Flume架构及源码体验
首先回答一个问题的,What it is Flume?
这是一个分布式,高可用,可靠的分布式日志收集系统 ,能将不同的海量数据收集,移动并存储到一个数据存储系统中。
先说一句,这里说的是 NG!NG!NG!,然后就是本文可能会说的比较多、比较细,并且不谈安装配置(安装不提,配置根据不同情况不一而同,如果只想做个 demo 的话网上一大堆)。
在我看来,Flume-ng 已经说不上是一个所谓的系统了,没有了 master、没有了 control,去掉了很多臃肿的组件,现在应该将它称为一个优秀的传输工具。现在来把Flume拆开了谈一谈,先上图
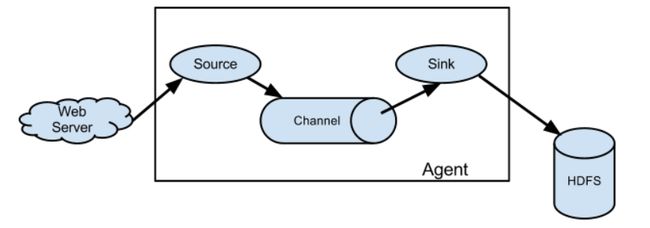
Agent–Flume的核心
agent 是 Flume 的一个独立进程,一个完整的数据收集工具,独立运行在一个 JVM 上,其中包含了 Flume 的核心组件(source、channel 和 sink)。
Client
client 其实是一个位于数据源的生产数据的组件,线程独立,供 agent 的 source 进行数据读取。
Event
event 是 flume 数据传输的单位,也是事务的基本单元。分为头部与数据部分,其中头部是一个 map,数据为字节数组。

Flow
Flume event 传输过程的抽象。
然后接下来具体点:
一、数据源
Client所支持的日志机制
Avro、Thrift、Syslog、Netcat、log4j 和 http(Post 传输(json 封装))等等。
Event
Flume 将一行文本反序列化为一个 event,可以定义 event 的大小、编码等。
Hearder
//event定义了一个描述数据的hearder
Map getHeaders();
//你也可以set它(分装复用时起作用)
void setHeaders(Map headers); Body
//event定义了一个存放数据数据的body
byte[] getBody();
//你也可以set它
void setBody(byte[] body); event 包装了数据内容到 body 中,并转换编码,且将hearder设置为空(如果不需要 fan out 到不同的 channel,header 无存在必要,如需要,则自定义),然后传入 channel 中。
public static Event withBody(byte[] body,Map headers) {
Event event = new SimpleEvent();
if(body == null) {
body = new byte[0];
}
event.setBody(body);
if (headers != null) {
event.setHeaders(new HashMap(headers));
}
return event;
} 二、agent
Source
source 用于收集传递到该 agent 的 event,其 type 有很多种,针对不同的日志数据传输机制,常用的有:
Avro Source
匹配 Avro ,针对 Avro 机制收集数据(rpc)。
Exec Source
基于 Unix/Linux 命令产生的数据。
JMS Source
连接到JMS(Topic 或 Queue)收集数据
Spooling Directory Source
监控文件夹的新文件生成,读取文件内容到channel(读取完重命名或删除该文件)。
Kafka Source
读取Kafka数据源。
来来来,看看Source接口定义:
public interface Source extends LifecycleAware, NamedComponent {
/**
* 设置channel对event的处理标识
*/
public void setChannelProcessor(ChannelProcessor channelProcessor);
/**
* 返回标识
*/
public ChannelProcessor getChannelProcessor();
}其实这里没啥东西,主要是些基础参数,利用 NamedComponent 定义每个组件的唯一标识,LifecycleAware 维护组件状态,定义 Channel 的操作。
然后看 Source 的抽象,主要是组件状态改变和取得标识,这里 Source 还有一个很重要的点是获取 Channel 事务对象的 ,这个在后面的 Channel 中说,各位大佬可以注意一下。
public abstract class AbstractSource implements Source {
private ChannelProcessor channelProcessor;
private String name;
private LifecycleState lifecycleState;
public AbstractSource() {
lifecycleState = LifecycleState.IDLE;
}
@Override
public synchronized void start() {
Preconditions.checkState(channelProcessor != null,
"No channel processor configured");
lifecycleState = LifecycleState.START;
}
@Override
public synchronized void stop() {
lifecycleState = LifecycleState.STOP;
}
@Override
public synchronized void setChannelProcessor(ChannelProcessor cp) {
channelProcessor = cp;
}
@Override
public synchronized ChannelProcessor getChannelProcessor() {
return channelProcessor;
}
@Override
public synchronized LifecycleState getLifecycleState() {
return lifecycleState;
}
@Override
public synchronized void setName(String name) {
this.name = name;
}
@Override
public synchronized String getName() {
return name;
}
public String toString() {
return this.getClass().getName() + "{name:" + name + ",state:" + lifecycleState + "}";
}
}说下使用情况,多数用的是 Spooling Directory Source,刚开始分析,多说点。首先,Spooling Directory Source 与其他 异步 Source 不一样的是它是可靠的。然后看看它是如何执行的,还是用源码说话吧:
public class SpoolDirectorySource extends AbstractSource
implements Configurable, EventDrivenSource {
private static final Logger logger = LoggerFactory.getLogger(SpoolDirectorySource.class);
/* 配置选项 */
//读取文件完成标记(default ".COMPLETED")
private String completedSuffix;
//配置的Flume监控目录(不监控子目录)
private String spoolDirectory;
//Header是否保存文件绝对路径
private boolean fileHeader;
//fileHeader在Header中的key(自身为value)
private String fileHeaderKey;
//Header是否保存文件名
private boolean basenameHeader;
//basenameHeader在Header中的key(自身为value)
private String basenameHeaderKey;
//每次处理行数(default "100")
private int batchSize;
private String includePattern;
//正则表达式(文件名匹配则略过不读)
private String ignorePattern;
//文件元数据存放目录
private String trackerDirPath;
//序列化
private String deserializerType;
private Context deserializerContext;
//文件读取完是否删除(default "never")
private String deletePolicy;
//读入编码方式(default "UTF-8")
private String inputCharset;
//有无法解析字符时的处理策略(default "FAIL 返回coderresult对象或者抛出charactercodingexception异常")
private DecodeErrorPolicy decodeErrorPolicy;
private volatile boolean hasFatalError = false;
private SourceCounter sourceCounter;
ReliableSpoolingFileEventReader reader;
private ScheduledExecutorService executor;
private boolean backoff = true;
private boolean hitChannelException = false;
private boolean hitChannelFullException = false;
//向 channel 中发送 event,出现 channel 溢满,则休眠,休眠时间成倍增加至该值后不变
private int maxBackoff;
//文件读取顺序(default "OLDEST")
private ConsumeOrder consumeOrder;
private int pollDelay;
private boolean recursiveDirectorySearch;
@Override
public synchronized void start() {
logger.info("SpoolDirectorySource source starting with directory: {}",
spoolDirectory);
executor = Executors.newSingleThreadScheduledExecutor();
File directory = new File(spoolDirectory);
try {
reader = new ReliableSpoolingFileEventReader.Builder()
.spoolDirectory(directory)
.completedSuffix(completedSuffix)
.includePattern(includePattern)
.ignorePattern(ignorePattern)
.trackerDirPath(trackerDirPath)
.annotateFileName(fileHeader)
.fileNameHeader(fileHeaderKey)
.annotateBaseName(basenameHeader)
.baseNameHeader(basenameHeaderKey)
.deserializerType(deserializerType)
.deserializerContext(deserializerContext)
.deletePolicy(deletePolicy)
.inputCharset(inputCharset)
.decodeErrorPolicy(decodeErrorPolicy)
.consumeOrder(consumeOrder)
.recursiveDirectorySearch(recursiveDirectorySearch)
.build();
} catch (IOException ioe) {
throw new FlumeException("Error instantiating spooling event parser",
ioe);
}
Runnable runner = new SpoolDirectoryRunnable(reader, sourceCounter);
executor.scheduleWithFixedDelay(
runner, 0, pollDelay, TimeUnit.MILLISECONDS);
super.start();
logger.debug("SpoolDirectorySource source started");
//source监控
sourceCounter.start();
}
@Override
public synchronized void stop() {
executor.shutdown();
try {
executor.awaitTermination(10L, TimeUnit.SECONDS);
} catch (InterruptedException ex) {
logger.info("Interrupted while awaiting termination", ex);
}
executor.shutdownNow();
super.stop();
sourceCounter.stop();
logger.info("SpoolDir source {} stopped. Metrics: {}", getName(), sourceCounter);
}
@Override
public String toString() {
return "Spool Directory source " + getName() +
": { spoolDir: " + spoolDirectory + " }";
}
/* 调用 configure 方法配置参数,不配置则按默认来 */
public synchronized void configure(Context context) {
spoolDirectory = context.getString(SPOOL_DIRECTORY);
Preconditions.checkState(spoolDirectory != null,
"Configuration must specify a spooling directory");
completedSuffix = context.getString(SPOOLED_FILE_SUFFIX,
DEFAULT_SPOOLED_FILE_SUFFIX);
deletePolicy = context.getString(DELETE_POLICY, DEFAULT_DELETE_POLICY);
fileHeader = context.getBoolean(FILENAME_HEADER,
DEFAULT_FILE_HEADER);
fileHeaderKey = context.getString(FILENAME_HEADER_KEY,
DEFAULT_FILENAME_HEADER_KEY);
basenameHeader = context.getBoolean(BASENAME_HEADER,
DEFAULT_BASENAME_HEADER);
basenameHeaderKey = context.getString(BASENAME_HEADER_KEY,
DEFAULT_BASENAME_HEADER_KEY);
batchSize = context.getInteger(BATCH_SIZE,
DEFAULT_BATCH_SIZE);
inputCharset = context.getString(INPUT_CHARSET, DEFAULT_INPUT_CHARSET);
decodeErrorPolicy = DecodeErrorPolicy.valueOf(
context.getString(DECODE_ERROR_POLICY, DEFAULT_DECODE_ERROR_POLICY)
.toUpperCase(Locale.ENGLISH));
includePattern = context.getString(INCLUDE_PAT, DEFAULT_INCLUDE_PAT);
ignorePattern = context.getString(IGNORE_PAT, DEFAULT_IGNORE_PAT);
trackerDirPath = context.getString(TRACKER_DIR, DEFAULT_TRACKER_DIR);
deserializerType = context.getString(DESERIALIZER, DEFAULT_DESERIALIZER);
deserializerContext = new Context(context.getSubProperties(DESERIALIZER +
"."));
consumeOrder = ConsumeOrder.valueOf(context.getString(CONSUME_ORDER,
DEFAULT_CONSUME_ORDER.toString()).toUpperCase(Locale.ENGLISH));
pollDelay = context.getInteger(POLL_DELAY, DEFAULT_POLL_DELAY);
recursiveDirectorySearch = context.getBoolean(RECURSIVE_DIRECTORY_SEARCH,
DEFAULT_RECURSIVE_DIRECTORY_SEARCH);
Integer bufferMaxLineLength = context.getInteger(BUFFER_MAX_LINE_LENGTH);
if (bufferMaxLineLength != null && deserializerType != null &&
deserializerType.equalsIgnoreCase(DEFAULT_DESERIALIZER)) {
deserializerContext.put(LineDeserializer.MAXLINE_KEY,
bufferMaxLineLength.toString());
}
maxBackoff = context.getInteger(MAX_BACKOFF, DEFAULT_MAX_BACKOFF);
if (sourceCounter == null) {
sourceCounter = new SourceCounter(getName());
}
}
@VisibleForTesting
protected boolean hasFatalError() {
return hasFatalError;
}
@VisibleForTesting
protected void setBackOff(boolean backoff) {
this.backoff = backoff;
}
@VisibleForTesting
protected boolean didHitChannelException() {
return hitChannelException;
}
@VisibleForTesting
protected boolean didHitChannelFullException() {
return hitChannelFullException;
}
@VisibleForTesting
protected SourceCounter getSourceCounter() {
return sourceCounter;
}
@VisibleForTesting
protected boolean getRecursiveDirectorySearch() {
return recursiveDirectorySearch;
}
/*
* event 迁移过程,重点:run()方法
*/
private class SpoolDirectoryRunnable implements Runnable {
private ReliableSpoolingFileEventReader reader;
private SourceCounter sourceCounter;
public SpoolDirectoryRunnable(ReliableSpoolingFileEventReader reader,
SourceCounter sourceCounter) {
this.reader = reader;
this.sourceCounter = sourceCounter;
}
@Override
public void run() {
int backoffInterval = 250;
try {
while (!Thread.interrupted()) {
List events = reader.readEvents(batchSize);
if (events.isEmpty()) {
break;
}
//监控统计
sourceCounter.addToEventReceivedCount(events.size());
sourceCounter.incrementAppendBatchReceivedCount();
try {
//发送Event数组到Channel
getChannelProcessor().processEventBatch(events);
//提交后会记录最后一次读取的行数,提供下次读取标识
reader.commit();
} catch (ChannelFullException ex) {
/*
*抛出ChannelException异常,reader.commit未执行,所以continue后,继续reader读取
*文件,从原来的位置读取,以保证数据不会丢失
*/
logger.warn("The channel is full, and cannot write data now. The " +
"source will try again after " + backoffInterval +
" milliseconds");
hitChannelFullException = true;
backoffInterval = waitAndGetNewBackoffInterval(backoffInterval);
continue;
} catch (ChannelException ex) {
logger.warn("The channel threw an exception, and cannot write data now. The " +
"source will try again after " + backoffInterval +
" milliseconds");
hitChannelException = true;
backoffInterval = waitAndGetNewBackoffInterval(backoffInterval);
continue;
}
backoffInterval = 250;
sourceCounter.addToEventAcceptedCount(events.size());
sourceCounter.incrementAppendBatchAcceptedCount();
}
} catch (Throwable t) {
logger.error("FATAL: " + SpoolDirectorySource.this.toString() + ": " +
"Uncaught exception in SpoolDirectorySource thread. " +
"Restart or reconfigure Flume to continue processing.", t);
hasFatalError = true;
Throwables.propagate(t);
}
}
private int waitAndGetNewBackoffInterval(int backoffInterval) throws InterruptedException {
//backoff默认true
if (backoff) {
//休眠间隔
TimeUnit.MILLISECONDS.sleep(backoffInterval);
//休眠间隔左移一位(即*2)
backoffInterval = backoffInterval << 1;
//达到最大值即间隔保持不变
backoffInterval = backoffInterval >= maxBackoff ? maxBackoff :
backoffInterval;
}
return backoffInterval;
}
}
} 请好好看源码,看注释,很好懂,这要是还没法理清一个流程,劝退。然后看对文件的操作,
ReliableSpoolingFileEventReader 用于读取文件,删除或更名已读文件,这里只贴文件处理部分(代码太长),开搞
public List readEvents(int numEvents) throws IOException {
//文件初始化
if (!committed) {
//新文件判定
if (!currentFile.isPresent()) {
throw new IllegalStateException("File should not roll when " +
"commit is outstanding.");
}
logger.info("Last read was never committed - resetting mark position.");
/*
* 正常在 SpoolDirectorySource 中记录读取的字节数,将commited设置为true,否则发送到Channel异常,
* 调用reset方法保证数据不丢失。
*/
currentFile.get().getDeserializer().reset();
} else {
if (!currentFile.isPresent()) {
//读取文件过程中使用FileFilter过滤掉.COMPLETED后缀的文件,根据文件读取顺序配置(consumeOrder)读取
currentFile = getNextFile();
}
if (!currentFile.isPresent()) {
return Collections.emptyList();
}
}
//读取数据并封装
List events = readDeserializerEvents(numEvents);
//空即读完
while (events.isEmpty()) {
logger.info("Last read took us just up to a file boundary. " +
"Rolling to the next file, if there is one.");
//根据配置删除或重命名已读文件
retireCurrentFile();
currentFile = getNextFile();
if (!currentFile.isPresent()) {
return Collections.emptyList();
}
events = readDeserializerEvents(numEvents);
}
//header数据
fillHeader(events);
committed = false;
lastFileRead = currentFile;
return events;
}
//读取完返回event集合
private List readDeserializerEvents(int numEvents) throws IOException {
EventDeserializer des = currentFile.get().getDeserializer();
List events = des.readEvents(numEvents);
if (events.isEmpty() && firstTimeRead) {
events.add(EventBuilder.withBody(new byte[0]));
}
firstTimeRead = false;
return events;
}
private void fillHeader(List events) {
//是否添加绝对文件路径到Header
if (annotateFileName) {
String filename = currentFile.get().getFile().getAbsolutePath();
for (Event event : events) {
event.getHeaders().put(fileNameHeader, filename);
}
}
//是否添加文件名到Header
if (annotateBaseName) {
String basename = currentFile.get().getFile().getName();
for (Event event : events) {
event.getHeaders().put(baseNameHeader, basename);
}
}
} OK,到这里,后面说个重点的东西,source 的具体实现是有两种方式的,实现 EventDrivenSource 或是 PollableSource ,而且 EventDrivenSourceRunner 和 PollableSourceRunner 分别对应两者。这里不放源码了,有兴趣可以自己去看看, 说下主要区别。
EventDrivenSource
其不是由其自身的线程驱动(可以 start 额外线程),自身实现了事件驱动机制确定 source 中的消息,可以自己接受数据、发送到channel。
PollableSource
其必须要实现 process 方法,必须有它自己的 callback 机制,通过该机制将 event 放入 channel 中,而且需要外部驱动来确定 source 中是否有消息可以使用。
多数 Source 以及你需要自定义 Source 的时候都是用的 EventDrivenSource。
Channel
Channel用于连接Source和Sink,可以临时储存日志信息。
Channel内置类型,常用的有Memory Channel、File Channel、Kafka Channel等等。因为实际使用中大多会对Channel进行定制改造,再加上我自身对这块不怎么熟,所以说的随意点,免得误导各位看官。
Memory Channel 是不可靠的,传入它的 event 将被保存到内存中,直到 event 被成功写入下一节。如果 JVM 或者系统崩溃,数据就会丢失。但是其传输速度快,吞吐量高。
File Channel 是稳定的通道,他会将信息先写入硬盘直到 event 被写入下一节,数据可恢复。但是其传输速度慢,对 IO 端口压力大。
Kafka Channel 以Kafka作为Channel(包含producer和consumer),可均衡以上两者的优缺点。
接下来了解 Channel 的执行流程,还是搬源码说话吧:
public interface Channel extends LifecycleAware, NamedComponent {
/**
* 向Channel中传入event时调用
*/
public void put(Event event) throws ChannelException;
/**
* Channel传出event时调用
* 失败返回下一个event或null值
*/
public Event take() throws ChannelException;
/**
* 事务
*/
public Transaction getTransaction();
}这个接口很简洁,但定义了 event 传递,有 ChannelException 抛出,还有一个 Transaction 定义,那么这个事务的定义是如何的呢?可以看到,其实这就是一个标准的事务定义,基本的调用方法,基本的枚举状态。
public interface Transaction {
enum TransactionState { Started, Committed, RolledBack, Closed }
void begin();
void commit();
void rollback();
void close();
}接下来先看几张图:
Channel基本实现关系:
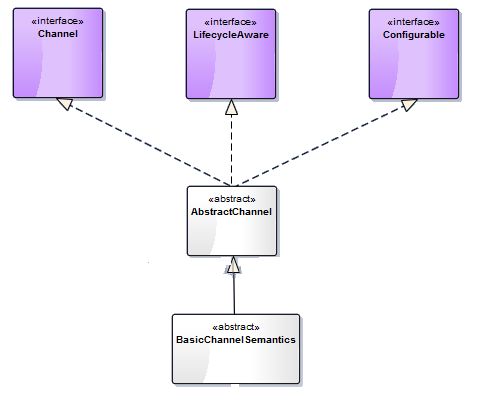
事务基本实现关系:
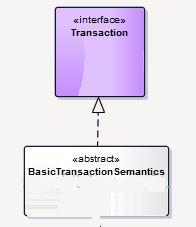
图很简单,然后就着图看源码(咦,好像有什么不对):
public abstract class BasicChannelSemantics extends AbstractChannel {
//使用ThreadLocal来保证线程安全
private ThreadLocal currentTransaction
= new ThreadLocal();
private boolean initialized = false;
/**
* 初始化
*/
protected void initialize() {}
/**
* 实现类的事务回调
*/
protected abstract BasicTransactionSemantics createTransaction();
/**
* 不想解释
*/
@Override
public void put(Event event) throws ChannelException {
BasicTransactionSemantics transaction = currentTransaction.get();
Preconditions.checkState(transaction != null,
"No transaction exists for this thread");
transaction.put(event);
}
/**
* 同上
*/
@Override
public Event take() throws ChannelException {
BasicTransactionSemantics transaction = currentTransaction.get();
Preconditions.checkState(transaction != null,
"No transaction exists for this thread");
return transaction.take();
}
/**
* 获取事务
*/
@Override
public Transaction getTransaction() {
/**
* 初始化判定
*/
if (!initialized) {
synchronized (this) {
if (!initialized) {
//没初始化的初始化一下
initialize();
initialized = true;
}
}
}
/**
* 这里说一下,无事务存在就创建一个然后绑定到ThreadLocal
*/
BasicTransactionSemantics transaction = currentTransaction.get();
if (transaction == null || transaction.getState().equals(
BasicTransactionSemantics.State.CLOSED)) {
transaction = createTransaction();
currentTransaction.set(transaction);
}
return transaction;
}
} 还是说下 put、take 方法吧(才不是傲娇)。其实这里是 Source 和 Sink 对 Event 操作必须调用的,也就是两者事务的保障。
至于事务的详细实现,这里就不详细说了,感兴趣可以去看看BasicTransactionSemantics 的实现
最后说下Channel选择器,这很重要!这很重要!这很重要!!!
有两种,ReplicatingChannelSelector(default)和MultiplexingChannelSelector,前者复制后者复用。
看源码
ReplicatingChannelSelector
public class ReplicatingChannelSelector extends AbstractChannelSelector {
public static final String CONFIG_OPTIONAL = "optional";
List requiredChannels = null;
List optionalChannels = new ArrayList();
/*
* 返回配置Source中对应Channels
*/
@Override
public List getRequiredChannels(Event event) {
if (requiredChannels == null) {
return getAllChannels();
}
return requiredChannels;
}
/*
* 返回配置Optional中指定Channels
*/
@Override
public List getOptionalChannels(Event event) {
return optionalChannels;
}
/*
* 加载配置文件,调用底层实现
*/
@Override
public void configure(Context context) {
String optionalList = context.getString(CONFIG_OPTIONAL);
requiredChannels = new ArrayList(getAllChannels());
Map channelNameMap = getChannelNameMap();
if (optionalList != null && !optionalList.isEmpty()) {
for (String optional : optionalList.split("\\s+")) {
Channel optionalChannel = channelNameMap.get(optional);
requiredChannels.remove(optionalChannel);
if (!optionalChannels.contains(optionalChannel)) {
optionalChannels.add(optionalChannel);
}
}
}
}
} 这里很简单,基本就是加载配置信息,取得对应的 ChannelName。要提的一点就是 requiredChannels 会删除加入 optionalChannels 的Channel,而 requiredChannels 为空会返回所以 Channels,所以 requiredChannels 和 optionalChannels 交集可能致使数据重复,建议 Source 中和 Optional 配置不同的 Channels。
MultiplexingChannelSelector
public class MultiplexingChannelSelector extends AbstractChannelSelector {
public static final String CONFIG_MULTIPLEX_HEADER_NAME = "header";
public static final String DEFAULT_MULTIPLEX_HEADER =
"flume.selector.header";
public static final String CONFIG_PREFIX_MAPPING = "mapping.";
public static final String CONFIG_DEFAULT_CHANNEL = "default";
public static final String CONFIG_PREFIX_OPTIONAL = "optional";
@SuppressWarnings("unused")
private static final Logger LOG = LoggerFactory.getLogger(MultiplexingChannelSelector.class);
private static final List EMPTY_LIST =
Collections.emptyList();
private String headerName;
//存储header值与对应Channels
private Map> channelMapping;
//存储配置值与Channels的映射关系
private Map> optionalChannels;
//存储默认Channels,event无匹配值时返回
private List defaultChannels;
//返回channelMapping中该event的header对应的channels
@Override
public List getRequiredChannels(Event event) {
String headerValue = event.getHeaders().get(headerName);
if (headerValue == null || headerValue.trim().length() == 0) {
//为空返回defaultChannel
return defaultChannels;
}
List channels = channelMapping.get(headerValue);
//This header value does not point to anything
//Return default channel(s) here.
if (channels == null) {
channels = defaultChannels;
}
return channels;
}
//返回optionalChannels中event的header对应的可选channels
public List getOptionalChannels(Event event) {
String hdr = event.getHeaders().get(headerName);
List channels = optionalChannels.get(hdr);
if (channels == null) {
channels = EMPTY_LIST;
}
return channels;
}
/*
*划重点!
*/
public void configure(Context context) {
this.headerName = context.getString(CONFIG_MULTIPLEX_HEADER_NAME,
DEFAULT_MULTIPLEX_HEADER);
Map channelNameMap = getChannelNameMap();
defaultChannels = getChannelListFromNames(
context.getString(CONFIG_DEFAULT_CHANNEL), channelNameMap);
Map mapConfig =
context.getSubProperties(CONFIG_PREFIX_MAPPING);
channelMapping = new HashMap>();
for (String headerValue : mapConfig.keySet()) {
List configuredChannels = getChannelListFromNames(
mapConfig.get(headerValue),
channelNameMap);
if (configuredChannels.size() == 0) {
throw new FlumeException("No channel configured for when "
+ "header value is: " + headerValue);
}
if (channelMapping.put(headerValue, configuredChannels) != null) {
throw new FlumeException("Selector channel configured twice");
}
}
Map optionalChannelsMapping =
context.getSubProperties(CONFIG_PREFIX_OPTIONAL + ".");
optionalChannels = new HashMap>();
for (String hdr : optionalChannelsMapping.keySet()) {
List confChannels = getChannelListFromNames(
optionalChannelsMapping.get(hdr), channelNameMap);
if (confChannels.isEmpty()) {
confChannels = EMPTY_LIST;
}
List reqdChannels = channelMapping.get(hdr);
if (reqdChannels == null || reqdChannels.isEmpty()) {
reqdChannels = defaultChannels;
}
for (Channel c : reqdChannels) {
if (confChannels.contains(c)) {
confChannels.remove(c);
}
}
if (optionalChannels.put(hdr, confChannels) != null) {
throw new FlumeException("Selector channel configured twice");
}
}
}
} 这里就比较复杂了,感觉不好讲清楚,就说个流程,诸君多看看代码,也应该没问题。首先是三钟 Channels 集合,源码中我加了注释,好理解,主要是划重点的地方:
首先是 mapConfig 取得不同 headerValue 对应的 Channels ,然后放入 channelMapping,接下来是 optionalChannels ,将配置中对应的值放入其中, 并且不能是 channelMapping 的值。如果两者都没有匹配值就使用 defaultChannels。
OK,各位看到这里就应该对Channel的执行过程都了解了。
Sink
Sink用于采集Channel数据,然后进行日志持久化或者传输到另外一个Source,Sink 线程独立。
Sink 把 Event 送到 外部存储结构或是 flow 的下个 Flume。一样,看源码先:
public interface Sink extends LifecycleAware, NamedComponent {
public void setChannel(Channel channel);
public Channel getChannel();
public Status process() throws EventDeliveryException;
public static enum Status {
READY, BACKOFF
}很显然,Sink 与 source 在接口上的定义是一个道理的,其消费配置的 Channel 中的 Event ,然后送到指定位置。然后看看抽象
public abstract class AbstractSink implements Sink, LifecycleAware {
private Channel channel;
private String name;
private LifecycleState lifecycleState;
public AbstractSink() {
lifecycleState = LifecycleState.IDLE;
}
@Override
public synchronized void start() {
Preconditions.checkState(channel != null, "No channel configured");
lifecycleState = LifecycleState.START;
}
@Override
public synchronized void stop() {
lifecycleState = LifecycleState.STOP;
}
@Override
public synchronized Channel getChannel() {
return channel;
}
@Override
public synchronized void setChannel(Channel channel) {
this.channel = channel;
}
@Override
public synchronized LifecycleState getLifecycleState() {
return lifecycleState;
}
@Override
public synchronized void setName(String name) {
this.name = name;
}
@Override
public synchronized String getName() {
return name;
}
@Override
public String toString() {
return this.getClass().getName() + "{name:" + name + ", channel:" + channel.getName() + "}";
}
}如果前面看懂了,这个也应该没啥好说的,大体和 Source 没什么差,同样是维护状态和 Channel 的操作。Sink 实现流程和 Source 不一样的是 ,只有一种,也就是说只有一种 SinkRunner, 其调用 start 方法启动线程,stop 方法来清理资源。然后 Sink 有一个核心方法,process。其是实现 Event 传输的关键,实现了事务,摘一个简单的 sink 实现(RollingFileSink)来看看 process
public Status process() throws EventDeliveryException {
//是否要求关闭
if (shouldRotate) {
logger.debug("Time to rotate {}", pathController.getCurrentFile());
if (outputStream != null) {
logger.debug("Closing file {}", pathController.getCurrentFile());
//关闭
try {
serializer.flush();
serializer.beforeClose();
outputStream.close();
sinkCounter.incrementConnectionClosedCount();
shouldRotate = false;
} catch (IOException e) {
sinkCounter.incrementConnectionFailedCount();
throw new EventDeliveryException("Unable to rotate file "
+ pathController.getCurrentFile() + " while delivering event", e);
} finally {
serializer = null;
outputStream = null;
}
//写下一个文件
pathController.rotate();
}
}
if (outputStream == null) {
//取当前文件名
File currentFile = pathController.getCurrentFile();
logger.debug("Opening output stream for file {}", currentFile);
try {
outputStream = new BufferedOutputStream(
new FileOutputStream(currentFile));
serializer = EventSerializerFactory.getInstance(
serializerType, serializerContext, outputStream);
serializer.afterCreate();
sinkCounter.incrementConnectionCreatedCount();
} catch (IOException e) {
sinkCounter.incrementConnectionFailedCount();
throw new EventDeliveryException("Failed to open file "
+ pathController.getCurrentFile() + " while delivering event", e);
}
}
//事务
Channel channel = getChannel();
Transaction transaction = channel.getTransaction();
Event event = null;
Status result = Status.READY;
try {
transaction.begin();
int eventAttemptCounter = 0;
for (int i = 0; i < batchSize; i++) {
//发送数据
event = channel.take();
if (event != null) {
sinkCounter.incrementEventDrainAttemptCount();
eventAttemptCounter++;
serializer.write(event);
/*
* FIXME: Feature: Rotate on size and time by checking bytes written and
* setting shouldRotate = true if we're past a threshold.
*/
/*
* FIXME: Feature: Control flush interval based on time or number of
* events. For now, we're super-conservative and flush on each write.
*/
} else {
// No events found, request back-off semantics from runner
result = Status.BACKOFF;
break;
}
}
serializer.flush();
outputStream.flush();
transaction.commit();
sinkCounter.addToEventDrainSuccessCount(eventAttemptCounter);
} catch (Exception ex) {
transaction.rollback();
throw new EventDeliveryException("Failed to process transaction", ex);
} finally {
transaction.close();
}
return result;
}拿这段代码只是方便说明 process 所起的作用,实际上 RollingFileSink 是比较简单的处理,流程上来说就是先判断是否需要关闭文件,关闭的话就会重新开始。如果不需要,则一直写下一个文件。
Sink 最后提一点(真的只是提一提),关于 SinkGroup的,有三种 Process 实现,Default 、Failover 和 Load balancing。
默认的很简单,一个空的 configure,process 方法直接返回了 sink 本身的 process 方法。
至于故障转移和负载均衡,源码我还没看,以后有机会再说吧。
最后说下可靠性问题
ng 提供 end-to-end 支持,取得数据的 agent 会将 event 写入硬盘,在数据由 source 传入 channel 后,才进行删除,如果数据传输失败,可以重新进行传输。这部分的实现我没去研究,有兴趣的基佬呸!同学可以去[这里看看](https://github.com/apache/flume/tree/trunk/flume-ng-core/src/main/java/org/apache/flume/source)
三、Flume应用问题
实主这里主要看实际应用,这里贴一些常用的配置:
1.multi-agent flow
为了数据流能跨多个 agent 或 hops,前一个 agent 的 sink 和当前 hop 的 source 需要是 avro 类型的,并且 sink 指向 source 的主机名(或IP地址)和端口。
流程如图(官网扒的):

2.Consolidation
可以通过配置一定数量第一层 agent 的 avro 型 sink,并全部指向唯一 agent 的 avro 型 source( 在这种情况下,agent 同样可以使用 thrift 型的 sources/sinks/clients)。第二层 agent 的 source 将接收到的事件 consolidation 到唯一的 Channel,然后连接到最终的 sink 中。
流程如图(官网扒的):
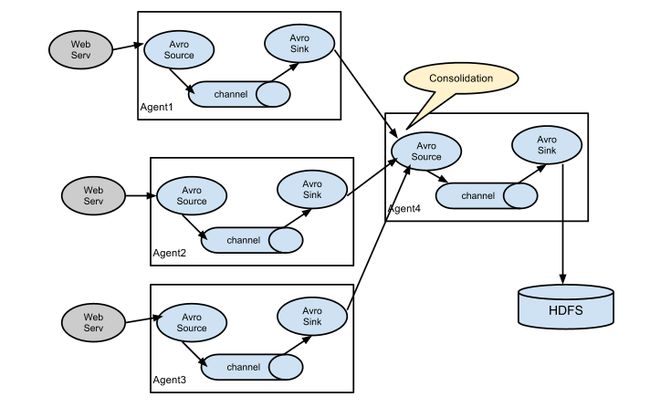
常见应用场景为日志收集:
大量客户端产生的日志数据发送到一些消费者 agent,以连接到存储子系统。例如,从数以百计的 web服务器收集日志发送到许多 agent 然后写入到 HDFS 集群。一个很常见的场景,在日志收集大量的生产日志客户端发送数据到一些消费者代理连接到存储子系统。例如,从数以百计的 web服务器收集日志发送到打代理写 HDFS 集群。
3.Multiplexing the flow**
实现是通过定义一个流复用器,即将可以复制或选择性的 event 路由到多个 Channel,然后送给各自的 sink。
流程如图(官网扒的):
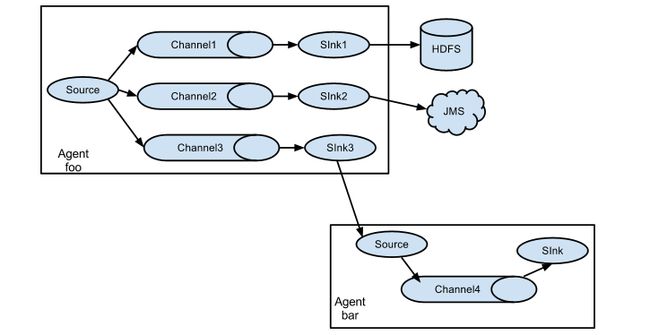
上图我们可以看到 Agent foo 展开到三个不同的 Channel。这样的展开是可复制并且可复用的。在复制的情况下,每个 event 被发送到了3个 Channel 中;
而在复用的情况下,各个 event 被发送到 event 属性所匹配预配值的可用 Channel中(子集)。举个栗子,一个事件的属性为 “txnType”,其被设置为 “客户”,那则应该被发往 Channel1、Channel3,如果属性是 “vendor”,则发往 Channel2,其余都发往 Channel3。这种映射可以在 agent 的配置文件中配置。
全篇到这里也就告一个段落了,其实还是有些东西没能写出来,感觉太杂,无法描述(咦)。不过大体 Flume 的源码结构应该都有说到。说实话,源码还是要自己看才好,看不明白,再看看别人的见解,这要又有深度,又有效率。
在下笔力不堪,从这摘了点图文
源码这来的