简介
在ImageNet数据集上,PeleeNet只有MobileNet模型的66%,并且比MobileNet精度更高。PeleeNet作为backbone实现SSD能够在VOC2007数据集上达到76.4%的mAP。文章总体上参考DenseNet的设计思路,提出了三个核心模块进行改进,有一定参考价值。
核心
PeleeNet实际上是DenseNet的变体,使用的依然是DenseNet的连接方法,核心的设计原则也和DenseNet相仿(特征重用)。
核心模块:
- Two-Way Dense Layer
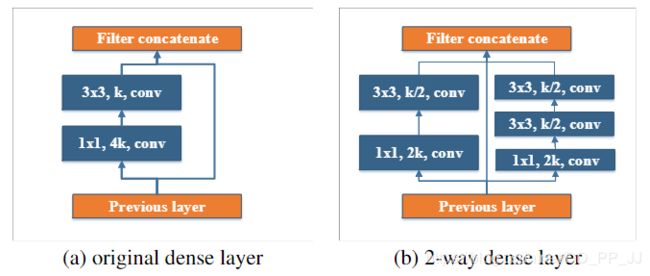
上边左边(a)图是DenseNet中设计的基本模块,其中k、4k代表filter的个数。右边(b)图代表PeleeNet中设计的基本模块,除了将原本的主干分支的filter减半(主干分支感受野为3x3),还添加了一个新的分支,在新的分支中使用了两个3x3的卷积,这个分支感受野为5x5。这样就提取得到的特征就不只是单一尺度,能够同时兼顾小目标和大目标。
这种设计和人脸检测算法SSH很像,只不过多了一个跨层连接,下图是SSH context Module:
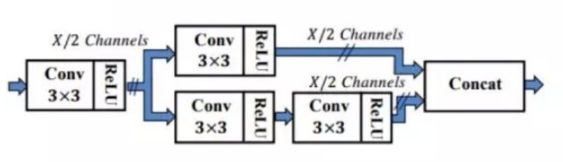
思想相似,实现略有不同。
- Stem Block
这个模块设计受Inceptionv4和DSOD的启发,想要设计一个计算代价比较小的模块。ResNet和DenseNet在第一层都是用的是一个7x7、stride为2的卷积层,浅层网络的作用是提取图像的边缘、纹理等信息,一般。Stem Block的设计就是打算以比较小的代价取代7x7的卷积。

这个模块可以在几乎不增加计算量的情况下提升特征的表达能力。这部分感受野计算可以参考这篇文章中的公式目标检测和感受野的总结和想法。
仔细看看上图展示的结构,先使用strided 3x3卷积进行快速降维,然后用了两分支的结构,一个分支用strided 3x3卷积, 另一个分支使用了一个maxpool。
这一部分和组合池化非常相似,stem block使用了strided 3x3卷积和最大值池化两种的优势引申而来的池化策略(组合池化使用的是最大值池化和均值池化),可以丰富特征层。
- 瓶颈层设置动态变化的通道数
在DenseNet中,有一个超参数k-growth rate, 用于控制各个卷积层通道个数,在DenseNet的瓶颈层中,将其固定为4k,也就是说瓶颈层是增加了模型的计算量,而不是减小模型的计算量。在PeleeNet中,将瓶颈层的通道个数根据输入的形状动态调整,节约了28.5%的计算消耗。

- 过渡层
在DenseNet中,过渡层是用于将特征图空间分辨率缩小的,并且过渡层中通道数会小于前一层的通道数。在PeleeNet中将过渡层和前一层通道数设置为一样的数值。
- 复合功能
为了提高速度,采用了conv+bn+relu的组合(而不是DenseNet中的预激活组合(conv+relu+bn)), 这样做是为了方便进行卷积和BN的合并计算,加速推理阶段的速度。
用PeleeNet做backbone优化SSD
- 特征图选择:选取了五个尺度的特征图(19x19,10x10,5x5,3x3,1x1),没有使用38x38大小的特征图
- 残差预测模块:residual prediction block, 该模块是用于对以上选取的几个特征图进行进一步的特征提取
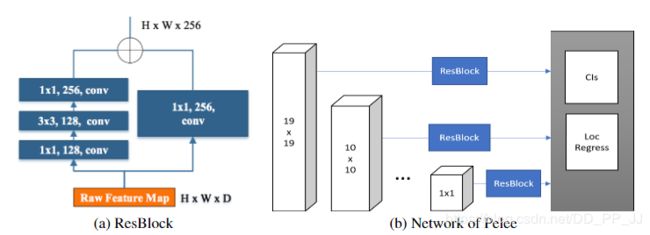
- ResBlock模块中使用1x1卷积相比直接用3x3卷积,可以减少21.5%的计算量。
PeleeNet是按照以下结构进行组织的。

实验
消融实验:
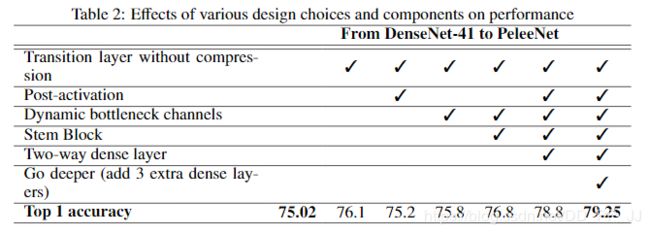
训练策略采用的是余弦学习率变化,在Standford Dog和ImageNet数据集上进行的训练。

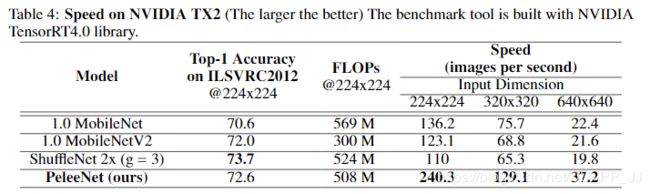
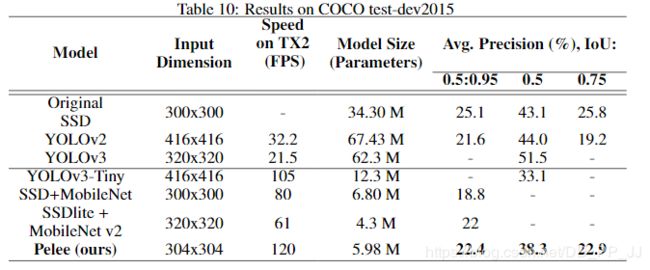
总结
PeleeNet相当于是避开了深度可分离卷积的使用,仅仅使用普通的卷积,就让模型能在移动端设备上实时运行。
核心创新点主要是Two-way Dense layer、Stem Block、ResBlock。各种对比实验做得比较充分,代码也开源了,官方代码大部分是基于caffe的,也有少部分是用pytorch构建的。
总体来说,PeleeNet创新程度一般,但是作者团队工程能力很强,实验非常丰富。PeleeNet将很多细碎的点融合到一起,最终在移动端设备上的表现还不错,也被很多研究轻量化网络的文章用来对比。
参考
https://github.com/Robert-JunWang/Pelee
https://github.com/Robert-JunWang/PeleeNet
https://arxiv.org/pdf/1804.06882.pdf