相比于深度学习,传统的机器学习算法难道就此没落了吗,还有必要去学习吗?
自从 MIT Technology Review(麻省理工科技评论) 将 深度学习 列为 2013 年十大科技突破之首。加上今年 Google 的 AlphaGo 与 李世石九段 惊天动地的大战,AlphaGo 以绝对优势完胜李世石九段。人工智能、机器学习、深度学习、强化学习,成为了这几年计算机行业、互联网行业最火的技术名词。
其中,深度学习在图像处理、语音识别领域掀起了前所未有的一场革命。我本人是做图像处理相关的,以 2016 年计算机视觉三大会之一的 Conference on Computer Vision and Pattern Recognition(CVPR) 为例,在 Accept Papers 中,以 “Convolution” 关键词做搜索,就有 44 篇文章。以 “Deep” 为关键词搜索,有 96 篇文章:
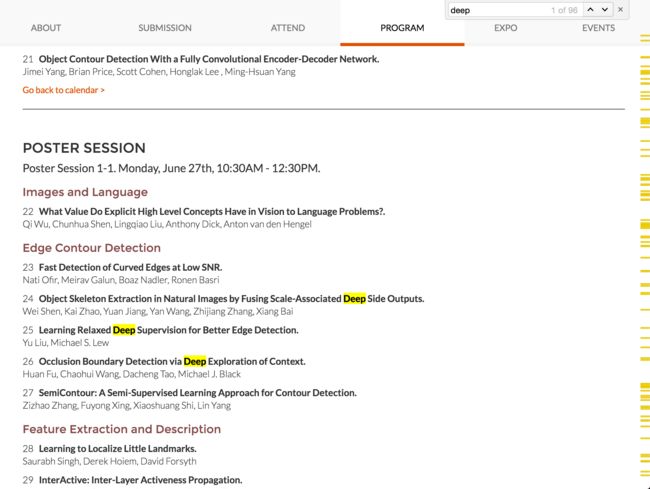
可以说,以 卷积神经网络(CNN)为代表的方法在图像处理领域已经取得了统治地位。同样的,以 递归神经网络(RNN) 在语音处理方面也大放异彩。
但是在深度学习独领风骚的同时,传统的机器学习算法,如 SVM 慢慢不像十多年前那么火热了,甚至受冷落了,如在上面 CVPR 2016 年 Accept Papers 页面中,搜索 “SVM”,仅仅有 4 篇文章:

所以,不禁很多人又这样的疑问,传统的机器学习算法难道就此没落了吗?还有必要去学习吗?
作为一个小硕,入门了这么长时间,我也想发表自己的看法:传统的机器学习算法不会没落,非常有必要去学。
从南大周志华老师的畅销书《机器学习》的目录来看:
第三章:线性模型
第四章:决策树
第五章:神经网络
第六章:支持向量机
第七章:贝叶斯分类器
第八章:集成学习
第九章:聚类
第十章:降维与度量学习
第十一章:特征选择与稀疏学习
第十二章:计算学习理论
第十三章:半监督学习
第十四章:概率图模型
第十五章:规则学习
第十六章:强化学习
深度学习属于神经网络那一章,只占机器学习领域很小的一块。
机器学习发展了二十多年来,已经渗透到很多领域,如 Robotics, Genome data, Financial markets。
而目前,深度学习占据统治地位的多数是在计算机视觉领域、自然语言处理领域。而且深度学习是 data driven 的,需要大量的数据,数据是其燃料,没了燃料,深度学习也巧妇难为无米之炊。如图像分类任务中,就需要大量的标注数据,因为有了 ImageNet 这样 百万量级,并带有标注 的数据,CNN 才能大显神威。
但是事实上,在实际的问题中,我们可能并不会有海量级别的、带有标注的数据。如暑假我在广州参加 CCF ADL70 机器学习研讨班的时候,碰到北京的一个药厂的学友,他们想用机器学习来预测药物对人的影响。但问题是,他们没有那么多的数据,仅仅就几十例,最多上百例的监督数据。据他们跟我介绍,他们就用的是 MCMC(Markov chain Monte Carlo) 的方法。
又比如说,我在研究我们老师的 正颌手术术后面型三维预测模拟及仿真分析 这个项目的时候,也是样本数量非常少,需要用这么少的数据来预测病人在做过正颌手术后面部的变形情况。
以上两种情况是非常常见的,这时候深度学习算法就无能为力,因为小数据下深度学习十分的容易 Overfitting。
通过上面的两个例子,我想说的是,在小数据集上,深度学习还取代不了诸如 非线性和线性核 SVM,贝叶斯分类器 方法。实际操作来看,SVM 只需要很小的数据就能找到数据之间分类的 超平面,得到很不错的分类结果。
所以,既然能用 Linear regression、Logistic regression 能解决的问题,那这时候还干嘛一定要用深度学习算法呢?况且,机器学习算法中,常常绕不开的 overfitting 问题,所以根据 奥卡姆剃刀原则:如无必要,勿增实体。这时候,能用简单的模型解决的问题,就不要用复杂的模型。
同样的,南大周志华老师也认为:即便是大数据,在无需另构特征的任务上也取代不了其他分类器。本质上,将它看作特征学习器比较合适。
所以,虽然深度学习发展如火如荼,但是其他机器学习算法并不会因此而没落。甚至我认为,结合深度学习,其他机器学习算法因此还可能获得新生。我了解的,清华大学的朱军老师 正在开发一个结合贝叶斯方法和深度学习方法的机器学习平台:ZhuSuan(珠算) Project,详情如下:

So,该做一个总结了。深度学习算法与传统的机器学习算法,各有利弊,大致如下:
深度学习是 data driven 的,需要大量的数据,而传统的机器学习算法通畅不需要;
深度学习本质上可以看作一个特征学习器,在无需另构特征情况下,传统的机器学习算法已经能够胜任日常的任务;
- 如无必要,勿增实体。能够简单的模型解决的,不必要上深度学习算法,杀鸡焉用牛刀?
以我非常认同 OpenAI 的 Tomasz Malisiewicz 大神说的一句话来结束吧:
Dont think about it as Machine Learning vs Deep Learning, just realize that each term emphasizes something a little bit different. But the search continues. Go ahead and explore. Break something.
We will continue building smarter software and our algorithms will continue to learn, but we have only begun to explore the kinds of architectures that can truly rule-them-all.