RabbitMQ之消息追踪
一、前言
在使用任何消息中间件的过程中,难免会出现某条消息异常丢失的情况。对于RabbitMQ而言,可能是因为生产者或消费者与RabbitMQ断开了连接,而它们与RabbitMQ又采用了不同的确认机制;也有可能是因为交换器与队列之间不同的转发策略;甚至是交换器并没有与任何队列进行绑定,生产者又不感知或者没有采取相应的措施;另外RabbitMQ本身的集群策略也可能导致消息的丢失。这个时候就需要有一个较好的机制跟踪记录消息的投递过程,以此协助开发和运维人员进行问题的定位。
二、Firehose
在RabbitMQ中可以使用Firehose功能来实现消息追踪,Firehose可以记录每一次发送或者消费消息的记录,方便使用RabbitMQ的使用者进行调试、排错等。
Firehose的机制是将生产者投递给RabbitMQ的消息,或者是RabbitMQ投递给消费者的消息按照指定的格式发送到默认的交换器上。这个默认的交换器的名称为amq.rabbitmq.trace,它是一个topic类型的交换器。发送到这个交换器上的消息的routingKey为publish.exchangename和deliver.queuename。其中exchangename和queuename为实际的交换器和队列的名称,分别对应生产者投递到交换器的消息和消费者从队列中获取的消息。
开启Firehose命令:
rabbitmqctl trace_on [-p vhost] 其中[-p vhost]是可选参数,用来指定vhost。
对应的关闭命令为:
rabbitmqctl trace_off [-p vhost]注意Firehose默认情况处于关闭状态,并且Firehose的状态也是非持久化的,会在RabbitMQ服务重启的时候还原成默认的状态。Firehose开启之后多少会影响服务的性能,因为它会引起额外的消息生成、路由和存储。
下面我们举例说明下Firehose的用法。需要做一下准备工作,确保Firehose处于开启状态,创建7个队列:queue、queue.another、queue1、queue2、queue3、queue4和queue5。之后再创建2个交换器exchange和exchange.another,分别通过绑定键rk和rk.another与queue和queue.another进行绑定。最后将amq.rabbitmq.trace这个关键的交换器与queue1、queue2、queue3、queue4和queue5绑定,详细可以参考下图。

分别用客户端向exchange和exchange.another中发送一条消息“trace test payload.”,然后再用客户端消费队列queue和queue.another中的消息。
此时queue1中有2条消息,queue2中有2条消息,queue3中有4条消息,而queue4和queue5中只有一条消息。在向exchange发送一条消息后,amq.rabbitmq.trace分别向queue1、queue3和queue4发送一条内部封装的消息。同样,在想exchange.another中发送一条消息之后,对应的队列queue1和queue3中会多一条消息。消费队列queue的时候,queue2、queue3和queue5中会多一条消息,消费队列queue.another的时候,queue2和queue3会多一条消息。“publish.#”匹配发送到所有交换器的消息,“deliver.#”匹配消费所有队列的消息,而“#”则包含了“publish.#”和“deliver.#”。
在Firehose开启状态下,当有客户端发送或者消费消息时,Firehose会自动封装相应的消息体,并添加详细的headers属性。对于前面的将“trace test payload.”这条消息发送到交换器exchange来说,Firehore会将其封装成如下的内容:
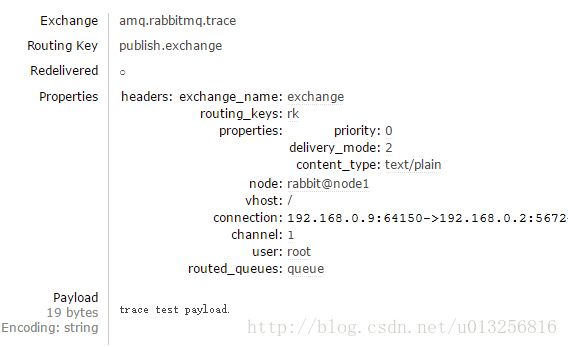
在消费queue时,会将这条消息封装成如下的内容:

headers中的exchange_name表示发送此条消息的交换器;routing_keys表示与exchange_name对应的路由键列表;properties表示消息本身的属性,比如delivery_mode=2表示消息需要持久化处理。
三、rabbitmq_tracing 插件
rabbitmq_tracing插件相当于Firehose的GUI版本,它同样能跟踪RabbitMQ中消息的流入流出情况。rabbitmq_tracing插件同样会对流入流出的消息做封装,然后将封装后的消息日志存入相应的trace文件之中。
可以使用rabbitmq-plugins enable rabbitmq_tracing命令来启动rabbitmq_tracing插件。
[root@node3 opt]# rabbitmq-plugins enable rabbitmq_tracing
The following plugins have been enabled:
rabbitmq_tracing
Applying plugin configuration to rabbit@node3... started 1 plugin.
对应的关闭插件的命令是:rabbitmq-plugins disable rabbitmq_tracing。
在Web管理界面 “Admin”右侧原本只有"Users"、"Virtual Hosts"以及”Policies“这个三Tab项,在添加rabbitmq_tracing插件之后,会多出”Tracing"这一项内容:
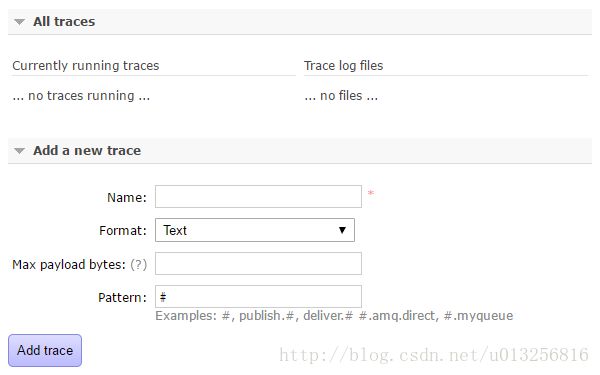
可以在此Tab项中添加相应的trace:
在添加完trace之后,会根据匹配的规则将相应的消息日志输出到对应的trace文件之中,文件的默认路径为/var/tmp/rabbitmq-tracing。可以在页面中直接点击“Trace log files”下面的列表直接查看对应的日志文件。
如下图,我们添加了两个trace任务。
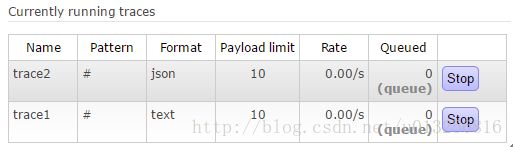
与其相对应的trace文件如下:
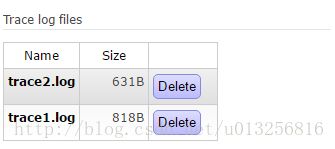
再添加完相应的trace任务之后,会发现多了两个队列: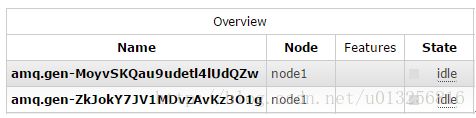
就以第一个队列amq.gen-MoyvSKQau9udetl4lUdQZw而言,其所绑定的交换器就是amq.rabbitmq.log。
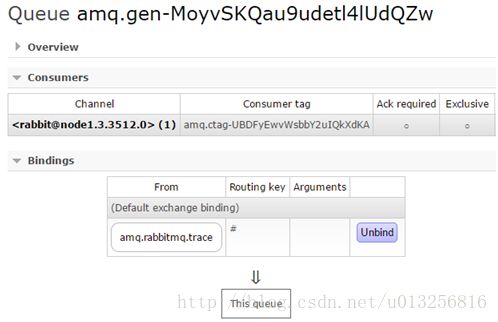
由此可以看出整个rabbitmq_tracing和Firehose在实现上如出一辙,只不过rabbitmq_tracing的方式比Firehose多了一层GUI的包装,更容易使用和管理。
再来补充说明上图中“Name”,“Format”,“Max payload bytes”,"Pattern"的具体含义。“Name”,顾名思义,就是为你所要即将创建的trace任务取个名称。
“Format”表示输出的消息日志格式,有Text和JSON两种,Text格式的日志方便人类阅读,JSON的方便程序解析。
Text格式的消息日志参考如下:
================================================================================
2017-10-24 9:37:04:412: Message published
Node: rabbit@node1
Connection:
Virtual host: /
User: root
Channel: 1
Exchange: exchange
Routing keys: [<<"rk">>]
Routed queues: [<<"queue">>]
Properties: [{<<"delivery_mode">>,signedint,1},{<<"headers">>,table,[]}]
Payload:
trace test payload.
JSON格式的消息日志参考如下:
{
"timestamp": "2017-10-24 9:37:04:412",
"type": "published",
"node": "rabbit@node1",
"connection": "",
"vhost": "/",
"user": "root",
"channel": 1,
"exchange": "exchange",
"queue": "none",
"routed_queues": [
"queue"
],
"routing_keys": [
"rk"
],
"properties": {
"delivery_mode": 1,
"headers": {}
},
"payload": "dHJhY2UgdGVzdCBwYXlsb2FkLg=="
}
JSON格式的payload(消息体)默认会采用Base64进行编码,如上面的“trace test payload.”会被编码成“dHJhY2UgdGVzdCBwYXlsb2FkLg==”。
“Max payload bytes”表示每条消息的最大限制,单位为B。比如设置了了此值为10,那么当有超过10B的消息经过RabbitMQ流转时,在记录到trace文件的时候会被截断。如上text日志格式中“trace test payload.”会被截断成“trace test”。
"Pattern"用来设置匹配的模式,和Firehose的类似。如“#”匹配所有消息流入流出的情况,即当有客户端生产消息或者消费消息的时候,会把相应的消息日志都记录下来;“publish.#”匹配所有消息流入的情况;“deliver.#”匹配所有消息流出的情况。
记录于:朱忠华的《RabbitMQ实战指南》
推荐学习RabbitMQ连接:https://juejin.im/tag/RabbitMQ