chapter7 Ensemble Learning and Random Forests(集成学习和随机森林)
合并了一组分类器的预测(像分类或者回归),得到一个比单一分类器更好的预测结果。这一组分类器就叫做集成;因此,这个技术就叫做集成学习,一个集成学习算法就叫做集成方法。
例如,你可以训练一组决策树分类器,每一个都在一个随机的训练集上。为了去做预测,你必须得到所有单一树的预测值,然后通过投票(例如第六章的练习)来预测类别。例如一种决策树的集成就叫做随机森林,它除了简单之外也是现今存在的最强大的机器学习算法之一。
像在第二章讨论的一样,会在一个项目快结束的时候使用集成算法,一旦建立了一些好的分类器,就把他们合并为一个更好的分类器。事实上,在机器学习竞赛中获得胜利的算法经常会包含一些集成方法。
在本章中会讨论一下特别著名的集成方法,包括 bagging, boosting, stacking,和其他一些算法。也会讨论随机森林。
设置
from __future__ import division,print_function,unicode_literals
import numpy as np
np.random.seed(42)
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['xtick.labelsize'] = 12
import os
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "ensembles"
def image_path(fig_id):
return os.path.join(PROJECT_ROOT_DIR,"images",CHAPTER_ID,fig_id)
def save_fig(fig_id,tight_layout = True):
print("Saving_figure",fig_id)
if tight_layout:
plt.tight_layout()
plt.saving(image_path(fig)id) + ".png",format = 'png',dpi = 300)
import warnings
warnings.filterwarnings(action = "ignore",module = "scipy",message = "^interal gelsd")
投票分类
假设已经训练了一些分类器,每一个都有 80% 的准确率。可能有了一个逻辑回归、或一个 SVM、或一个随机森林,或者一个 KNN分类器,或许还有更多(详见图 7-1)。
图7-1. 训练多种分类器
一个非常简单的创建一个更好的分类器的方法就是去整合每一个分类器的预测然后经过投票预测分类。这种分类器叫做硬投票分类器(详见图 7-2)。
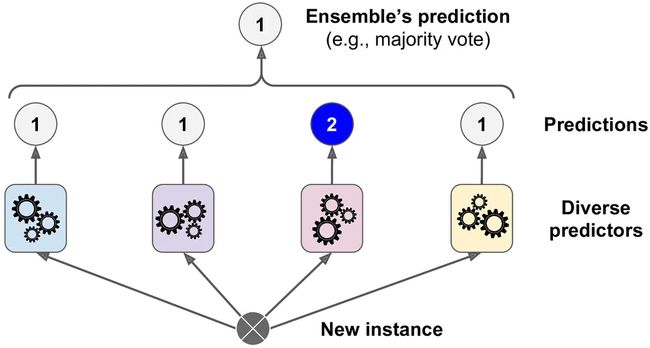
图7-2. 硬投票分类器
令人惊奇的是这种投票分类器得出的结果经常会比集成中最好的一个分类器结果更好。事实上,即使每一个分类器都是一个弱学习器(意味着它们也就比瞎猜好点),集成后仍然是一个强学习器(高准确率),只要有足够数量的弱学习者,他们就足够多样化。
这怎么可能?接下来的分析将帮助我们解决这个疑问。
大数定律
假设有一个有偏差的硬币,有 51% 的几率为正面,49% 的几率为背面。如果实验 1000 次,会得到差不多 510 次正面,490 次背面,因此大多数都是正面。如果用数学计算,会发现在实验 1000 次后,正面为多数的概率接近 75%。实验的次数越多,正面为多数的比例越大(例如试验了 10000 次,总体比例可能性就会达到 97%)。这是因为大数定律 :当一直用硬币实验时,正面的比例会越来越接近 51%。
head_proba = 0.51
coin_tosses = (np.random.rand(10000,10) < head_proba).astype(np.int32)
cumulative_heads_ratio = np.cumsum(coin_tosses,axis = 0) / np.arange(1,10001).reshape(-1,1)
plt.figure(figsize = (8,3.5))
plt.plot(cumulative_heads_ratio)
plt.plot([0,10000],[0.51,0.51],"k--",linewidth = 2,label = "51%")
plt.plot([0,10000],[0.5,0.5],"k-",label = "50%")
plt.xlabel("Number of coin tosses")
plt.ylabel("Heads ratio")
plt.legend(loc = "lower right")
plt.axis([0,10000,0.42,0.58])
save_fig("law_of_large_numbers_plot")
plt.show()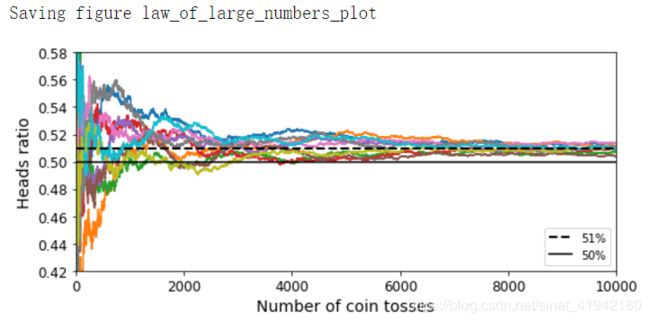
图 7-3 (上图)展示了始终有偏差的硬币实验。可以看到当实验次数上升时,正面的概率接近于 51%。最终所有 10 种实验都会收敛到 51%,它们都大于 50%。
同样的,假设创建了一个包含 1000 个分类器的集成模型,其中每个分类器的正确率只有 51%(仅比瞎猜好一点点)。如果用投票去预测类别,可能得到 75% 的准确率!然而,这仅仅在所有的分类器都独立运行的很好、不会发生有相关性的错误的情况下才会这样,然而每一个分类器都在同一个数据集上训练,导致其很可能会发生这样的错误。他们可能会犯同一种错误,所以也会有很多票投给了错误类别导致集成的准确率下降。
如果使每一个分类器都独立自主的分类,那么集成模型会工作的很好。得到多样的分类器的方法之一就是用完全不同的算法,这会使它们会做出不同种类的错误,但会提高集成的正确率。
接下来的代码创建和训练了在 sklearn 中的投票分类器。这个分类器由三个不同的分类器组成(训练集是第五章中的 moons 数据集):
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X,y = make_moons(n_samples = 500,noise = 0.30,random_state = 42)
X_train,X_test,y_train,y_test = train_test_split(X,y)
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf = LogisticRegression(solver = "liblinear",random_state = 42)
rnd_clf = RandomForestClassifier(n_estimators = 10,random_state = 42)
svm_clf = SVC(gamma = "auto",random_state = 42)
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc',svm_clf)],
voting='hard')
voting_clf.fit(X_train, y_train)

警告:在sci - learn 0.20中,一些超参数(solver、n_estimators、gamma等)开始发出警告,说明它们的默认值将在sci - learn 0.22中发生变化。为了避免这些警告并确保本笔记本继续产生与书中相同的输出,将超参数设置为它们原来的默认值。
看一下在测试集上的准确率:
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
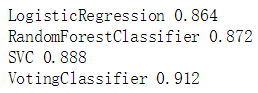
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))

可以看到,投票分类器比其他单独的分类器表现的都要好。
如果所有的分类器都能够预测类别的概率(例如他们有一个predict_proba()方法),那么就可以让 sklearn 以最高的类概率来预测这个类,平均在所有的分类器上。这种方式叫做软投票。他经常比硬投票表现的更好,因为它给予高自信的投票更大的权重。
可以通过把voting="hard"设置为voting="soft"来保证分类器可以预测类别概率。然而这不是 SVC 类的分类器默认的选项,所以需要把SVC的probability hyperparameter设置为True(这会使 SVC 使用交叉验证去预测类别概率,其降低了训练速度,但会添加predict_proba()方法)。
log_clf = LogisticRegression(solver = "liblinear",random_state = 42)
rnd_clf = RandomForestClassifier(n_estimators = 10,random_state = 42)
svm_clf = SVC(gamma = "auto",probability = True,random_state = 42)
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc',svm_clf)],
voting='soft')
voting_clf.fit(X_train, y_train)

from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
Bagging 和 Pasting
就像之前讲到的,可以通过使用不同的训练算法去得到一些不同的分类器。另一种方法就是对每一个分类器都使用相同的训练算法,但是在不同的训练集上去训练它们。有放回采样被称为装袋(Bagging,是 bootstrap aggregating 的缩写)。无放回采样称为粘贴(pasting)。
换句话说,Bagging 和 Pasting 都允许在多个分类器上对训练集进行多次采样,但只有 Bagging 允许对同一种分类器上对训练集进行进行多次采样。采样和训练过程如图7-4所示。

图7-4. Bagging/Pasting训练集采样和训练
当所有的分类器被训练后,集成可以通过对所有分类器结果的简单聚合来对新的实例进行预测。聚合函数通常对分类是统计模式(例如硬投票分类器)或者对回归是平均。每一个单独的分类器在如果在原始训练集上都是高偏差,但是聚合降低了偏差和方差。通常情况下,集成的结果是有一个相似的偏差,但是对比与在原始训练集上的单一分类器来讲有更小的方差。
正如在图 7-4 上所看到的,分类器可以通过不同的 CPU 核或其他的服务器一起被训练。相似的,分类器也可以一起被制作。这就是为什么 Bagging 和 Pasting 是如此流行的原因之一:它们的可扩展性很好。
在 sklearn 中的 Bagging 和 Pasting
sklearn 为 Bagging 和 Pasting 提供了一个简单的API:BaggingClassifier类(或者对于回归可以是BaggingRegressor。接下来的代码训练了一个 500 个决策树分类器的集成,每一个都是在数据集上有放回采样 100 个训练实例下进行训练(这是 Bagging 的例子,如果想尝试 Pasting,就设置bootstrap=False)。n_jobs参数告诉 sklearn 用于训练和预测所需要 CPU 核的数量。(-1 代表着 sklearn 会使用所有空闲核):
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(DecisionTreeClassifier(random_stete = 42),
n_estimators = 500,
max_samples = 100,
bootstrap = True,
n_jobs = -1,
random_state = 42)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test,y_pred))![]()
tree_clf = DecisionTreeClassifier(random_state = 42)
tree_clf.fit(X_train,y_train)
y_pred_tree = tree_clf.predict(X_test)
print(accuracy_score(y_test,y_pred_tree)) ![]()
笔记
如果基分类器可以预测类别概率(例如它拥有predict_proba()方法),那么BaggingClassifier会自动的运行软投票,这是决策树分类器的情况。
单一决策树 vs 500棵树的bagging集成
from matplotlib.colors import ListedColormap
def plot_decision_boundary(clf,X,y,axes = [-1.5,2.5,-1,1.5],alpha = 0.5,contour = True):
x1s = np.linspace(axes[0],axes[1],100)
x2s = np.linspace(axes[2],axes[3],100)
x1,x2 = np.meshgrid(x1s,x2s)
X_new = np.c_[x1.ravel(),x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap('#fafab0','#9898ff','#507d50')
plt.contourf(x1,x2,y_pred,alpha = 0.3,cmap = custom_cmap)
if contour:
custom_cmap2 = ListedColormap('#7d7d58','#4c4c7f','#507d50')
plt.contourf(x1,x2,y_pred,alpha = 0.8,cmap = custom_cmap2)
plt.plot(X[:,0][y == 0],X[:,1][y == 0],"yo",alpha = alpha)
plt.plot(X[:,0][y == 1],X[:,1][y == 1],"bs",alpha = alpha)
plt.axis(axes)
plt.xlabel(r"$x_1$",fontsize = 18)
plt.ylabel(r"$x_2$",fontsize = 18,rotation = 0)
plt.figure(figsize = (11,4))
plt.subplot(121)
plot_decision_boundary(tree_clf,X,y)
plt.title("Decision Tree",fontsize = 14)
plt.subplot(122)
plot_decision_boundary(bag_clf,X,y)
plt.title("Decision Tree with Bagging",fontsize = 14)
save_fig("decision_tree_without_and_with_bagging_plot")
plt.show()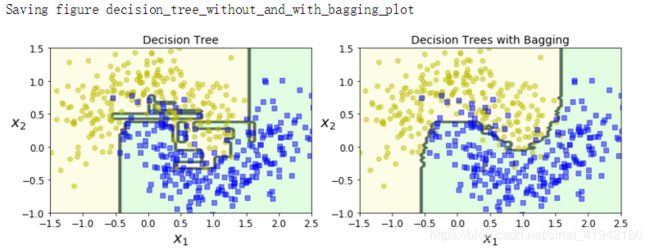
图 7-5 (上图)对比了单一决策树的决策边界和 Bagging 集成 500 个树的决策边界,两者都在 moons 数据集上训练。正如所看到的,集成的分类比起单一决策树的分类产生情况更好:集成有一个可比较的偏差但是有一个较小的方差(它在训练集上的错误数目大致相同,但决策边界较不规则)。
Out-of-Bag 评价
对于 Bagging 来说,一些实例可能被一些分类器重复采样,但其他的有可能不会被采样。BaggingClassifier默认是有放回的采样m个实例 (bootstrap=True),其中m是训练集的大小,这意味着平均下来只有63%的训练实例被每个分类器采样,剩下的37%个没有被采样的训练实例就叫做 Out-of-Bag 实例。注意对于每一个的分类器它们的 37% 不是相同的。
因为在训练中分类器从来没有看到过 oob 实例(没有被采样的训练实例),所以它可以在这些实例上进行评估,而不需要单独的验证集或交叉验证。可以拿出每一个分类器的 oob 来评估集成本身。
在 sklearn 中,需要在训练后创建一个BaggingClassifier时设置oob_score=True来自动评估。接下来的代码展示了这个操作。评估结果通过变量oob_score_来显示:
bag_clf = BaggingClassifier(DecisionTreeClassifier(random_state = 42),
n_estimators=500,
bootstrap=True,
n_jobs=-1,
oob_score=True,
random_state = 40)
bag_clf.fit(X_train, y_train)
bag_clf.oob_score_
![]()
根据这个 oob 评估,BaggingClassifier可以在测试集上达到91.2%的准确率:
from sklearn.metrics import accuracy_score
y_pred = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred) ![]()
在测试集上得到了 91.2% 的准确率,足够接近了!
对于每个训练实例 oob 决策函数也可通过oob_decision_function_变量来展示。在这种情况下(当基决策器有predict_proba()时)决策函数会对每个训练实例返回类别概率。
bag_clf.oob_decision_function_ array([[0.31746032, 0.68253968],
[0.34117647, 0.65882353],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[0.08379888, 0.91620112],
[0.31693989, 0.68306011],
[0.02923977, 0.97076023],
[0.97687861, 0.02312139],
[0.97765363, 0.02234637],
[0.74404762, 0.25595238],
[0. , 1. ],
[0.71195652, 0.28804348],
[0.83957219, 0.16042781],
[0.97777778, 0.02222222],
[0.0625 , 0.9375 ],
[0. , 1. ],
[0.97297297, 0.02702703],
[0.95238095, 0.04761905],
[1. , 0. ],
[0.01704545, 0.98295455],
[0.38947368, 0.61052632],
[0.88700565, 0.11299435],
[1. , 0. ],
[0.96685083, 0.03314917],
[0. , 1. ],
[0.99428571, 0.00571429],
[1. , 0. ],
[0. , 1. ],
[0.64804469, 0.35195531],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[0.13402062, 0.86597938],
[1. , 0. ],
[0. , 1. ],
[0.36065574, 0.63934426],
[0. , 1. ],
[1. , 0. ],
[0.27093596, 0.72906404],
[0.34146341, 0.65853659],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[1. , 0. ],
[0.00531915, 0.99468085],
[0.98265896, 0.01734104],
[0.91428571, 0.08571429],
[0.97282609, 0.02717391],
[0.97029703, 0.02970297],
[0. , 1. ],
[0.06134969, 0.93865031],
[0.98019802, 0.01980198],
[0. , 1. ],
[0. , 1. ],
[0. , 1. ],
[0.97790055, 0.02209945],
[0.79473684, 0.20526316],
[0.41919192, 0.58080808],
[0.99473684, 0.00526316],
[0. , 1. ],
[0.67613636, 0.32386364],
[1. , 0. ],
[1. , 0. ],
[0.87356322, 0.12643678],
[1. , 0. ],
[0.56140351, 0.43859649],
[0.16304348, 0.83695652],
[0.67539267, 0.32460733],
[0.90673575, 0.09326425],
[0. , 1. ],
[0.16201117, 0.83798883],
[0.89005236, 0.10994764],
[1. , 0. ],
[0. , 1. ],
[0.995 , 0.005 ],
[0. , 1. ],
[0.07272727, 0.92727273],
[0.05418719, 0.94581281],
[0.29533679, 0.70466321],
[1. , 0. ],
[0. , 1. ],
[0.81871345, 0.18128655],
[0.01092896, 0.98907104],
[0. , 1. ],
[0. , 1. ],
[0.22513089, 0.77486911],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[0. , 1. ],
[0.9368932 , 0.0631068 ],
[0.76536313, 0.23463687],
[0. , 1. ],
[1. , 0. ],
[0.17127072, 0.82872928],
[0.65306122, 0.34693878],
[0. , 1. ],
[0.03076923, 0.96923077],
[0.49444444, 0.50555556],
[1. , 0. ],
[0.02673797, 0.97326203],
[0.98870056, 0.01129944],
[0.23121387, 0.76878613],
[0.5 , 0.5 ],
[0.9947644 , 0.0052356 ],
[0.00555556, 0.99444444],
[0.98963731, 0.01036269],
[0.25641026, 0.74358974],
[0.92972973, 0.07027027],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[0.80681818, 0.19318182],
[1. , 0. ],
[0.0106383 , 0.9893617 ],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[0.98181818, 0.01818182],
[1. , 0. ],
[0.01036269, 0.98963731],
[0.97752809, 0.02247191],
[0.99453552, 0.00546448],
[0.01960784, 0.98039216],
[0.18367347, 0.81632653],
[0.98387097, 0.01612903],
[0.29533679, 0.70466321],
[0.98295455, 0.01704545],
[0. , 1. ],
[0.00561798, 0.99438202],
[0.75138122, 0.24861878],
[0.38624339, 0.61375661],
[0.42708333, 0.57291667],
[0.86315789, 0.13684211],
[0.92964824, 0.07035176],
[0.05699482, 0.94300518],
[0.82802548, 0.17197452],
[0.01546392, 0.98453608],
[0. , 1. ],
[0.02298851, 0.97701149],
[0.96721311, 0.03278689],
[1. , 0. ],
[1. , 0. ],
[0.01041667, 0.98958333],
[0. , 1. ],
[0.0326087 , 0.9673913 ],
[0.01020408, 0.98979592],
[1. , 0. ],
[1. , 0. ],
[0.93785311, 0.06214689],
[1. , 0. ],
[1. , 0. ],
[0.99462366, 0.00537634],
[0. , 1. ],
[0.38860104, 0.61139896],
[0.32065217, 0.67934783],
[0. , 1. ],
[0. , 1. ],
[0.31182796, 0.68817204],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[1. , 0. ],
[0.00588235, 0.99411765],
[0. , 1. ],
[0.98387097, 0.01612903],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ],
[0.62264151, 0.37735849],
[0.92344498, 0.07655502],
[0. , 1. ],
[0.99526066, 0.00473934],
[1. , 0. ],
[0.98888889, 0.01111111],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[0.06451613, 0.93548387],
[1. , 0. ],
[0.05154639, 0.94845361],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ],
[0.03278689, 0.96721311],
[1. , 0. ],
[0.95808383, 0.04191617],
[0.79532164, 0.20467836],
[0.55665025, 0.44334975],
[0. , 1. ],
[0.18604651, 0.81395349],
[1. , 0. ],
[0.93121693, 0.06878307],
[0.97740113, 0.02259887],
[1. , 0. ],
[0.00531915, 0.99468085],
[0. , 1. ],
[0.44623656, 0.55376344],
[0.86363636, 0.13636364],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[0.00558659, 0.99441341],
[0. , 1. ],
[0.96923077, 0.03076923],
[0. , 1. ],
[0.21649485, 0.78350515],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[0.98477157, 0.01522843],
[0.8 , 0.2 ],
[0.99441341, 0.00558659],
[0. , 1. ],
[0.08379888, 0.91620112],
[0.98984772, 0.01015228],
[0.01142857, 0.98857143],
[0. , 1. ],
[0.02747253, 0.97252747],
[1. , 0. ],
[0.79144385, 0.20855615],
[0. , 1. ],
[0.90804598, 0.09195402],
[0.98387097, 0.01612903],
[0.20634921, 0.79365079],
[0.19767442, 0.80232558],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[0. , 1. ],
[0.20338983, 0.79661017],
[0.98181818, 0.01818182],
[0. , 1. ],
[1. , 0. ],
[0.98969072, 0.01030928],
[0. , 1. ],
[0.48663102, 0.51336898],
[1. , 0. ],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[0.07821229, 0.92178771],
[0.11176471, 0.88823529],
[0.99415205, 0.00584795],
[0.03015075, 0.96984925],
[1. , 0. ],
[0.40837696, 0.59162304],
[0.04891304, 0.95108696],
[0.51595745, 0.48404255],
[0.51898734, 0.48101266],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[0.59903382, 0.40096618],
[0. , 1. ],
[1. , 0. ],
[0.24157303, 0.75842697],
[0.81052632, 0.18947368],
[0.08717949, 0.91282051],
[0.99453552, 0.00546448],
[0.82142857, 0.17857143],
[0. , 1. ],
[0. , 1. ],
[0.125 , 0.875 ],
[0.04712042, 0.95287958],
[0. , 1. ],
[1. , 0. ],
[0.89150943, 0.10849057],
[0.1978022 , 0.8021978 ],
[0.95238095, 0.04761905],
[0.00515464, 0.99484536],
[0.609375 , 0.390625 ],
[0.07692308, 0.92307692],
[0.99484536, 0.00515464],
[0.84210526, 0.15789474],
[0. , 1. ],
[0.99484536, 0.00515464],
[0.95876289, 0.04123711],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[0. , 1. ],
[1. , 0. ],
[0.26903553, 0.73096447],
[0.98461538, 0.01538462],
[1. , 0. ],
[0. , 1. ],
[0.00574713, 0.99425287],
[0.85142857, 0.14857143],
[0. , 1. ],
[1. , 0. ],
[0.76506024, 0.23493976],
[0.8969697 , 0.1030303 ],
[1. , 0. ],
[0.73333333, 0.26666667],
[0.47727273, 0.52272727],
[0. , 1. ],
[0.92473118, 0.07526882],
[0. , 1. ],
[1. , 0. ],
[0.87709497, 0.12290503],
[1. , 0. ],
[1. , 0. ],
[0.74752475, 0.25247525],
[0.09146341, 0.90853659],
[0.44329897, 0.55670103],
[0.22395833, 0.77604167],
[0. , 1. ],
[0.87046632, 0.12953368],
[0.78212291, 0.21787709],
[0.00507614, 0.99492386],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[0.02884615, 0.97115385],
[0.96571429, 0.03428571],
[0.93478261, 0.06521739],
[1. , 0. ],
[0.49756098, 0.50243902],
[1. , 0. ],
[0. , 1. ],
[1. , 0. ],
[0.01604278, 0.98395722],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[0.96987952, 0.03012048],
[0. , 1. ],
[0.05747126, 0.94252874],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[0.98989899, 0.01010101],
[0.01675978, 0.98324022],
[1. , 0. ],
[0.13541667, 0.86458333],
[0. , 1. ],
[0.00546448, 0.99453552],
[0. , 1. ],
[0.41836735, 0.58163265],
[0.11309524, 0.88690476],
[0.22110553, 0.77889447],
[1. , 0. ],
[0.97647059, 0.02352941],
[0.22826087, 0.77173913],
[0.98882682, 0.01117318],
[0. , 1. ],
[0. , 1. ],
[1. , 0. ],
[0.96428571, 0.03571429],
[0.33507853, 0.66492147],
[0.98235294, 0.01764706],
[1. , 0. ],
[0. , 1. ],
[0.99465241, 0.00534759],
[0. , 1. ],
[0.06043956, 0.93956044],
[0.97619048, 0.02380952],
[1. , 0. ],
[0.03108808, 0.96891192],
[0.57291667, 0.42708333]])例如,oob 评估预测第二个训练实例有 34.1% 的概率属于正类(65.9% 属于负类)。
随机贴片与随机子空间
BaggingClassifier也支持采样特征。它被两个超参数max_features和bootstrap_features控制。他们的工作方式和max_samples和bootstrap一样,但这是对于特征采样而不是实例采样。因此,每一个分类器都会被在随机的输入特征内进行训练。
当在处理高维度输入下(例如图片)此方法尤其有效。对训练实例和特征的采样被叫做随机贴片。保留了所有的训练实例(例如bootstrap=False和max_samples=1.0),但是对特征采样(bootstrap_features=True并且/或者max_features小于 1.0)叫做随机子空间。
采样特征导致更多的预测多样性,用高偏差换低方差。
随机森林
正如所讨论的,随机森林是决策树的一种集成,通常是通过 bagging 方法(有时是 pasting 方法)进行训练,通常用max_samples设置为训练集的大小。建立一个BaggingClassifier,然后把它放入 DecisionTreeClassifier 。
bag_clf = BaggingClassifier(
DecisionTreeClassifier(splitter = "random",max_leaf_nodes = 16,random_state = 42),
n_estimators = 500,max_samples = 1.0,bootstrap = True,n_jobs = -1,random_state = 42)
bag_clf.fit(X_train,y_train)
y_pred = bag_clf.predict(X_test)
print(accuracy_score(y_test,y_pred))![]()
或者,可以使用更方便的也是对决策树优化过的RandomForestClassifier(对于回归是RandomForestRegressor)。接下来的代码训练了带有 500 个树(每个被限制为 16 叶子结点)的决策森林,使用所有空闲的 CPU 核:
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=500,max_leaf_nodes=16,
n_jobs=-1,
random_state =42)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
print(accuracy_score(y_test,y_pred_rf))![]()
对比一下两种方法的结果
np.sum(y_pred == y_pred_rf) / len(y_pred)![]()
可以看到是几乎相同的结果(接近100%),在这里需要注意:用len(y_pred)而不是len(y_pred_rf),因为0.92>0.912
除了一些例外,RandomForestClassifier使用DecisionTreeClassifier的所有超参数(决定树怎么生长),把BaggingClassifier的超参数加起来来控制集成本身。
随机森林算法在树生长时引入了额外的随机;与在节点分裂时需要找到最好分裂特征相反(详见第六章),它在一个随机的特征集中找最好的特征。它导致了树的差异性,并且再一次用高偏差换低方差,总的来说是一个更好的模型。
决策树:在节点分裂时需要找到最好分裂特征。
随机森林:在一个随机的特征集中找最好的特征。
极端随机树:当在随机森林生长树时,通过对特征使用随机阈值,使得随机树更加随机。
极端随机树
当在随机森林上生长树时,在每个结点分裂时只考虑随机特征集上的特征(正如之前讨论过的一样)。相比于找到更好的特征可以通过对特征使用随机阈值使树更加随机(像规则决策树一样)。
这种极端随机的树被简称为 Extremely Randomized Trees(极端随机树),或者更简单的称为 Extra-Tree。再一次用高偏差换低方差。它还使得 Extra-Tree 比规则的随机森林更快地训练,因为在每个节点上找到每个特征的最佳阈值是生长树最耗时的任务之一。
可以使用 sklearn 的ExtraTreesClassifier来创建一个 Extra-Tree 分类器。他的 API 跟RandomForestClassifier是相同的,相似的, ExtraTreesRegressor 跟RandomForestRegressor也是相同的 API。
很难去分辨ExtraTreesClassifier和RandomForestClassifier到底哪个更好。通常情况下是通过交叉验证来比较它们(使用网格搜索调整超参数)。
Bootstrap 在每个预测器被训练的子集中引入了更多的分集,所以 Bagging 结束时的偏差比 Pasting 更高,但这也意味着预测因子最终变得不相关,从而减少了集合的方差。总体而言,Bagging 通常会导致更好的模型,这就解释了为什么它通常是首选的。然而,如果你有空闲时间和 CPU 功率,可以使用交叉验证来评估 Bagging 和 Pasting 哪一个更好。
特征重要度
最后,如果观察一个单一决策树,重要的特征会出现在更靠近根部的位置,而不重要的特征会经常出现在靠近叶子的位置。因此可以通过计算一个特征在森林的全部树中出现的平均深度来预测特征的重要性。sklearn 在训练后会自动计算每个特征的重要度。可以通过feature_importances_变量来查看结果。
例如如下代码在 iris 数据集(第四章介绍)上训练了一个RandomForestClassifier模型,然后输出了每个特征的重要性。
from sklearn.datasets import load_iris
iris = load_iris()
rnd_clf = RandomForestClassifier(n_estimators=500,
n_jobs=-1,
random_state =42)
rnd_clf.fit(iris["data"], iris["target"])
for name,score in zip(iris["feature_names"],rnd_clf.feature_importances_):
print(name,score)
看来,最重要的特征是花瓣长度(44%)和宽度(42%),而萼片长度和宽度相对比较是不重要的(分别为 11% 和 2%)。
rnd_clf.feature_importance_![]()
plt.figure(figsize = (6,4))
for i in range(15):
tree_clf = DecisionTreeClassifier(max_leaf_nodes = 16,random_state = 42 + i)
indices_with_replacement = np.random.randint(0,len(X_train),len(X_train)))
tree_clf.fit(X[indices_with_replacement],y[indices_with_replacement])
plot_decision_boundary(tree_clf,X,y,axes = [-1.5,2.5,-1,1.5],alpha = 0.02,contour = False)
plt.show() 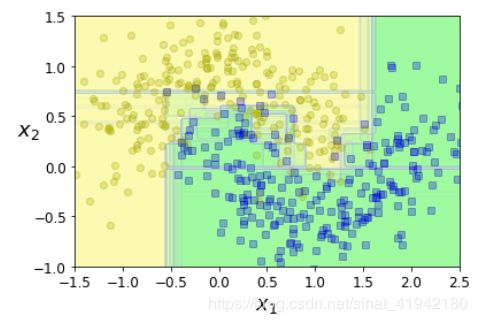
相似的,如果在 MNIST 数据及上训练随机森林分类器(在第三章上介绍),然后可以画出每个像素的重要性。
MNIST数据集像素的重要性(根据随机森林分类器)
try:
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784',version = 1,cache = True)
mnist_target = mnist.target.astype(np.int8)
expect ImportError:
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original')
rnd_clf = RandomForestClassifier(random_state = 42)
rnd_clf.fit(mnist["data"],mnist["target"]) 
def plot_digit(data):
image = data.reshape(28,28)
plt.imshow(image,cmap = matplotlib.cm.hot,interpolation = "nearest")
plt.axis("off")
plot_digit(rnd_clf.feature_importances_)
cbar = plt.colorbar(ticks = [rnd_clf.feature_importances_.min(),
rnd_clf.feature_importances_.max()])
cbae.ax.set_yticklabels(['Not important','Very important'])
save_fig("mnist_feature_importance_plot")
plt.show()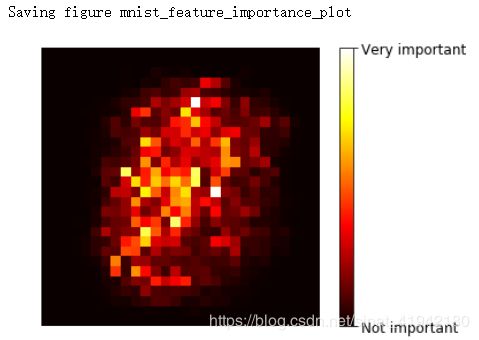
随机森林可以非常方便快速得了解哪些特征实际上是重要的,特别是需要进行特征选择的时候。
提升
提升(Boosting,最初称为假设增强)指的是可以将几个弱学习者组合成强学习者的集成方法。对于大多数的提升方法的思想就是按顺序去训练分类器,每一个都要尝试修正前面的分类。现如今已经有很多的提升方法了,但最著名的就是 Adaboost(适应性提升,是 Adaptive Boosting 的简称) 和 Gradient Boosting(梯度提升)。让我们先从 Adaboost 说起。
Adaboost
使一个新的分类器去修正之前分类结果的方法就是对之前分类结果不对的训练实例多加关注。这导致新的预测因子越来越多地聚焦于这种情况。这是 Adaboost 使用的技术。
举个例子,去构建一个 Adaboost 分类器,第一个基分类器(例如一个决策树)被训练然后在训练集上做预测,在误分类训练实例上的权重就增加了。第二个分类机使用更新过的权重然后再一次训练,权重更新,以此类推(详见图 7-7)
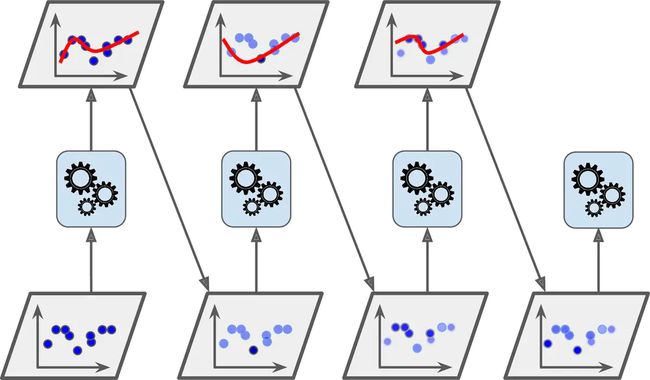
图7-7. 用实例权重更新进行AdaBoost顺序训练详细看一下 Adaboost 算法。
步骤:(1)第j个predictor的权重错误率
(2)第j个predictor的权重
(3)权重进行更新并且权重进行正则化
(4)用更新过的权重训练一个新的predictor
如此往复,直至规定的predictor数量达到或最好的predictor 被找到后算法就会停止。
每一个实例的权重wi初始都被设为1/m。第一个分类器被训练,然后他的权重误差率r1在训练集上算出,详见公式 7-1。

公式7-1:第j个分类器的权重误差率
其中 ![]() 是第
是第j个分类器对于第i实例的预测。
分类器的权重![]() 随后用公式 7-2 计算出来。其中
随后用公式 7-2 计算出来。其中η是超参数学习率(默认为 1)。分类器准确率越高,它的权重就越高。如果它只是瞎猜,那么它的权重会趋近于 0。然而,如果它总是出错(比瞎猜的几率都低),它的权重会变为负数。
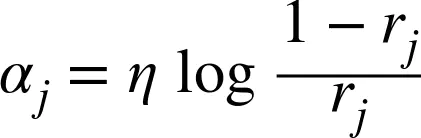
公式 7-2. 第j个预测器权重
接下来实例的权重会按照公式 7-3 更新:误分类的实例权重会被提升。
公式7-3 权重更新规则
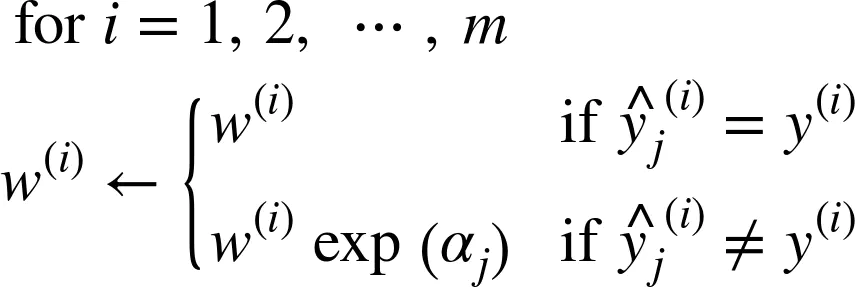
公式7-3. 权重更新规则
随后所有实例的权重都被归一化(例如被 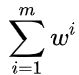 整除)。
整除)。
最后,一个新的分类器通过更新过的权重训练,整个过程被重复(新的分类器权重被计算,实例的权重被更新,随后另一个分类器被训练,以此类推)。当规定的分类器数量达到或者最好的分类器被找到后算法就会停止。
为了进行预测,Adaboost 通过分类器权重![]() 简单计算了所有的分类器和权重。预测类别会是权重投票中主要的类别。(详见公式 7-4)
简单计算了所有的分类器和权重。预测类别会是权重投票中主要的类别。(详见公式 7-4)
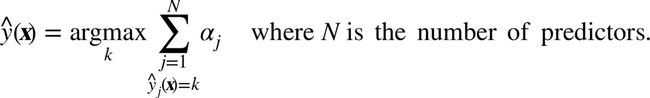
公式7-4. Adaboost 分类器
其中N是分类器的数量。
sklearn 通常使用 Adaboost 的多分类版本 SAMME(这就代表了分段加建模使用多类指数损失函数)。如果只有两类别,那么 SAMME 是与 Adaboost 相同的。如果分类器可以预测类别概率(例如如果它们有predict_proba()),如果 sklearn 可以使用 SAMME 叫做SAMME.R的变量(R 代表“REAL”),这种依赖于类别概率的通常比依赖于分类器的更好。
接下来的代码训练了使用 sklearn 的AdaBoostClassifier基于 200 个决策树桩的Adaboost 分类器(正如所期待的,对于回归也有AdaBoostRegressor)。一个决策树桩是max_depth=1的决策树,换句话说,是一个单一的决策节点加上两个叶子结点。这就是AdaBoostClassifier的默认基分类器:
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth = 1),
n_estimators = 200,algorithm = "SAMME.R",learning_rate = 0.5,random_state = 42)
ada_clf.fit(X_train,y_train)
plot_decision_boundary(ada_clf,X,y)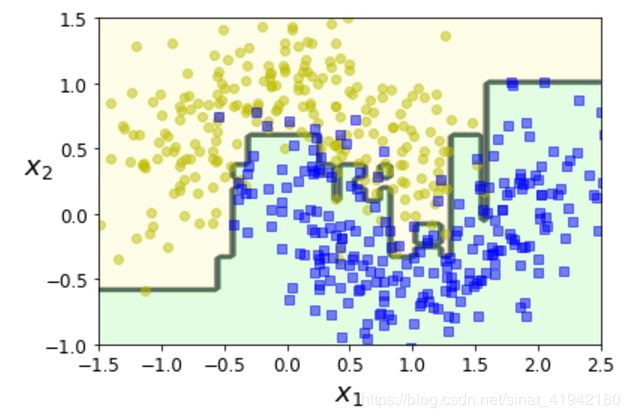
如果Adaboost 集成过拟合了训练集,可以尝试减少基分类器的数量或者对基分类器使用更强的正则化。
连续多次预测的决策边界(具体化的看一下)
m = len(X_train)
plt.figure(figsize = (11,4))
for subplot,learning_rate in ((121,1),(122,0.5)):
sample_weights = np.ones(m)
plt.subplot(subplot)
for i in range(5):
svm_clf = SVC(gamma = "auto",kernel = "rbf",C = 0.05,random_state = 42)
svm_clf.fit(X_train,y_train,sample_weight = sample_weights)
y_pred = svm_clf.predict(X_train)
sample_weights[y_pred !== y_train] *= (1 + learning_rate)
plot_decision_boundary(svm_clf,X,y,alpha = 0.2)
plt.title("learning_rate = {}".format(learning_rate),fontsize = 16)
if subplot ==121:
plt.text(-0.7,-0.65,"1",fontsize = 14)
plt.text(-0.6,-0.10,"2",fontsize = 14)
plt.text(-0.5, 0.10,"3",fontsize = 14)
plt.text(-0.4, 0.55,"4",fontsize = 14)
plt.text(-0.3, 0.90,"5",fontsize = 14)
save_fig("boosting_plot")
plt.show() 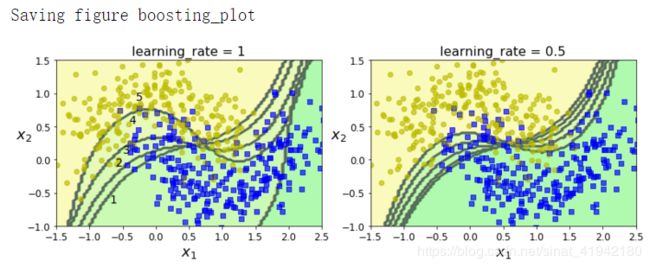
图 7-8 (上图)显示连续五次预测的 moons 数据集的决策边界(在本例中,每一个分类器都是高度正则化带有 RBF 核的 SVM)。第一个分类器误分类了很多实例,所以它们的权重被提升了。第二个分类器因此对这些误分类的实例分类效果更好,以此类推。右边的图代表了除了学习率减半外(误分类实例权重每次迭代上升一半)相同的预测序列。可以看出,除了调整单个预测因子的参数以最小化代价函数之外,序列学习技术与梯度下降很相似。AdaBoost 增加了集合的预测器,逐渐使其更好。
一旦所有的分类器都被训练后,除了分类器需要根据整个训练集上的准确率被赋予的权重外,集成预测就非常像Bagging和Pasting了。
警告
序列学习技术的一个重要的缺点就是:它不能被并行化(只能按步骤),因为每个分类器只能在之前的分类器已经被训练和评价后再进行训练。因此,它不像Bagging和Pasting一样。
list(m for m in dir(ada_clf) if not m.startswith("_") and m.endswith("_"))

梯度提升
另一个非常著名的提升算法是梯度提升。与 Adaboost 一样,梯度提升也是通过向集成中逐步增加分类器运行的,每一个分类器都修正之前的分类结果。然而,它并不像 Adaboost 那样每一次迭代都更改实例的权重,这个方法是去使用新的分类器去拟合前面分类器预测的残差 。
通过一个例子来实现一下。使用决策树当做基分类器的回归例子(回归当然也可以使用梯度提升)学习。这叫做梯度提升回归树(GBRT,Gradient Tree Boosting 或者 Gradient Boosted Regression Trees)。首先用DecisionTreeRegressor去拟合训练集(例如一个有噪二次训练集):
np.random.seed(42)
X = np.random.rand(100,1) - 0.5
y = 3 * X[:,2]**2 + 0.05 * np.random.randn(100)
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(max_depth = 2,random_state = 42)
tree_reg1.fit(X,y)
现在在第一个分类器的残差上训练第二个分类器:
y2 = y - tree_reg1.predict(X)
tree_reg2 = DecisionTreeRegressor(max_depth=2,random_state = 42)
tree_reg2.fit(X, y2)

随后在第二个分类器的残差上训练第三个分类器:
y3 = y2 - tree_reg1.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2)
tree_reg3.fit(X, y3)

现在有了一个包含三个回归器的集成。它可以通过集成所有树的预测来在一个新的实例上进行预测。
X_new = np.array([0.8])
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1,tree_reg2,tree_reg3))
y_pred![]()
def plot_predictions(regressors,X,y,axes,label = None,style = "r-",data_style = "b.",data_label = None):
x1 = np.linspace(axes[0],axes[1],500)
y_pred = sum(regressor.predict(x1.reshape(-1,1)) for regressor in regressors)
plt.plot(X[:,0],y,data_style,label = label)
plt.plot(x1,y_pred,style,linewidth = 2,label = label)
if label or data_label:
plt.legend(loc = "upper center",fontsize = 16)
plt.axis(axes)
plt.figure(figsize = (11,11))
plt.subplot(321)
plot_predictions([tree_reg1],X,y,axes = [-0.5,0.5,-0.1,0.8],label = "$h_1(x_1)$",style = "g-",data_label = "Training set")
plt.ylabel("$y$",fontsize = 16,rotation = 0)
plt.title("Residuals and tree predictions",fontsize = 16)
plt.subplot(322)
plot_predictions([tree_reg1],X,y,axes = [-0.5,0.5,-0.1,0.8],label = "$h(x_1) = h_1(x_1)$",data_label = "Training set")
plt.ylabel("$y$",fontsize = 16,rotation = 0)
plt.title("Ensemble predictions",fontsize = 16)
plt.subplot(323)
plot_predictions([tree_reg2],X,y2,axes = [-0.5,0.5,-0.1,0.8],label = "$h_2(x_1)$",style = "g-",data_style = "k+",data_label = "Residuals")
plt.ylabel("$y - h_1(x_1)$",fontsize = 16)
plt.subplot(324)
plot_predictions([tree_reg1,tree_reg2],X,y,axes = [-0.5,0.5,-0.1,0.8],label = "$h(x_1) = h_1(x_1) + h_2(x_1)$")
plt.ylabel("$y$",fontsize = 16,rotation = 0)
plt.subplot(325)
plot_predictions([tree_reg3],X,y3,axes = [-0.5,0.5,-0.5,0.5],label = "$h_3(x_1)$",style = "g-",data_style = "k+")
plt.ylabel("$y - h_1(x_1) - h_2(x_1)$",fontsize = 16)
plt.xlabel("$x_1$",fontsize = 16)
plt.subplot(326)
plot_predictions([tree_ref1,tree_reg2,tree_reg3],X,y,axes = [-0.5,0.5,-0.1,0.8],label = "$h(x_1) = h_1(x_1) + h_2(x_1) + h_3(x_1)$")
plt.ylabel("$y$",fontsize = 16,rotation = 0)
plt.xlabel("$x_1$",fontsize = 16)
save_fig("gradient_boosting_plot")
plt.show()
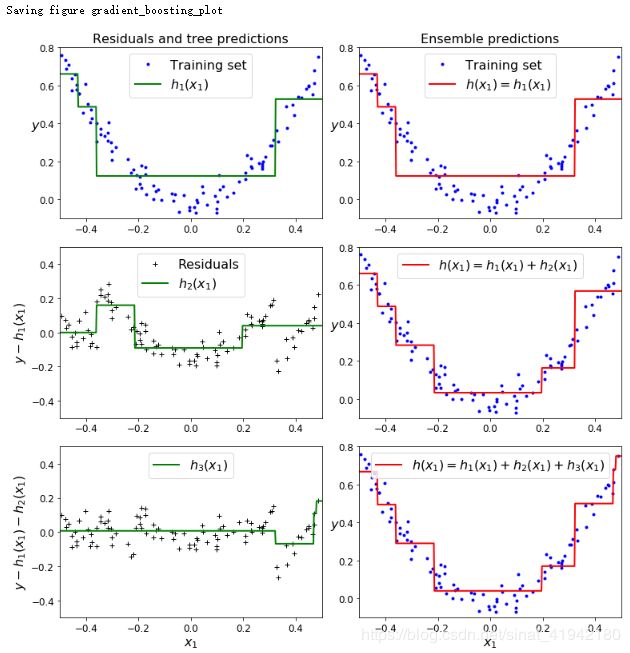
图7-9(上图)在左栏展示了这三个树的预测,在右栏展示了集成的预测。在第一行,集成只有一个树,所以它与第一个树的预测相似。在第二行,一个新的树在第一个树的残差上进行训练。在右边栏可以看出集成的预测等于前两个树预测的和。相同的,在第三行另一个树在第二个数的残差上训练。你可以看到集成的预测会变的更好。
也可以使用 sklean 中的GradientBoostingRegressor来训练 GBRT 集成。与RandomForestClassifier相似,它也有超参数去控制决策树的生长(例如max_depth,min_samples_leaf等等),也有超参数去控制集成训练,例如基分类器的数量(n_estimators)。接下来的代码创建了与之前相同的集成:
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0,random_state = 42)
gbrt.fit(X, y)

gbrt_slow = GradientBoostingRegressor(max_depth=2, n_estimators=200, learning_rate=0.1,random_state = 42)
gbrt_slow.fit(X, y)
plt.figure(figsize = (11,4))
plt.subplot(121)
plot_predictions([gbrt],X,y,axes = [-0.5,0.5,-0.1,0.8],label = "Ensemble predictions")
plt.title("learning_rate = {},n_estimators = {}".format(gbrt.learning_rate,gbrt.n_estimators),fontsize = 14)
plt.subplot(122)
plot_predictions([gbrt_slow],X,y,axes = [-0.5,0.5,-0.1,0.8])
plt.title("learning_rate = {},n_estimators = {}".format(gbrt_slow.learning_rate,gbrt_slow.n_estimators),fontsize = 14)
save_fig("gbrt_learning_rate_plot")
plt.show()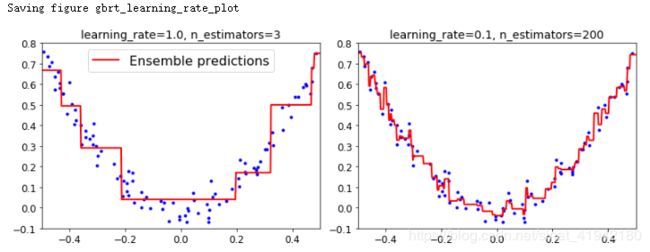
图7-10. 没有足够预测器(左)和有过多预测器(右)的GBRT集成
超参数learning_rate 确立了每个树的贡献。如果你把它设置为一个很小的树,例如 0.1,在集成中就需要更多的树去拟合训练集,但预测通常会更好。这个正则化技术叫做 shrinkage。图 7-10 展示了两个在低学习率上训练的 GBRT 集成:其中左侧是一个没有足够树去拟合训练集的树,右侧是有过多的树过拟合训练集的树。
使用过早停止(Early stopping)的梯度提升
为了找到树的最优数量,可以使用早停技术(第四章讨论过)。最简单使用这个技术的方法就是使用staged_predict():它在训练的每个阶段(用一棵树,两棵树等)返回一个迭代器。接下来的代码用 120 个树训练了一个 GBRT 集成,然后在训练的每个阶段验证错误以找到树的最佳数量,最后使用 GBRT 树的最优数量训练另一个集成:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
X_train, X_val, y_train, y_val = train_test_split(X, y)
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=120)
gbrt.fit(X_train, y_train)
errors = [mean_squared_error(y_val, y_pred) for y_pred in gbrt.staged_predict(X_val)]
bst_n_estimators = np.argmin(errors)
gbrt_best = GradientBoostingRegressor(max_depth=2,n_estimators=bst_n_estimators)
gbrt_best.fit(X_train, y_train)

min_error = np.min(errors)
plt.figure(figsize = (11,4))
plt.subplot(121)
plt.plot(errors,"b.-")
plt.plot([bst_n_estimators,bst_n_estimators],[0,min_error],"k--")
plt.plot([0,120],[min_error,min_error],"k--")
plt.plot(bst_n_estimators,min_errors,"ko")
plt.text(bst_n_estimators,min_error * 1.2,"Minimum",ha = "center",fontsize = 14)
plt.axis([0,120,0,0.01])
plt.xlabel("Number of trees")
plt.title("Validation error",fontsize = 14)
plt.subplot(122)
plt_predictions([gbrt_best],X,y,axes = [-0.5,0.5,-0.1,0.8])
plt.title("Best model (%d trees)" % bst_n_estimators,fontsize = 14)
save_fig("early_stopping_gbrt_plot")
plt.show() 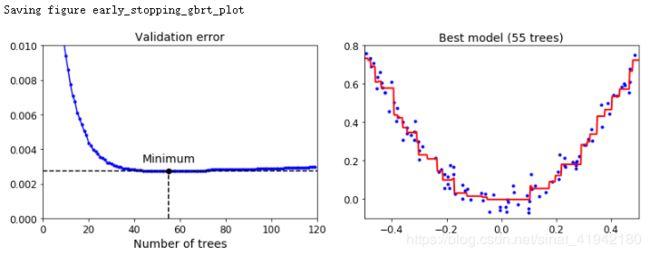
验证错误在图 7-11(上图)的左侧展示,最优模型预测被展示在上图右侧。
也可以早早的停止训练来实现早停(而不是先在一大堆树中训练,然后再回头去找最佳数量)。可以通过设置warm_start=True来实现 ,这使得当fit()方法被调用时 sklearn 保留现有树,并允许增量训练。接下来的代码在当一行中的五次迭代验证错误没有改善时会停止训练:
gbrt = GradientBoostingRegressor(max_depth = 2,warm_start = True,random_state = 42)
min_val_error = float("inf")
error_going_up = 0
for n_estimators in range(1,120):
gbrt.n_estimators = n_estimators
gbrt.fit(X_train,y_train)
y_pred = gbrt.predict(X_val)
val_error = mean_squared_error(y_val,y_pred)
if val_error < min_val_error:
min_val_error = val_error
error_going_up = 0
else:
error_going_up += 1
if error_going_up == 5:
break
print(gbrt.n_estimators)![]()
print("Minimum validation MSE:",min_val_error) ![]()
GradientBoostingRegressor也支持指定用于训练每棵树的训练实例比例的超参数subsample。例如如果subsample=0.25,那么每个树都会在 25% 随机选择的训练实例上训练。你现在也能猜出来,这也是个高偏差换低方差的作用。它同样也加速了训练。这个技术叫做随机梯度提升。
也可能对其他损失函数使用梯度提升。这是由损失超参数控制(见 sklearn 文档)。
Stacking
本章讨论的最后一个集成方法叫做 Stacking(stacked generalization 的缩写)。这个算法基于一个简单的想法:不使用琐碎的函数(如硬投票)来聚合集合中所有分类器的预测,为什么不训练一个模型来执行这个聚合?图 7-12 展示了这样一个在新的回归实例上预测的集成。底部三个分类器每一个都有不同的值(3.1,2.7 和 2.9),然后最后一个分类器(叫做 blender 或者 meta learner )把这三个分类器的结果当做输入然后做出最终决策(3.0)。
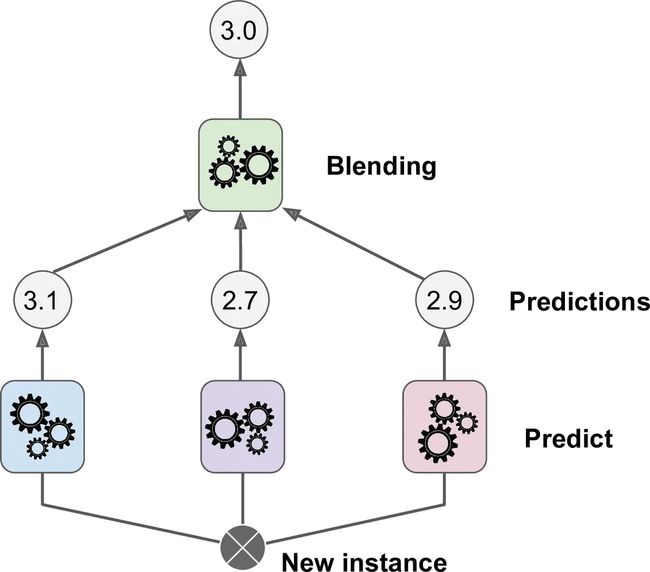
图7-12 使用混合预测期合并预测
为了训练这个 blender ,一个通用的方法是采用保持集。看看它怎么工作。首先,训练集被分为两个子集,第一个子集被用作训练第一层(详见图 7-13).
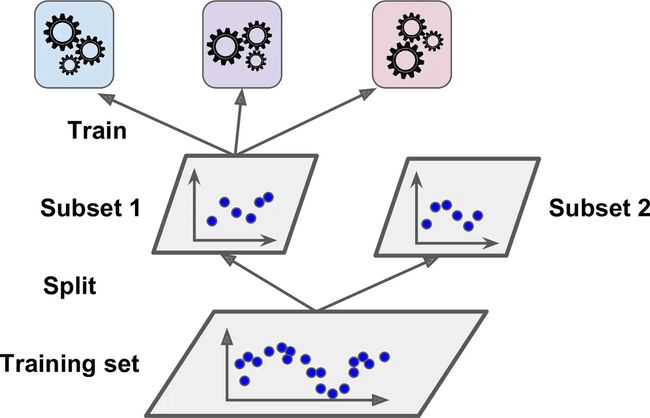
图7-13. 训练第一层
接下来,第一层的分类器被用来预测第二个子集(保持集)(详见 7-14)。这确保了预测结果很“干净”,因为这些分类器在训练的时候没有使用过这些实例。现在对在保持集中的每一个实例都有三个预测值。现在可以使用这些预测结果作为输入特征来创建一个新的训练集(这使得这个训练集是三维的),并且保持目标数值不变。随后 blender 在这个新的训练集上训练,因此,它学会了预测第一层预测的目标值。
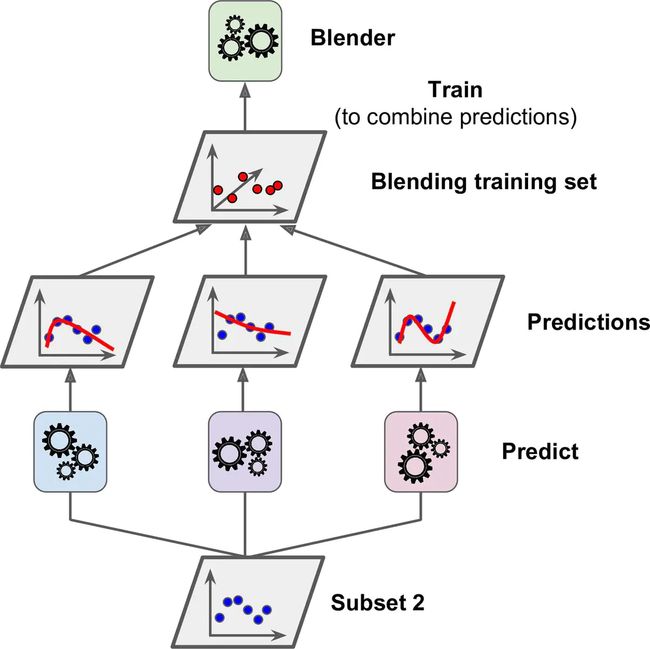
图7-14. 训练混合器
显然可以用这种方法训练不同的 blender (例如一个线性回归,另一个是随机森林等):得到了一层 blender 。诀窍是将训练集分成三个子集:第一个子集用来训练第一层,第二个子集用来创建训练第二层的训练集(使用第一层分类器的预测值),第三个子集被用来创建训练第三层的训练集(使用第二层分类器的预测值)。以上步骤做完了,我们可以通过逐个遍历每个层来预测一个新的实例。详见图 7-15.
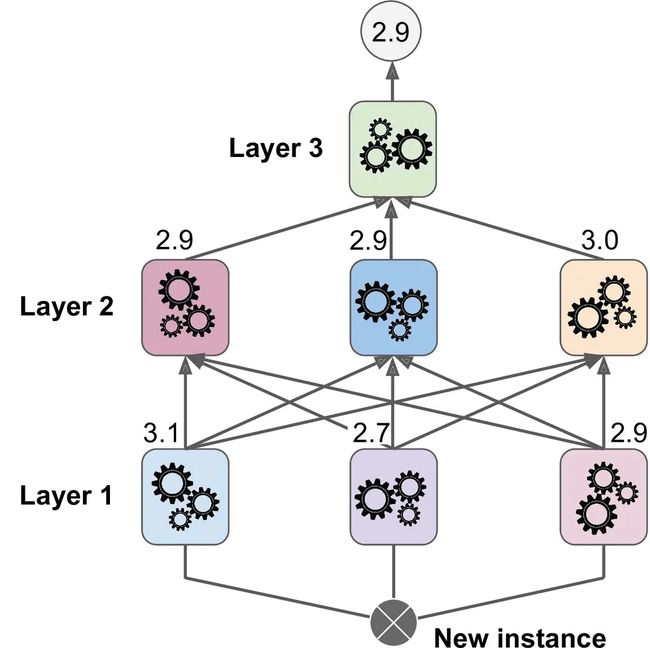
图7-15. 错层stacking集成的预测
不幸的是,sklearn 并不直接支持 stacking ,但是你自己组建是很容易的(看接下来的练习)。或者你也可以使用开源的项目例如 brew ( https://github.com/viisar/brew)。
练习
8. 导入 MNIST 数据(第三章中介绍),把它切分进一个训练集,一个验证集,和一个测试集(例如 40000 个实例进行训练,10000 个进行验证,10000 个进行测试)。然后训练多个分类器,例如一个随机森林分类器,一个 Extra-Tree 分类器和一个 SVM。接下来,尝试将它们组合成集成,使用软或硬投票分类器来胜过验证集上的所有集合。一旦找到了,就在测试集上实验。与单个分类器相比,它的性能有多好?
try:
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784',version = 1,cache = True)
mnist.target = mnist.target.astype(np.int8)
except ImportError:
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original')
from sklearn.model_selection import train_test_split
X_train_val,X_test,y_train_val,y_test = train_test_split(mnist.data,mnist.target,test_size = 1000,random_state = 42)
X_train,X_val,y_train,y_val = train_test_split(x_train_val,y_train_val,test_size = 1000,random_state = 42) 然后训练多个分类器
from sklearn.ensemble import RandomForestClassifier,ExtraTreesClassifier
from sklearn.svm import LinearSVC
from sklearn.neural_network import MLPClassifier
random_forest_clf = RandomForestClassifier(random_state = 42)
extra_trees_clf = ExtraTreesClassifier(random_state = 42)
svm_clf = LinearSVC(random_state = 42)
mlp_clf = MLPClassifier(random_state = 42)
estimators = [random_forest_clf,extra_trees_clf,svm_clf,mlp_clf]
for estimator in estimators:
print("Training the",estimator)
estimator.fit(X_train,y_train)
[estimator.score(X_vai,y_val) for estimator in estimators] ![]()
可以看到,LinearSVC的性能远远优于其他分类器。但是,暂时保留它,因为它可以提高投票分类器的性能。
接下来,尝试使用软或硬投票分类器将它们在验证集上进行组合,使得组合的输出优于它们所有。
from sklearn.ensemble import VotingClassifier
named_estimators = [
("random_forest_clf",random_forest_clf),
("extra_trees_clf",extra_trees_clf),
("svm_clf",svm_clf),
("mlp_clf",mlp_clf),
]
voting_clf = VotingClassifier(named_estimators)
voting_clf.fit(X_train,y_train)
voting_clf.score(X_val,y_val) ![]()
接下来试着删除LinearSVC,看看性能是否得到改善。可以使用set_params()将估计量设置为None来删除它,如下所示:
voting_clf.set_params(svm_clf = None)
然后更新estimators列表
voting_clf.estimators
但是,它没有更新训练过的估计器列表
voting_clf.estimators_
因此可以重新拟合投票分类器,或者从训练过的估计器列表中删除支持向量机:
del voting_clf.estimators_[2]现在再来评估一下分类器
voting_clf.score(X_val,y_val)![]()
好一点!LinearSVC损害了性能。现在尝试使用软投票分类器。实际上不需要对分类器进行再训练,只需将投票设置为“soft”,确保所有分类器都能估计出类的概率:
voting_clf.voting = "soft"
voting_clf.score(X_val,y_val)![]()
这是一个显著的改进,它比每个单独的分类器要好得多。一旦你找到了一个,在测试集上试试它。它的性能比单独的分类器好多少?
voting_clf.score(X_test,y_test)![]()
[estimator.score(X_test,y_test) for estimator in voting_clf.estimators_]![]()
投票分类器将最佳模型(MLPClassifier)的错误率从4.19%左右降低到只有3.5%。还不错!
9. 从练习 8 中运行个体分类器来对验证集进行预测,创建一个新的训练集并生成预测:每个训练实例是一个向量,包含来自所有分类器的图像的预测集,目标是图像类别。祝贺你,你刚刚训练了一个 blender ,和分类器一起组成了一个叠加组合!现在让我们来评估测试集上的集合。对于测试集中的每个图像,用所有分类器进行预测,然后将预测馈送到 blender 以获得集合的预测。它与早期训练过的投票分类器相比如何?
X_val_predictions = np.empty((len(X_val),len(estimators)),dtype = np.float32)
for index,estimator in enumerate(enumerators):
X_val_predictions[:,index] = estimator.predict(X_val)
X_val_predictions 
使用上面的预测来创建一个混合训练集,然后将其用于训练blender
rnd_forest_blender = RandomForestClassifier(n_estimators = 200,oob_score = True,random_state = 42)
rnd_forest_blender.fit(X_val_predictions,y_val)
rnd_forest_blender.oob_score_![]()
可以对这个blender进行微调,或者尝试其他类型的blender(例如MLPClassifier),然后像往常一样使用交叉验证选择最佳的blender。
刚刚训练了一个blender,和分类器一起构成了一个堆叠组合!现在在测试集中评估集合。对于测试集中的每一张图像,用所有的分类器进行预测,然后将预测输入到blender来得到集合的预测。与之前训练的投票分类器相比如何?
首先利用第一层的估计量和测试集得到一个新的预测
X_test_predictions = np.empty((len(X_test),len(estimators)),dtype = np.float32)
for index,estimator in enumerate(enumerators):
X_test_predictions[:,index] = estimator.predict(X_test)然后通过使用一个新的训练数据集(从以前的预演)和blender在第二层做出最终的预测
y_pred = rnd_forest_blender.predict(X_test_predictions)
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_pred)![]()
这种叠加集成不如之前训练的软投票分类器(0.9658),但它仍然胜过所有的单个分类器。