1. 简介
Apache Zeppelin 是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等等。当前Hive与SparkSQL已经支持查询Hudi的读优化视图和实时视图。所以理论上Zeppelin的notebook也应当拥有这样的查询能力。
2.实现效果
2.1 Hive
2.1.1 读优化视图

2.1.2 实时视图

2.2 Spark SQL
2.2.1 读优化视图
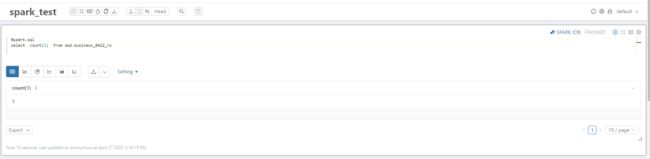
2.2.2 实时视图

3.常见问题整理
3.1 Hudi包适配
cp hudi-hadoop-mr-bundle-0.5.2-SNAPSHOT.jar zeppelin/lib
cp hudi-hive-bundle-0.5.2-SNAPSHOT.jar zeppelin/lib
cp hudi-spark-bundle_2.11-0.5.2-SNAPSHOT.jar zeppelin/lib
Zeppelin启动时会默认加载lib下的包,对于Hudi这类外部依赖,适合直接放在zeppelin/lib下以避免 Hive或Spark SQL在集群上找不到对应Hudi依赖。
3. 2 parquet jar包适配
Hudi包的parquet版本为1.10,当前CDH集群parquet版本为1.9,所以在执行Hudi表查询时,会报很多jar包冲突的错。
解决方法:在zepeelin所在节点的spark/jars目录下将parquet包升级成1.10。
副作用:zeppelin 以外的saprk job 分配到 parquet 1.10的集群节点的任务可能会失败。
建议:zeppelin 以外的客户端也会有jar包冲突的问题。所以建议将集群的spark jar 、parquet jar以及相关依赖的jar做全面升级,更好地适配Hudi的能力。
3.3 Spark Interpreter适配
相同sql在Zeppelin上使用Spark SQL查询会出现比hive查询记录条数多的现象。
问题原因:当向Hive metastore中读写Parquet表时,Spark SQL默认将使用Spark SQL自带的Parquet SerDe(SerDe:Serialize/Deserilize的简称,目的是用于序列化和反序列化),而不是用Hive的SerDe,因为Spark SQL自带的SerDe拥有更好的性能。
这样导致了Spark SQL只会查询Hudi的流水记录,而不是最终的合并结果。
解决方法:set spark.sql.hive.convertMetastoreParquet=false
方法一:直接在页面编辑属性
![]()
方法二:编辑 zeppelin/conf/interpreter.json添加
interpreter
"spark.sql.hive.convertMetastoreParquet": {
"name": "spark.sql.hive.convertMetastoreParquet",
"value": false,
"type": "checkbox"
},
4. Hudi增量视图
对于Hudi增量视图,目前只支持通过写Spark 代码的形式拉取。考虑到Zeppelin在notebook上有直接执行代码和shell 命令的能力,后面考虑封装这些notebook,以支持sql的方式查询Hudi增量视图。