机器学习教程之10-聚类(Clustering)-K均值聚类(K-means)的sklearn实现
0.概述
优点:
原理简单
速度快
能够处理大量的数据
缺点:
需要指定聚类 数量K
对异常值敏感
对初始值敏感
1.无监督学习
在无监督学习中,数据不带任何标签。
能找出数据内在分类规则,并分成独立的点集(蔟),算法称为聚类算法。
2.K均值聚类(K-means)
K-均值是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组。
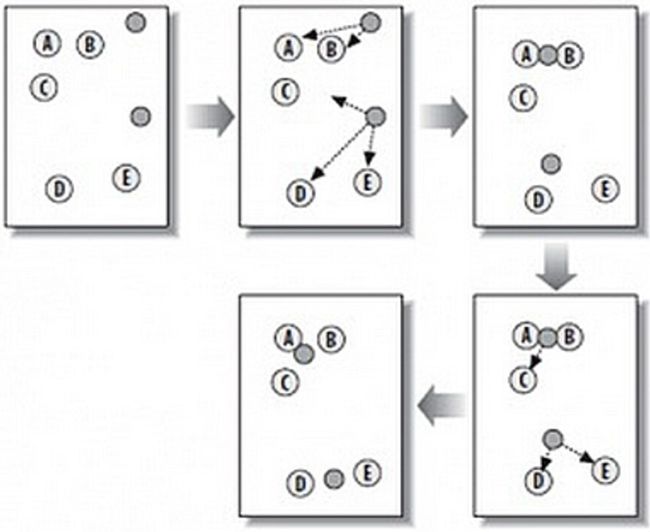
在下图中,可以看到,A,B,C,D,E是五个样本点,而灰色的点是随机点,也就是我们用来找点群的点。有两个种子点,所以K=2。
然后,K-Means的算法如下:
1)随机在图中取K(这里K=2)个种子点。
2)然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)
3)接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步)
4)然后重复第2)和第3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
3.随机初始化
在运行 K-均值算法的之前,我们首先要随机初始化所有的聚类中心点,下面介绍怎样做:
(1)我们应该选择 K
4.自问自答
根据K均值聚类算法,问自己几个问题:
1)处理不知道分多少类的数据,如何取K的值?
答:通常是需要根据不同的问题,人工进行选择的。选
择的时候思考我们运用 K-均值算法聚类的动机是什么,然后选择能最好服务于该目的标聚类数。
2)重心初始化什么位置更好?
答:随机选择K个实例的位置作为重心初始位置。
3)这个算法收不收敛,即通过有限次的运算,就能找到“点群”的中心?
答:2,3问题一起回答。最基本的方法是从样本点中随机选取k个点。给定足够的时间,K-means将总是收敛,但这可能是局部最小值。这很大程度上取决于重心的初始化。因此,通常会进行几次计算,重心的初始化不同。帮助解决这个问题的一种方法是k-means ++初始化方案,它已经在scikit-learn中使用(使用init=’kmeans++’参数)。这将初始化质心(通常)彼此远离,导致比随机初始化更好的结果。
4)如何计算重心?
答:除了随机初始化重心之外,后面跟新重心都是依据训练点的。具体计算重心的公式如下图。

5.代码
"""
功能:K均值聚类
说明:人为设置函数模型为2类
作者:唐天泽
博客:http://blog.csdn.net/u010837794/article/details/76596063
日期:2017-08-04
"""
"""
导入项目所需的包
"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.cluster import KMeans
# 使用交叉验证的方法,把数据集分为训练集合测试集
from sklearn.model_selection import train_test_split
# 加载数据集
def load_data():
iris = datasets.diabetes()
"""展示数据集的形状
diabetes.data.shape, diabetes.target.shape
"""
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.10, random_state=0)
return X_train, X_test, y_train, y_test
# 使用KMeans考察线性分类KMeans的预测能力
def test_KMeans(X_train,X_test,y_train,y_test):
# 选择模型,把数据交给模型训练
y_pred = KMeans(n_clusters=2, random_state=0).fit_predict(X_train)
"""绘图"""
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.scatter(X_train[:, 2], X_train[:, 3], c=y_pred)
ax.set_xlabel("data")
ax.set_ylabel("target")
ax.set_title("K-means")
ax.legend(framealpha=0.5)
plt.show()
return
if __name__=="__main__":
X_train,X_test,y_train,y_test=load_data() # 生成用于分类的数据集
test_KMeans(X_train,X_test,y_train,y_test) # 调用 test_KMeans6.参考资料
[1] k-means+python︱scikit-learn中的KMeans聚类实现
[2] 深入浅出K-Means算法
[1] 李航 《统计学习方法》
[2] 华校专《Python大战机器学习》