out_channels, kernel_size=3, strides=1,
padding="same", use_bias=False)
self.bn2 = tf.keras.layers.BatchNormalization()
if strides != 1 or in_channels != out_channels:
self.shortcut = tf.keras.Sequential([
tf.keras.layers.Conv2D(out_channels, kernel_size=1,
strides=strides, use_bias=False),
tf.keras.layers.BatchNormalization()]
)
else:
self.shortcut = lambda x,_: x
def call(self, x, training=False):
# if training: print("=> training network ... ")
out = tf.nn.relu(self.bn1(self.conv1(x), training=training))
out = self.bn2(self.conv2(out), training=training)
out += self.shortcut(x, training)
return tf.nn.relu(out)
在上述代码中,我们定义了一个 shortcut,其中的卷积核是 1x1 的,步长与 conv1 中的步长相等(保证将输入 x 的形状转变成经过 conv1 和 conv2 之后的形状)且卷积核个数与希望输出的通道数相等。举例来说:
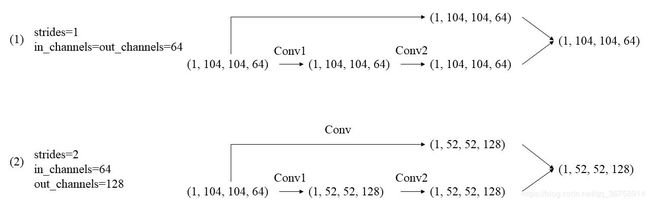
上图中,像情况(1)这种,就不需要 shortcut;像情况(2)这种,就需要 shortcut 对输入进行处理。
2、实现 FPN
class FPN(tf.keras.Model):
def __init__(self, block, num_blocks):
super(FPN, self).__init__()
self.in_channels = 64
self.conv1 = tf.keras.layers.Conv2D(64, 7, 2, padding="same", use_bias=False)
self.bn1 = tf.keras.layers.BatchNormalization()
# Bottom --> up layers
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
# Smooth layers
self.smooth1 = tf.keras.layers.Conv2D(256, 3, 1, padding="same")
self.smooth2 = tf.keras.layers.Conv2D(256, 3, 1, padding="same")
self.smooth3 = tf.keras.layers.Conv2D(256, 3, 1, padding="same")
self.smooth4 = tf.keras.layers.Conv2D(256, 3, 1, padding="same")
# Lateral layers
self.lateral_layer1 = tf.keras.layers.Conv2D(256, 1, 1, padding="valid")
self.lateral_layer2 = tf.keras.layers.Conv2D(256, 1, 1, padding="valid")
self.lateral_layer3 = tf.keras.layers.Conv2D(256, 1, 1, padding="valid")
self.lateral_layer4 = tf.keras.layers.Conv2D(256, 1, 1, padding="valid")
def _make_layer(self, block, out_channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels
return tf.keras.Sequential(layers)
def _upsample_add(self, x, y):
_, H, W, C = y.shape
return tf.image.resize(x, size=(H, W), method="bilinear")
def call(self, x, training=False):
C1 = tf.nn.relu(self.bn1(self.conv1(x), training=training))
C1 = tf.nn.max_pool2d(C1, ksize=3, strides=2, padding="SAME")
# Bottom --> up
C2 = self.layer1(C1, training=training)
C3 = self.layer2(C2, training=training)
C4 = self.layer3(C3, training=training)
C5 = self.layer4(C4, training=training)
# Top-down
M5 = self.lateral_layer1(C5)
M4 = self._upsample_add(M5, self.lateral_layer2(C4))
M3 = self._upsample_add(M4, self.lateral_layer3(C3))
M2 = self._upsample_add(M3, self.lateral_layer4(C2))
# Smooth
P5 = self.smooth1(M5)
P4 = self.smooth2(M4)
P3 = self.smooth3(M3)
P2 = self.smooth4(M2)
return P2, P3, P4, P5
举例来说:

四、 参考资料
1、Feature Pyramid Networks for Object Detection 总结
2、目标检测FPN