一:系统调用简介
计算机系统的各种硬件资源是有限的,在现代多任务操作系统上同时运行的多个进程都需要访问这些资源,而有些资源是不允许直接操作的,所有对这些资源的访问都必须有操作系统控制。也就是说操作系统是使用这些资源的唯一入口,而这个入口就是操作系统提供的系统调用(System Call)。在linux中系统调用是用户空间访问内核的唯一手段,除异常和陷入外,他们是内核唯一的合法入口。
一般情况下应用程序通过应用编程接口API,而不是直接通过系统调用来编程。在Unix世界,最流行的API是基于POSIX标准的。
操作系统一般是通过中断从用户态切换到内核态。中断就是一个硬件或软件请求,要求CPU暂停当前的工作,去处理更重要的事情。比如,在x86机器上可以通过int指令进行软件中断,而在磁盘完成读写操作后会向CPU发起硬件中断。
中断有两个重要的属性,中断号和中断处理程序。中断号用来标识不同的中断,不同的中断具有不同的中断处理程序。在操作系统内核中维护着一个中断向量表(Interrupt Vector Table),这个数组存储了所有中断处理程序的地址,而中断号就是相应中断在中断向量表中的偏移量。
一般地,系统调用都是通过软件中断实现的,x86系统上的软件中断由int $0x80指令产生,而128号异常处理程序就是系统调用处理程序system_call(),它与硬件体系有关,在entry.S中用汇编写。
下面是64位系统调用的过程:
sysdep.h
// glibc源码
/* The Linux/x86-64 kernel expects the system call parameters in
registers according to the following table:
syscall number rax
arg 1 rdi
arg 2 rsi
arg 3 rdx
arg 4 r10
arg 5 r8
arg 6 r9
*/
#define DO_CALL(syscall_name, args) \
lea SYS_ify (syscall_name), %rax; \
syscall
- 与32位的系统调用类似,首先将系统调用名称转换为系统调用号,放在寄存器
%rax - 在这里是进行真正调用,而不是采用中断模式,改用
syscall指令(传递参数的寄存器也改变了)
syscall
- syscall指令使用了一种特殊的寄存器,称为特殊模块寄存器(Model Specific Registers,MSR)
- MSR是CPU为了完成某些特殊控制功能为目的的寄存器,例如系统调用
- 在Linux系统初始化时,trap_init除了初始化上面的中断模式外,还会调用cpu_init(),而cpu_init()会调用syscall_init()
syscall_init()
// Linux源码
void syscall_init(void)
{
wrmsrl(MSR_LSTAR, (unsigned long)entry_SYSCALL_64);
}
- rdmsr和wrmsr是用来读写特殊模块寄存器的,MSR_LSTAR就是一个特殊模块寄存器
- 当syscall指令调用的时候,会从MSR_LSTAR寄存器里取出函数地址来调用,即调用entry_SYSCALL_64
entry_SYSCALL_64
// Linux源码
__visible void do_syscall_64(unsigned long nr, struct pt_regs *regs)
{
struct thread_info *ti;
...
ti = current_thread_info();
if (READ_ONCE(ti->flags) & _TIF_WORK_SYSCALL_ENTRY)
nr = syscall_trace_enter(regs);
...
nr &= __SYSCALL_MASK;
if (likely(nr < NR_syscalls)) {
nr = array_index_nospec(nr, NR_syscalls);
regs->ax = sys_call_table[nr](regs);
}
syscall_return_slowpath(regs);
}
- 从寄存器
%rax里面取出系统调用号,然后根据系统调用号,在系统调用表sys_call_table中找到相应的函数进行调用 - 并将寄存器中保存的参数取出来,作为函数参数
USERGS_SYSRET64
// Linux源码 #define USERGS_SYSRET64 \ swapgs; \ sysretq;
返回用户态的指令变成了sysretq
总结:
二:fork系统调用过程
fork()函数可以建立一个新进程,把当前的进程分为父进程和子进程,新进程称为子进程,而原进程称为父进程。fork调用一次,返回两次,这两个返回分别带回它们各自的返回值,其中在父进程中的返回值是子进程的PID,而子进程中的返回值则返回 0。因此,可以通过返回值来判定该进程是父进程还是子进程。还有一个很奇妙的是:fork函数将运行着的程序分成2个(几乎)完全一样的进程,每个进程都启动一个从代码的同一位置开始执行的线程。这两个进程中的线程继续执行,就像是两个用户同时启动了该应用程序的两个副本。
新创建的子进程几乎但是不完全与父进程相同。子进程得到与父进程用户级虚拟地址空间相同(但是独立)的一份拷贝,包括文本,数据和bss段、堆以及用户栈。子进程还获得与父进程任何打开文件描述符相同的拷贝。这就是意味着当父进程调用fork时候,子进程还可以读写父进程中打开的任何文件。父进程和新创建的子进程之间最大区别在于他们有着不同的PID。
UNIX将复制父进程的地址空间内容给子进程,因此,子进程有了独立的地址空间。在不同的UNIX (Like)系统下,我们无法确定fork之后是子进程先运行还是父进程先运行,这依赖于系统的实现。
我们来看一段CSAPP里面的程序:
int main()
{
pid_t pid;
int x = 1;
pid = fork();
if(pid == 0)
{
printf("child : x=%d\n", ++x);
exit(0);
}
printf("parent: x=%d\n",--x);
exit(0);
}
在unix系统下面会输出:
parent:x=0
child:x=2
对于上面的子进程来说,由于if里面有exit,所以输出2之后,子进程就结束了,若没有exit,子进程会接着输出后面的x=1.
可以通过图来表示上面程序的运行过程:

一个更加复杂的例子如下:
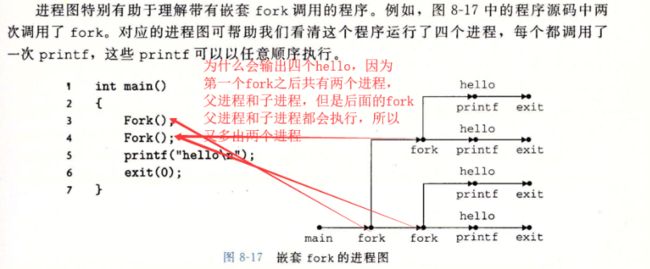
在这里有一些值得探讨的问题。当在用户态调用fork()函数的时候,系统的内核是如何执行这个函数的,子进程在内核是从哪里执行的?他的堆栈有哪些变化呢?当然说道进程,那么进程控制块PCB我们肯定是要了解的。进程控制块PCB是干什么用的呢?为了描述和控制进程的运行,系统为每一个进程定义了一个数据结构——进程控制块。它是进程实体的一部分,是操作系统中最重要的记录型数据结构。或者说,OS是根据PCB来对并发程序的进程进行控制和管理的。总而言之,PCB是进程存在的唯一标志。进程控制块中的信息包括进程标识符、处理机状态、进程调度信息、进程控制信息。然而PCB在linux中具体实现是 task_struct数据结构,由于这个数据结构是相当庞大的,我们给出把一个链接(task_struct数据结构),可以到该链接下去看看。
Linux下用于创建进程的API有三个fork,vfork和clone,这三个函数分别是通过系统调用sys_fork,sys_vfork以及sys_clone实现的
(这里目前讨论的都是基于x86架构的)。而且这三个系统调用,都是通过do_fork来实现的,只是传入了不同的参数。所以我们可以得出结论:所有的子进程是在do_fork实现创建和调用的。下面我们就来整理一下整个进程的在用户态到内核态的过程是怎么样的。fork系统调用如下:

do_fork的代码如下:
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
do_fork()的实现,主要是靠copy_process()完成的,这就是一环套一环。整个过程实现如下:
1:p = dup_task_struct(current); 为新进程创建一个内核栈、thread_iofo和task_struct,这里完全copy父进程的内容,所以到目前为止,父进程和子进程是没有任何区别的。
2:为新进程在其内存上建立内核堆栈
3:对子进程task_struct任务结构体中部分变量进行初始化设置,检查所有的进程数目是否已经超出了系统规定的最大进程数,如果没有的话,那么就开始设置进程描诉符中的初始值,从这开始,父进程和子进程就开始区别开了。
4:把父进程的有关信息复制给子进程,建立共享关系
5:设置子进程的状态为不可被TASK_UNINTERRUPTIBLE,从而保证这个进程现在不能被投入运行,因为还有很多的标志位、数据等没有被设置
6:复制标志位(falgs成员)以及权限位(PE_SUPERPRIV)和其他的一些标志
7:调用get_pid()给子进程获取一个有效的并且是唯一的进程标识符PID
8:return ret_from_fork;返回一个指向子进程的指针,开始执行
三:execve系统调用过程
execve() 系统调用的作用是运行另外一个指定的程序。它会把新程序加载到当前进程的内存空间内,当前的进程会被丢弃,它的堆、栈和所有的段数据都会被新进程相应的部分代替,然后会从新程序的初始化代码和 main 函数开始运行。同时,进程的 ID 将保持不变。
execve() 系统调用通常与 fork() 系统调用配合使用。从一个进程中启动另一个程序时,通常是先 fork() 一个子进程,然后在子进程中使用 execve() 变身为运行指定程序的进程。 例如,当用户在 Shell 下输入一条命令启动指定程序时,Shell 就是先 fork() 了自身进程,然后在子进程中使用 execve() 来运行指定的程序。
execve() 系统调用的函数原型为:
int execve(const char *filename, char *const argv[],
char *const envp[]);
int execl(const char *path, const char *arg, ...
/* (char *) NULL */);
int execlp(const char *file, const char *arg, ...
/* (char *) NULL */);
int execle(const char *path, const char *arg, ...
/*, (char *) NULL, char * const envp[] */);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[],
char *const envp[]);
这 7 个函数中只有execve()是真正的系统调用函数,其它几个最终都会调用它。
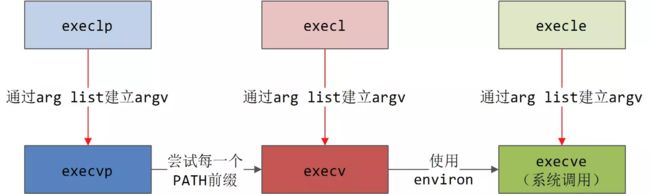
exec 后面的字母的含义为:
filename 用于指定要运行的程序的文件名,argv 和 envp 分别指定程序的运行参数和环境变量。除此之外,该系列函数还有很多变体,它们执行大体相同的功能,区别在于需要的参数不同,包括 execl、execlp、execle、execv、execvp、execvpe 等。它们的参数意义和使用方法请读者自行查看帮助手册。
需要注意的是,exec 系列函数的返回值只在遇到错误的时候才有意义。如果新程序成功地被执行,那么当前进程的所有数据就都被新进程替换掉了,所以永远也不会有任何返回值。
对于已打开文件的处理,在 exec() 系列函数执行之前,应该确保全部关闭。因为 exec() 调用之后,当前进程就完全变身成另外一个进程了,老进程的所有数据都不存在了。如果 exec() 调用失败,当前打开的文件状态应该被保留下来。让应用层处理这种情况会非常棘手,而且有些文件可能是在某个库函数内部打开的,应用对此并不知情,更谈不上正确地维护它们的状态了。
所以,对于执行 exec() 函数的应用,应该总是使用内核为文件提供的执行时关闭标志(FD_CLOEXEC)。设置了该标志之后,如果 exec() 执行成功,文件就会被自动关闭;如果 exec() 执行失败,那么文件会继续保持打开状态。使用系统调用 fcntl() 可以设置该标志。
下面是fork和execve结合起来的一个例子:
/* execve.c */ #include#include #include #include int main(int argc, char *argv[], char *envp[]) { char *const pg_argv[] = {"./argv", "-dummy-param", NULL}; char *pg_envp[] = {"some_key_val_pair", NULL}; printf("0 -----------------------------\n"); if (fork()) { wait(0); } else { if (execve("./argv", pg_argv, envp) == -1) perror("execve error: "); } printf("1 -----------------------------\n"); if (fork()) { wait(0); } else { if (execve("./argv", pg_argv, pg_envp) == -1) perror("execve error: "); } return 0; }
execve()执行成功是不会返回的,只有在失败的时候会返回-1,并设置相应的errno。执行结果为:
$ clang argv.c -o argv $ clang execve.c -o execve $ ./execve pid of parent: 11900 0 ----------------------------- pid: 11901 argv argv[0]: ./argv argv[1]: -dummy-param envp(0~4) envp[0]: XAUTHORITY=/tmp/xauth-1000-_0 envp[1]: LC_PAPER=en_US.UTF-8 envp[2]: QT_ACCESSIBILITY=1 envp[3]: LC_MEASUREMENT=en_US.UTF-8 envp[4]: PAM_KWALLET_LOGIN=/tmp/kwallet_qi.socket environ(0~4) environ[0]: XAUTHORITY=/tmp/xauth-1000-_0 environ[1]: LC_PAPER=en_US.UTF-8 environ[2]: QT_ACCESSIBILITY=1 environ[3]: LC_MEASUREMENT=en_US.UTF-8 environ[4]: PAM_KWALLET_LOGIN=/tmp/kwallet_qi.socket 1 ----------------------------- pid: 11902 argv argv[0]: ./argv argv[1]: -dummy-param envp(0~4) envp[0]: some_key_val_pair environ(0~4) environ[0]: some_key_val_pair