ECharts 实战:新冠病毒全国疫情地图可视化 (requests获取数据+ECharts展示)
ECharts实现新冠病毒全国疫情地图可视化效果
项目GitHub地址
-
效果1(分段映射)
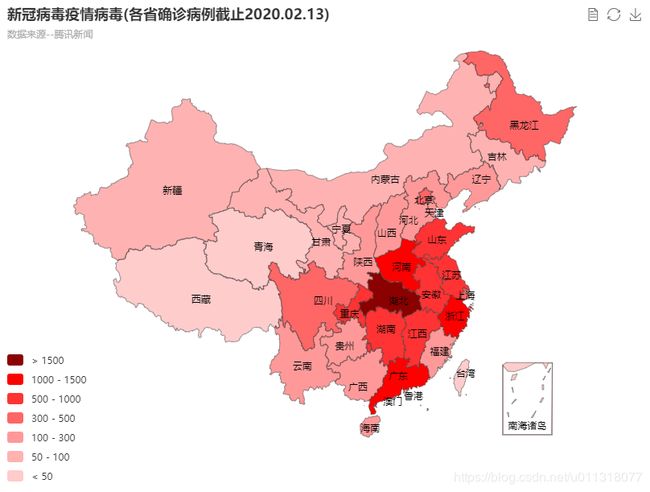
-
效果2(连续映射)
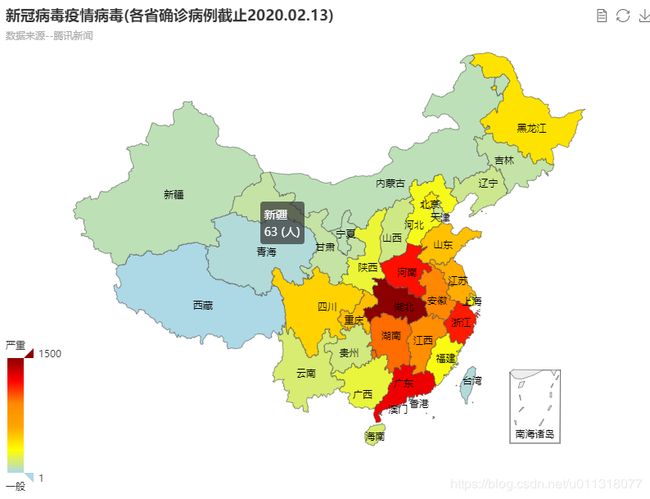
-
前几天使用basemap + matplotlib实现了新冠病毒全国疫情地图可视化,但是美观性不是太好
-
通过比较多个可视化工具,发现还是ECharts最适合中国地图可视化
-
ECharts有很好的交互性,鼠标放置地图上可以显示具体的人数,拖动滑条可以查看不同的范围
-
ECharts地图数据丰富,图表美化的很好,很多功能不用单独去设置,输出的图片已经是优化后的结果
-
虽然有pyecharts库,但是相对于原装的ECharts功能还是少一些,设置上也稍微麻烦一点
-
推荐直接使用ECharts,更新维护更加方便
1. 获取及提取数据
- 使用requests请求获取原始数据即可
# -*- coding:utf-8 -*-
# project_xxx\venv\Scripts python
'''
Author: Felix
WeiXin: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2020/1/30 20:33
Desc:
'''
import requests
import json
class nCovData():
def __init__(self):
# 获取原始全国疫情数据的网址
self.start_url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5'
def get_html_text(self):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0'}
res = requests.get(self.start_url, headers=headers, timeout=30)
res.encoding = 'utf-8'
# 将获取到的json格式的字符串类型数据转换为python支持的字典类型数据
data = json.loads(res.text)
# 所有的疫情数据,data['data']数据还是str的json格式需要转换为字典格式,包括:中国累积数据、各国数据(中国里面包含各省及地级市详细数据)、中国每日累积数据(1月13日开始)
all_data = json.loads(data['data'])
# print(all_data)
return all_data
if __name__ == '__main__':
ncovdata = nCovData()
ncovdata.get_html_text()
- 提取需要的数据
# -*- coding:utf-8 -*-
# project_xxx\venv\Scripts python
'''
Author: Felix
WeiXin: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2020/1/30 21:15
Desc:
'''
from nCov_data_analysis import a_get_html
import json
class ProvinceData():
def __init__(self):
# 获取所有的疫情数据,字典格式
self.ncovdata = a_get_html.nCovData()
self.all_data = self.ncovdata.get_html_text()
def province_total_data(self):
'''获取各省的累积数据'''
# areaTree对应的第一个数据就是中国,下面的children对应的就是每个省份的数据,是一个列表
areaTree = self.all_data['areaTree'][0]['children']
province_name = list()
province_total_confirm = list()
province_total_suspect = list()
province_total_dead = list()
province_total_heal = list()
for province in areaTree:
province_name.append(province['name'])
province_total_confirm.append(province['total']['confirm'])
province_total_suspect.append(province['total']['suspect'])
province_total_dead.append(province['total']['dead'])
province_total_heal.append(province['total']['heal'])
# 将省份名称和确诊人数对应打包为字典,用于ECharts地图可视化
province_total_confirm_dict = {'name': province_name, 'value': province_total_confirm}
print(province_total_confirm_dict)
with open('province_total.json', 'w', encoding='utf-8') as f:
json.dump(province_total_confirm_dict, f, ensure_ascii=False)
return province_name, province_total_confirm
def province_today_data(self):
'''获取各省今日数据'''
areaTree = self.all_data['areaTree'][0]['children']
province_name = list()
province_today_confirm = list()
province_today_suspect = list()
province_today_dead = list()
province_today_heal = list()
for province in areaTree:
province_name.append(province['name'])
province_today_confirm.append(province['today']['confirm'])
province_today_suspect.append(province['today']['suspect'])
province_today_dead.append(province['total']['dead'])
province_today_heal.append(province['total']['heal'])
# print(province_today_confirm)
def main(self):
self.province_total_data()
self.province_today_data()
if __name__ == '__main__':
province_data= ProvinceData()
province_data.main()
- 数据的获取具体分析及步骤请参考我的另外一篇博文
Python 实现 2019 新型冠状病毒疫情地图可视化 (basemap + matplotlib)
- 最终获取的JSON数据内容,用于ECharts作图:
{"name": ["湖北", "广东", "河南", "浙江", "湖南", "安徽", "江西", "江苏", "重庆", "山东", "四川", "黑龙江", "北京", "上海", "福建", "河北", "陕西", "广西", "海南", "云南", "贵州", "山西", "辽宁", "天津", "甘肃", "吉林", "宁夏", "新疆", "内蒙古", "香港", "台湾", "青海", "澳门", "西藏"],
"value": [48206, 1241, 1169, 1145, 968, 910, 872, 570, 518, 506, 451, 395, 366, 315, 279, 265, 229, 222, 157, 155, 135, 126, 116, 113, 87, 84, 64, 63, 61, 50, 18, 18, 10, 1]}
2. ECharts地图可视化
- 使用map进行可视化
Title