Multi-head attention with DR
注意力机制的核心部分是通过计算 K K K(键)序列与 q q q(查询)的相关性,来得到注意力权重a(通过一定的映射关系 f f f): a = f ( q . K ) a=f(q.K) a=f(q.K)。具体来说, A t t e n t i o n ( Q , K , V ) Attention(Q, K, V) Attention(Q,K,V)函数在输入矩阵 Q、K 和 V 的情况下可计算 Query 序列与 Value 序列之间的注意力关系。其中 Q 的维度为 n × d k n×d_k n×dk,表示有 n n n 条维度为 d k d_k dk 的 Query、 K K K 的维度为 m × d k m×d_k m×dk、 V V V 的维度为 m × d v m×d_v m×dv。这三个矩阵的乘积可得出 n × d v n×d_v n×dv 维的矩阵,它表示 有 n n n 条 Query 对应注意到的 Value 向量
在实际论文的表述里或者开展的实验中, K K K是词嵌入向量或模型的隐藏层状态向量 h t h_t ht; q q q是计算注意力分配多少的参考(reference)。本质上就是通过多次 Q K QK QK得到多个权重 a i j k . . . a_{ijk...} aijk...,(就有了分布函数),再利用权重的分布对 V V V加权。最基础的例子比如:
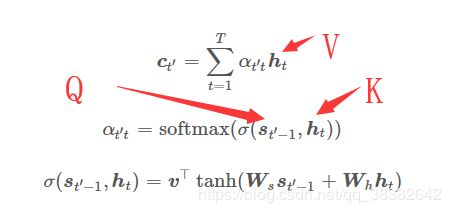
多头注意力,就是在上面 A t t e n t i o n ( Q , K , V ) Attention(Q,K,V) Attention(Q,K,V)里,获得了 h h h个不同版本的 Q , K , V Q,K,V Q,K,V, MultiHead ( Q , K , V ) = Concat ( head1 , . . . , head h ) W O \text{MultiHead}(Q,K,V) = \text{Concat}(\text{head1},...,\text{head}_h)\boldsymbol{W}^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(\boldsymbol{Q}\boldsymbol{W}_i^Q,\boldsymbol{K}\boldsymbol{W}_i^K,\boldsymbol{V}\boldsymbol{W}_i^V) headi=Attention(QWiQ,KWiK,VWiV) Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = \text{softmax}(\frac{\boldsymbol{Q}\boldsymbol{K}^T}{\sqrt{d_k}})\boldsymbol{V} Attention(Q,K,V)=softmax(dkQKT)V
我们记 Q W i Q = Q i , K W i K = K i , V W i V = V i , i ∈ [ 1 , h ] \boldsymbol{Q}\boldsymbol{W}_i^Q=Q^i,\boldsymbol{K}\boldsymbol{W}_i^K=K^i,\boldsymbol{V}\boldsymbol{W}_i^V=V^i,i \in [1,h] QWiQ=Qi,KWiK=Ki,VWiV=Vi,i∈[1,h],
W i Q , W i K , W i V \boldsymbol{W}_i^Q,\boldsymbol{W}_i^K,\boldsymbol{W}_i^V WiQ,WiK,WiV称为transformation matrics
如果我们把这些注意头可以看作是从不同角度对序列中同一实体的不同观察结果(权重),那么是否可以尝试从h个注意力头 u i u_i ui中找到一个最合适的 v v v。 u i = softmax ( Q i K i T d k ) V i u_i = \text{softmax}(\frac{\boldsymbol{Q_i}\boldsymbol{K_i}^T}{\sqrt{d_k}})\boldsymbol{V_i} ui=softmax(dkQiKiT)Vi
这不禁让人想入非非产生联想,在胶囊网络中,我们知道,对于v in v out的capsule,识别图片中的某一组件(component)的旋转不变性,是通过对该组件的feature与Pose向量做transformation。而我们知道,如果输入的是对同一实体在语言学上的不同描述,那么利用路由机制,就可以决定不同描述的information中谁能流向下一层胶囊层,进而是否可以利用这一性质,对上述h个头进行路由选择呢?
首先,通过将输入胶囊ui乘以表示部分和整体之间的视点不变关系的学习转换矩阵Wij来计算投票:
u i u_i ui是多头注意力机制的权值分布, W i j W_ij Wij是“部分”和“整体”的视点不变关系转换矩阵(为啥叫这个名字我也不知道…) u ^ j ∣ i = W i j u i \hat u_{j|i}=W_{ij}u_i u^j∣i=Wijui
然后计算并更新输出胶囊 v v v和vote u ^ \hat u u^,以及它们之间的分配概率 c c c, c c c路由迭代中的归一化操作中的量,将输出归一化到下一层的输入胶囊: v = f ( u ^ , c ) v=f(\hat u,c) v=f(u^,c), c = U p d a t e ( u ^ , v ) c=Update(\hat u,v) c=Update(u^,v)
最后,将输出胶囊v串联在一起,送入前馈网络(FFN),该网络由两个线性变换层组成,线性变换层中通过ReLU完成激活。 F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=max(0,xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2
另外,通过添加了层 u u u和 v v v之间的剩余连接后,最终的输出是: O + F F N ( v ) O+FFN(v) O+FFN(v)添加剩余连接就是用Concatenate操作实现:
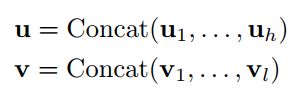
Dynamic Routing
我们把所有这些加权vote向量加起来,得到胶囊类型输出向量 s j = ∑ i c i j u ^ j ∣ i s_j=\sum_ic_{ij}\hat u_{j|i} sj=i∑ciju^j∣i其中 c i j = e x p ( b i j ) ∑ k e x p ( b i k ) c_{ij}=\frac{exp(b_{ij})}{\sum_kexp(b_{ik})} cij=∑kexp(bik)exp(bij),其中 b i j b_{ij} bij初值=0
然后就和动态路由一样,用 s j s_j sj启动squash: v j = ∣ ∣ s j ∣ ∣ 2 1 + ∣ ∣ s j ∣ ∣ 2 s j ∣ ∣ s j ∣ ∣ v_j=\frac{||s_j||^2}{1+||s_j||^2}\frac{s_j}{||s_j||} vj=1+∣∣sj∣∣2∣∣sj∣∣2∣∣sj∣∣sj
初始的coefficients b i j b_{ij} bij是胶囊输入值 u ^ j ∣ i \hat u_{j|i} u^j∣i和每个胶囊输出值 v j v_j vj两者的点积(点积衡量相似性,也即coefficients代表输入和输出的相似度,聚类的思想)