基于OpenCV与 ImageAI 的动漫人物识别
在从二次元毕业之前,我们经常都会看到"这个人物是谁?哪个番的?"之类的问题,在学习图像识别的过程中,实现了一个动漫人物的识别的例子,直接使用现有的两个成熟的工具OpenCV与 ImageAI通过人物头像来进行动漫人物的识别,作为一个入门的例子。而在实际情况下,动漫人物时有撞脸的情况发生,这个时候还需要通过服饰,甚至结合知识图谱关联图像中出现的其他角色来进行更加精确的识别。下面直接上demo:
一、获取图像中的人物头像:

这里首先使用fate的一张图像作为例子,代码如下:
1、引入必要的库:
import cv2
import sys
import os.path2、使用opencv进行动漫人物头像的提取,这里采用某宅界前辈提供的lbpcascade_animeface.xml:
cascade = cv2.CascadeClassifier('../lbpcascade_animeface.xml') #引入xml
image = cv2.imread('timg8.jpg', cv2.IMREAD_COLOR) #读入一幅彩色图片
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) #色彩空间转换
gray = cv2.equalizeHist(gray)#图像直方图均衡化
faces = cascade.detectMultiScale(gray,
# detector options
scaleFactor = 1.1,
minNeighbors = 5,
minSize = (24, 24))3、展示人物头像提取的结果,并把提取的头像切割下来保存在faces文件中,为后续的识别做准备:
i = 0
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
face = image[y: y+h, x:x+w, :]
face = cv2.resize(face,(96,96))
save_filename = '%s_%d.png' % (os.path.basename(filename).split('.')[0],i)
cv2.imwrite("faces/"+save_filename,face)
i = i + 1
cv2.imshow("AnimeFaceDetect", image)
cv2.waitKey(0)
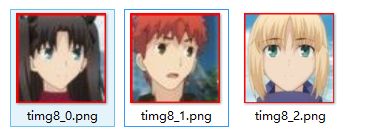
cv2.imwrite("out2.png", image)头像识别的结果:

faces文件中保持的头像:
二、使用ImageAI 进行模型的训练,由于本机性能有限,这里只做实例,对四个人物进行训练,每个人物训练集15张,测试集5张(实际使用中请使用高性能的机器进行,图像的数量也建议在400-600张左右,图像质量较好):
1、准备训练集和测试集,这里对四个角色进行训练:
2、训练代码如下:
from imageai.Prediction.Custom import ModelTraining
model_trainer = ModelTraining()
model_trainer.setModelTypeAsResNet()
model_trainer.setDataDirectory("pg") #训练的目录
model_trainer.trainModel(num_objects=4, num_experiments=50, enhance_data=True, batch_size=5, show_network_summary=True)使用imageai工具,代码非常精简。通过ResNet模型进行训练,训练对象为4个,训练50次,每批次训练5张,生成副本并在控制台打印训练过程。
3、训练结果:

训练结果包括json和models。其中json表面了对象对象的索引值。models中是每次训练的结果,其中ex-后面的是训练的次数,0.450000是此次训练在测试集上的精准度,可以看到训练20次精准度是0.45(最大是1).
4、通过训练的结果在识别提取的头像:
from imageai.Prediction.Custom import CustomImagePrediction
import os
execution_path = os.getcwd()
prediction = CustomImagePrediction()
prediction.setModelTypeAsResNet() #设置ResNet模型
prediction.setModelPath(os.path.join(execution_path, "pg/models/model_ex-040_acc-0.800000.h5"))
prediction.setJsonPath(os.path.join(execution_path, "pg/json/model_class.json"))
prediction.loadModel(num_objects=4)
predictions, probabilities = prediction.predictImage(os.path.join(execution_path, "timg8_2.png"), result_count=1)
for eachPrediction, eachProbability in zip(predictions, probabilities):
print(eachPrediction + " : " + eachProbability)图像预测的代码也比较简洁,设置使用ResNet模型,采用的json和h5文件(训练结果),要预测的图像和预测的结果数量,最后打印出预测的结果:
![]()
最终预测是saber的概率是85%。
以上demo采用现有的库,实现过程也比较简单。但是在实际使用中还需要注意很多影响训练和预测结果的问题,比如图像的质量,训练的次数等等。可以看到本实例采用的是model_ex-040_acc-0.800000.h5,也即是说在测试集上训练的模型的准确率也只有80%(5张正确4张),效果不是很佳。同时,为了提高提取的人物头像的质量,还可以使用图像超分辨率进行处理,提升图像细节。