Spark RDD系列----3. rdd.coalesce方法的作用
当spark程序中,存在过多的小任务的时候,可以通过 RDD.coalesce方法,收缩合并分区,减少分区的个数,减小任务调度成本,避免Shuffle导致,比RDD.repartition效率提高不少。
rdd.coalesce方法的作用是创建CoalescedRDD,源码如下:
def coalesce(numPartitions: Int, shuffle: Boolean = false)(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {
if (shuffle) {
/** Distributes elements evenly across output partitions, starting from a random partition. */
val distributePartition = (index: Int, items: Iterator[T]) => {
var position = (new Random(index)).nextInt(numPartitions)
items.map { t =>
// Note that the hash code of the key will just be the key itself. The HashPartitioner
// will mod it with the number of total partitions.
position = position + 1
(position, t)
}
} : Iterator[(Int, T)]
// include a shuffle step so that our upstream tasks are still distributed
new CoalescedRDD(
new ShuffledRDD[Int, T, T](mapPartitionsWithIndex(distributePartition),
new HashPartitioner(numPartitions)),
numPartitions).values
} else {
new CoalescedRDD(this, numPartitions)
}
}DAGScheduler进行任务分配的时候,需要调用CoalescedRDD.getPartitions方法,获取CoalescedRDD的分区信息。这个方法的代码如下:
override def getPartitions: Array[Partition] = {
val pc = new PartitionCoalescer(maxPartitions, prev, balanceSlack)
pc.run().zipWithIndex.map {
case (pg, i) =>
val ids = pg.arr.map(_.index).toArray//ids表示CoalescedRDD的某个分区,对应它的parent RDD的所有分区id
new CoalescedRDDPartition(i, prev, ids, pg.prefLoc)
}
}1.保证CoalescedRDD的每个分区基本上对应于它Parent RDD分区的个数相同
2.CoalescedRDD的每个分区,尽量跟它的Parent RDD的本地性形同。比如说CoalescedRDD的分区1对应于它的Parent RDD的1到10这10个分区,但是1到7这7个分区在节点1.1.1.1上,那么 CoalescedRDD的分区1所要执行的节点就是1.1.1.1。这么做的目的是为了减少节点间的数据通信,提升处理能力。
3.CoalescedRDD的分区尽量分配到不同的节点执行
4.Be efficient, i.e. O(n) algorithm for n parent partitions (problem is likely NP-hard)(不知道该怎么翻译,只能粘原文了)
CoalescedRDD分区它数据结构表示,它是一个容器,包含了一个的Parent RDD的所有分区。在上面的代码中,创建CoalescedRDDPartition对象的时候,ids参数是一个数组,表示这个CoalescedRDDPartition对应的parent RDD的所有分区id。
CoalescedRDD.compute方法用于生成CoalescedRDD一个分区的数据,源码如下:
override def compute(partition: Partition, context: TaskContext): Iterator[T] = {
partition.asInstanceOf[CoalescedRDDPartition].parents.iterator.flatMap { parentPartition =>
firstParent[T].iterator(parentPartition, context)
}
}可见这个方法的作用是将CoalescedRDD一个分区对应它的parent RDD的所有分区数据拼接起来,成为一个新的Iterator。效果如下图表示:
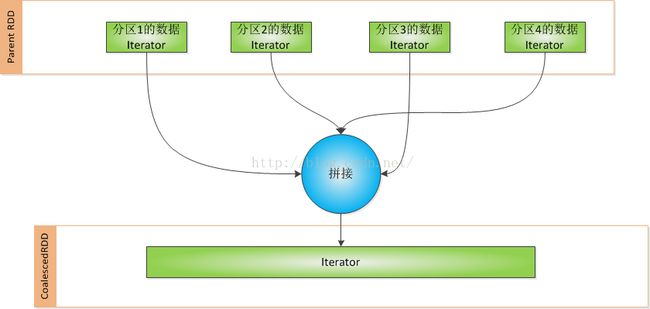
如果CoalescedRDD的一个分区跟它的Parent RDD的分区没有在一个Executor,则需要通过Netty通信的方式,拿到它的Parent RDD的数据,然后再拼接。
采用rdd.coalesce方法修改了分区的个数,虽然由可能需要采用Netty通信的方式获取它的Parent RDD的数据,但是没有落地到磁盘的操作,避免了磁盘I/O,所以比Shuffle还是要快不少。