决定从这篇文章开始,开一个读源码系列,不限制平台语言或工具,任何自己感兴趣的都会写。前几天碰到一个小问题又读了一遍ConcurrentQueue的源码,那就拿C#中比较常用的并发队列ConcurrentQueue作为开篇来聊一聊它的实现原理。
话不多说,直奔主题。
要提前说明下的是,本文解析的源码是基于.NET Framework 4.8版本,地址是:https://referencesource.microsoft.com/#mscorlib/system/Collections/Concurrent/ConcurrentQueue.cs
本来是打算用.NET Core版本的,但是找了一下竟然没找到:https://github.com/dotnet/runtime/tree/master/src/libraries/System.Collections.Concurrent/src/System/Collections/Concurrent
不知道是我找错位置了还是咋回事,有知道的大佬告知一下。不过我觉得实现原理应该类似吧,后面找到了我对比一下,不同的话再写一篇来分析。
带着问题出发
如果是自己实现一个简单的队列功能,我们该如何设计它的存储结构呢?一般来说有这两种方式:数组或者链表,先来简单分析下。
我们都知道,数组是固定空间的集合,意味着初始化的时候要指定数组大小,但是队列的长度是随时变化的,超出数组大小了怎么办?这时候就必须要对数组进行扩容。问题又来了,扩容要扩多少呢,少了不够用多了浪费内存空间。与之相反的,链表是动态空间类型的数据结构,元素之间通过指针相连,不需要提前分配空间,需要多少分配多少。但随之而来的问题是,大量的出队入队操作伴随着大量对象的创建销毁,GC的压力又变得非常大。
事实上,在C#的普通队列Queue类型中选择使用数组进行实现,它实现了一套扩容机制,这里不再详细描述,有兴趣的直接看源码,比较简单。
回到主题,要实现一个高性能的线程安全队列,我们试着回答以下问题:
- 存储结构是怎样的
- 如何初始化(初始容量给多少比较好?)
- 常用操作(入队出队)如何实现
- 线程安全是如何保证的
存储结构
通过源码可以看到ConcurrentQueue采用了数组+链表的组合模式,充分吸收了2种结构的优点。
具体来说,它的总体结构是一个链表,链表的每个节点是一个包含数组的特殊对象,我们称之为Segment(段或节,原话是a queue is a linked list of small arrays, each node is called a segment.),它里面的数组是存储真实数据的地方,容量固定大小是32,每一个Segment有指向下一个Segment的的指针,以此形成链表结构。而队列中维护了2个特殊的指针,他们分别指向队列的首段(head segment)和尾段(tail segment),他们对入队和出队有着重要的作用。用一张图来解释队列的内部结构:
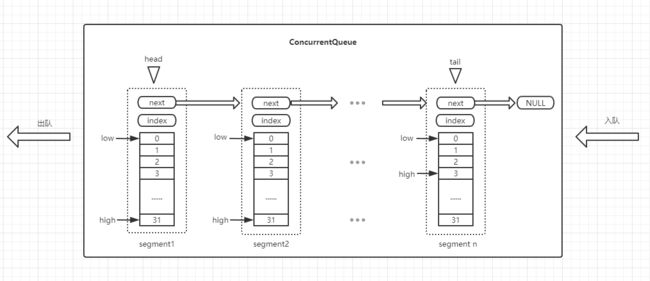
嗯,画图画到这里突然联想到,搞成双向链表的话是不是就神似B+树的叶子节点?技术就是这么奇妙~
段的核心定义为:
///
/// private class for ConcurrentQueue.
/// 链表节点(段)
///
private class Segment
{
//实际存储数据的容器
internal volatile T[] m_array;
//存储对应位置数据的状态,当数据的对应状态位标记为true时该数据才是有效的
internal volatile VolatileBool[] m_state;
//下一段的指针
private volatile Segment m_next;
//当前段在队列中的索引
internal readonly long m_index;
//两个位置指针
private volatile int m_low;
private volatile int m_high;
//所属的队列实例
private volatile ConcurrentQueue m_source;
}
队列的核心定义为:
///
/// 线程安全的先进先出集合,
///
public class ConcurrentQueue : IProducerConsumerCollection, IReadOnlyCollection
{
//首段
[NonSerialized]
private volatile Segment m_head;
//尾段
[NonSerialized]
private volatile Segment m_tail;
//每一段的大小
private const int SEGMENT_SIZE = 32;
//截取快照的操作数量
[NonSerialized]
internal volatile int m_numSnapshotTakers = 0;
}
常规操作
先从初始化一个队列开始看起。
创建队列实例
与普通Queue不同的是,ConcurrentQueue不再支持初始化时指定队列大小(capacity),仅仅提供一个无参构造函数和一个IEnumerable参数的构造函数。
///
/// Initializes a new instance of the
public ConcurrentQueue()
{
m_head = m_tail = new Segment(0, this);
}
无参构造函数很简单,创建了一个Segment实例并把首尾指针都指向它,此时队列只包含一个Segment,它的索引是0,队列容量是32。
继续看一下Segment是如何被初始化的:
///
/// Create and initialize a segment with the specified index.
///
internal Segment(long index, ConcurrentQueue source)
{
m_array = new T[SEGMENT_SIZE];
m_state = new VolatileBool[SEGMENT_SIZE]; //all initialized to false
m_high = -1;
Contract.Assert(index >= 0);
m_index = index;
m_source = source;
}
Segment只提供了一个构造函数,接受的参数分别是队列索引和队列实例,它创建了一个长度为32的数组,并创建了与之对应的状态数组,然后初始化了位置指针(m_low=0,m_high=-1,此时表示一个空的Segment)。
到这里,一个并发队列就创建好了。
使用集合创建队列的过程和上面类似,只是多了两个步骤:入队和扩容,下面会重点描述这两部分所以这里不再过多介绍。
元素入队
先亮出源码:
///
/// Adds an object to the end of the
/// The object to add to the end of the 通过源码可以看到,入队操作是在队尾(m_tail)进行的,它尝试在最后一个Segment中追加指定的元素,如果成功了就直接返回,失败的话就自旋等待,直到成功为止。那什么情况下会失败呢?这就要继续看看是如何追加元素的:
internal bool TryAppend(T value)
{
//先判断一下高位指针有没有达到数组边界(也就是数组是否装满了)
if (m_high >= SEGMENT_SIZE - 1)
{
return false;
}
int newhigh = SEGMENT_SIZE;
try
{ }
finally
{
//使用原子操作让高位指针加1
newhigh = Interlocked.Increment(ref m_high);
//如果数组还有空位
if (newhigh <= SEGMENT_SIZE - 1)
{
//把数据放到数组中,同时更新状态
m_array[newhigh] = value;
m_state[newhigh].m_value = true;
}
//数组满了要触发扩容
if (newhigh == SEGMENT_SIZE - 1)
{
Grow();
}
}
return newhigh <= SEGMENT_SIZE - 1;
}
所以,只有当尾段m_tail装满的情况下追加元素才会失败,这时候必须要等待下一个段产生,也就是扩容(细细品一下Grow这个词真的很妙),自旋就是在等扩容完成才能有地方放数据。而在保存数据的时候,通过原子自增操作保证了同一个位置只会有一个数据被写入,从而实现了线程安全。
注意:这里的装满并不是指数组每个位置都有数据,而是指最后一个位置已被使用。
继续看一下扩容是怎么一个过程:
///
/// Create a new segment and append to the current one
/// Update the m_tail pointer
/// This method is called when there is no contention
///
internal void Grow()
{
//no CAS is needed, since there is no contention (other threads are blocked, busy waiting)
Segment newSegment = new Segment(m_index + 1, m_source); //m_index is Int64, we don't need to worry about overflow
m_next = newSegment;
Contract.Assert(m_source.m_tail == this);
m_source.m_tail = m_next;
}
在普通队列中,扩容是通过创建一个更大的数组然后把数据拷贝过去实现扩容的,这个操作比较耗时。而在并发队列中就非常简单了,首先创建一个新Segment,然后把当前Segment的next指向它,最后挂到队列的末尾去就可以了,全部是指针操作非常高效。而且从代码注释中可以看到,这里不会出现线程竞争的情况,因为其他线程都因为位置不够被阻塞都在自旋等待中。
元素出队
还是先亮出源码:
public bool TryDequeue(out T result)
{
while (!IsEmpty)
{
Segment head = m_head;
if (head.TryRemove(out result))
return true;
//since method IsEmpty spins, we don't need to spin in the while loop
}
result = default(T);
return false;
}
可以看到只有在队列不为空(IsEmpty==false)的情况下才会尝试出队操作,而出队是在首段上进行操作的。关于如何判断队列是否为空总结就一句话:当首段m_head不包含任何数据且没有下一段的时候队列才为空,详细的判断过程源码注释中写的很清楚,限于篇幅不详细介绍。
出队的本质是从首段中移除低位指针所指向的元素,看一下具体实现步骤:
internal bool TryRemove(out T result)
{
SpinWait spin = new SpinWait();
int lowLocal = Low, highLocal = High;
//判断当前段是否为空
while (lowLocal <= highLocal)
{
//判断低位指针位置是否可以移除
if (Interlocked.CompareExchange(ref m_low, lowLocal + 1, lowLocal) == lowLocal)
{
SpinWait spinLocal = new SpinWait();
//判断元素是否有效
while (!m_state[lowLocal].m_value)
{
spinLocal.SpinOnce();
}
//取出元素
result = m_array[lowLocal];
//释放引用关系
if (m_source.m_numSnapshotTakers <= 0)
{
m_array[lowLocal] = default(T);
}
//判断当前段的元素是否全部被移除了,要丢弃它
if (lowLocal + 1 >= SEGMENT_SIZE)
{
spinLocal = new SpinWait();
while (m_next == null)
{
spinLocal.SpinOnce();
}
Contract.Assert(m_source.m_head == this);
m_source.m_head = m_next;
}
return true;
}
else
{
//线程竞争失败,自旋等待并重置
spin.SpinOnce();
lowLocal = Low; highLocal = High;
}
}//end of while
result = default(T);
return false;
}
首先,只有当前Segment不为空的情况下才尝试移除元素,否则就直接返回false。然后通过一个原子操作Interlocked.CompareExchange判断当前低位指针上是否有其他线程同时也在移除,如果有那就进入自旋等待,没有的话就从这个位置取出元素并把低位指针往前推进一位。如果当前队列没有正在进行截取快照的操作,那取出元素后还要把这个位置给释放掉。当这个Segment的所有元素都被移除掉了,这时候要把它丢弃,简单来说就是让队列的首段指针指向它的下一段即可,丢弃的这一段等着GC来收拾它。
这里稍微提一下Interlocked.CompareExchange,它的意思是比较和交换,也就是更为大家所熟悉的CAS(Compare-and-Swap),它主要做了以下2件事情:
- 比较m_low和lowLocal的值是否相等
- 如果相等则m_low=lowLocal+1,如果不相等就什么都不做,不管是否相等,始终返回m_low的原始值
整个操作是原子性的,对CPU而言就是一条指令,这样就可以保证当前位置只有一个线程执行出队操作。
还有一个
TryPeek()方法和出队类似,它是从队首获取一个元素但是无需移除该元素,可以看做Dequeue的简化版,不再详细介绍。
获取队列中元素的数量
与普通Queue不同的是,ConcurrentQueue并没有维护一个表示队列中元素个数的计数器,那就意味着要得到这个数量必须实时去计算。我们看一下计算过程:
public int Count
{
get
{
Segment head, tail;
int headLow, tailHigh;
GetHeadTailPositions(out head, out tail, out headLow, out tailHigh);
if (head == tail)
{
return tailHigh - headLow + 1;
}
int count = SEGMENT_SIZE - headLow;
count += SEGMENT_SIZE * ((int)(tail.m_index - head.m_index - 1));
count += tailHigh + 1;
return count;
}
}
大致思路是,先计算(GetHeadTailPositions)出首段的低位指针和尾段的高位指针,这中间的总长度就是我们要的数量,然后分成3节依次累加每一个Segment包含的元素个数得到最终的队列长度,可以看到这是一个开销比较大的操作。
正因为如此,微软官方推荐使用IsEmpty属性来判断队列是否为空,而不是使用队列长度Count==0来判断,使用ConcurrentStack也是一样。
截取快照(take snapshot)
所谓的take snapshot就是指一些格式转换的操作,例如ToArray()、ToList()、GetEnumerator()这种类型的方法。在前面队列的核心定义中我们提到有一个m_numSnapshotTakers字段,这时候就派上用场了。下面以比较典型的ToList()源码举例说明:
private List ToList()
{
// Increments the number of active snapshot takers. This increment must happen before the snapshot is
// taken. At the same time, Decrement must happen after list copying is over. Only in this way, can it
// eliminate race condition when Segment.TryRemove() checks whether m_numSnapshotTakers == 0.
Interlocked.Increment(ref m_numSnapshotTakers);
List list = new List();
try
{
Segment head, tail;
int headLow, tailHigh;
GetHeadTailPositions(out head, out tail, out headLow, out tailHigh);
if (head == tail)
{
head.AddToList(list, headLow, tailHigh);
}
else
{
head.AddToList(list, headLow, SEGMENT_SIZE - 1);
Segment curr = head.Next;
while (curr != tail)
{
curr.AddToList(list, 0, SEGMENT_SIZE - 1);
curr = curr.Next;
}
tail.AddToList(list, 0, tailHigh);
}
}
finally
{
// This Decrement must happen after copying is over.
Interlocked.Decrement(ref m_numSnapshotTakers);
}
return list;
}
可以看到,ToList的逻辑和Count非常相似,都是先计算出两个首尾位置指针,然后把队列分为3节依次遍历处理,最大的不同之处在于方法的开头和结尾分别对m_numSnapshotTakers做了一个原子操作。
在方法的第一行,使用Interlocked.Increment做了一次递增,这时候表示队列正在进行一次截取快照操作,在处理完后又在finally中用Interlocked.Decrement做了一次递减表示当前操作已完成,这样确保了在进行快照时不被出队影响。感觉这块很难描述的特别好,所以保留了原始的英文注释,大家慢慢体会。
到这里,基本把ConcurrentQueue的核心说清楚了。
总结一下
回到文章开头提出的几个问题,现在应该有了很清晰的答案:
- 存储结构 -- 采用数组和链表的组合形式
- 如何初始化 -- 创建固定大小的段,无需指定初始容量
- 常用操作如何实现 -- 尾段入队,首段出队
- 线程安全问题 -- 使用SpinWait自旋等待和原子操作实现
以上所述均是个人理解,如果有错误的地方还请不吝指正,以免误导他人。
推荐相关阅读,篇篇都是干货:https://www.cnblogs.com/lucifer1982/category/126755.html