决策树相关算法——ID3、C4.5的详细说明及实现
前言
本篇博客记录的是使用python实现两个个决策树相关的算法模型—— ID3、C4.5。其中训练模型使用的数据集是Adult。尽管Sklearn包中都有这些算法的实现,但是自身根据算法思路实现一遍也是美滋滋的,其中酸甜自知(话说可以提高一定的代码编写能力和调试程序的能力),GitHub详细代码实现地址。
1.实现前期准备工作 —— what
1.1决策树的主要思想
决策树是基于特征对实例(sample)进行分类模型,可以理解为给定特征条件下类的条件概率分布。要进行分类的样本即给定的特征值,要预测出的label即在给定特征值条件类的概率最大——所属的类。决策树此时充当划分特征空间的一种方式。特征空间的维数为数据集的特征个数。经过ID3或C45算法将特征空间进行划分,并且划分后的每个特征空间区间对应着发生概率最大的类别label。属于count-based型。决策树的叶结点表示数据集中的类label,内部结点表示选择划分的特征。
1.2不得不知的概念
声明:下面是摘抄的(笔记)来自其他博客
熵:随机变量不确定性的度量,熵越大,不确定性越高。
设
X是一个取有限个值的离散随机变量,其概率分布为:
则随机变量X的熵的定义为:


条件熵:表示已知随机变量X的条件下随机变量Y的不确定性——H(Y|X)
H(Y|X)即X给定条件下Y的条件概率分布的熵对X的数学期望。
其中p(x)表示X= x发生的概率

信息增益:一般为特征选择的方式常用的还有卡方检验,交叉熵,信息增益——G(D,A)表示由选择特征A而使得对数据集分类的不确定性减少的程度,减少的越多,数据集分类的不确定性越低。表示特征A对数据集D 分类影响效果越好。
其中H(D)表示数据集label类别的熵即每个label取不同类别的值的时候得不确定性。 其中H(D|A)表示在选择特征A的条件下,数据集label类别的熵。 此时也可以表示类别label与特征的互信息 在`决策树中公式的应用`:

 其中对于样本集合D来说,随机变量X是样本的类别,即,假设样本有k个类别,每个类别的概率是|Ck|/|D|,其中|Ck|表示类别k的样本个数,|D|表示样本总数
其中对于样本集合D来说,随机变量X是样本的类别,即,假设样本有k个类别,每个类别的概率是|Ck|/|D|,其中|Ck|表示类别k的样本个数,|D|表示样本总数
信息增益比:信息增益偏向于选择取值较多的特征。在面对连续的数据(如体重、身高、年龄、距离等),或者每列数据没有明显的类别之分(最极端的例子的该列所有数据都独一无二),在这种情况下对于一个特征它的取值越多,根据此特征划分更容易得到类别更少的子数据集。原因是特征的取值越多,此时H(D|A)的值越小,信息增益就越大,所以特征选择时越容易被选。H(D|A)偏小的原因可根据上面公式H(D|A)的由来来推理。针对这一问题使用信息增益比这一指标对信息增益进行校正。
信息增益比 = 惩罚参数 * 信息增益
其中惩罚参数为HA(D)的倒数,即上式子中的Info的倒数,注意Info的计算和H(D|A)的为不同计算公式获得的
当某个特征对应的取值偏多时,Info计算后偏大,取倒数后为偏小,即惩罚参数为偏小,而信息增益比 = 惩罚参数 * 信息增益,即对信息增益进行了一定程度上的惩罚。


Gini系数:表示在样本集合中一个随机选中的样本被分错的概率。在CART算法中,分类树用基尼指数选择最优特征,决定在特征空间中选取哪一维的特征进行最优二分值切分。

其中pk表示选中的样本属于k类别的概率,则这个样本被分错的概率是(1-pk)
设样本集合中有K个类别,一个随机选中的样本可以属于这k个类别中的任意一个,因而对类别就加和
上式为样本集合D的Gini指数计算,其中Ck表示D中属于第K类的样本子集,K是数据集Label中的类别个数。
Gini(D,A)表示在特征A的条件下,集合D的基尼指数。
因为CART算法中构造的树是二叉树,所有二叉树根据特征A划分的特征空间后的两个子集为D1,D2.
其中Gini(D)表示数据集D的不确定性,Gini(D,A)表示经过A=a分割后数据集D的不确定性。所以进行特征选择的时候选择Gini(D)-Gini(D,A)较大的。

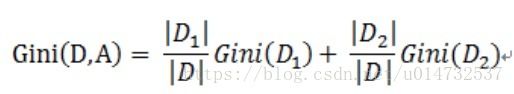
1.3决策树的主要步骤及原因
特征选择,特征的选择需要根据数据集的特点进行选择,有信息增益、信息增益比、Gini指数。即如何划分特征空间。
决策树的生成,根据特征选择的算法,对数据集进行递归的生成树。
决策树的修剪,由于递归生成的决策树对训练数据分类准确,但对未知的测试数据却不再那么准确,也就是泛化能力较弱,过于拟合训练数据。此时需要对生成的复杂决策树进行简化处理,从而让拟合状态变成正常化状态。
2具体实现过程 —— How
Step1 数据前期准备工作
数据集说明: 本次实验选取的数据集是Adult,下图是该数据集的一些说明。考虑到使用的是决策树分类模型,还需要对数据集进行详细的分析。

数据集详细分析
由于Mark表格问题,此处是截取的zxhohai博主的数据集属性说明图。

从下载的
Adult数据集说明文件adult.name中能看出,数据集中包含8个离散型特征,6个连续性属性特征。
离散型特征8个:workclass有8个取值;education有16个取值;marital-status7个取值;occupation有14个取值;relationship有6个取值;race有5个取值;sex有两个取值;native-country有41个取值。
连续性特征6个。
对连续特征的处理
由于连续型特征取值较多,一方面ID3算法更偏向于选择取值较多的特征,另一方面,当选择该特征进行划分的时候,容易造成决策树深度较浅分支较多的问题,从而带来严重的过拟合问题。所以需要对连续型特征进行分段离散处理。
具体如何进行分段离散处理???—— C4.5和ID3的决策树是支持多叉树的形式的,而CART是只支持二叉树。
处理方式,将连续型特征的取值按照从小到大的顺序排列,然后按顺序两两之间取中点Qi
计算该特征取Qi值后的数据集的信息增益,取信息增益率最大的为切分点。切分点Qi,<=Qi为左支树,>Qi为右支树。
对于离散特征的取值超过一定数目的特征,也可以对取值再次分段离散处理。
Step2 数据处理
数据的导入和缺失值,重复值处理
def load_data(flods):
adult_train_df = pd.read_table(flods[0], header=None ,sep=',',
names=['age', 'workclass', 'education', 'education-num', 'marital-status',
'occupation','relationship', 'race', 'sex', 'capital-gain', 'capital-loss',
'hours-per-week', 'native-country','label'],engine='python',dtype=int)
adult_test_df = pd.read_table(flods[1], header=None, sep=',',
names=['age', 'workclass', 'education', 'education-num', 'marital-status',
'occupation', 'relationship', 'race', 'sex', 'capital-gain', 'capital-loss',
'hours-per-week', 'native-country', 'label'], engine='python',dtype=int)
# 打乱data中样本的顺序
# adult_train_df = shuffle(adult_train_df)
adult_train_df = adult_train_df.sample(frac=1).reset_index(drop=True)
# adult_test_df = shuffle(adult_test_df)
adult_test_df = adult_test_df.sample(frac=1).reset_index(drop=True)
print('init shape train-test =================')
print(adult_train_df.shape)
print(adult_test_df.shape)
# 离散分段处理
# D = np.array(adult_train_df['label']).reshape(adult_train_df.shape[0], 1)
# age_did = devide_feature_value(adult_train_df['age'],D)
train_data_x = np.array(adult_train_df.iloc[:,0:13])
train_data_y = np.array(adult_train_df.iloc[:,13:])
test_data_x = np.array(adult_test_df.iloc[:, 0:13])
test_data_y = np.array(adult_test_df.iloc[:, 13:])
return train_data_x,train_data_y,test_data_x,test_data_y
查看连续型数据的分布情况
#例如年纪
age_ser = adult_train_df['age'].value_counts(sort=False).sort_index()
# age_ser
age_ser.plot(kind='bar')
plt.show()
连续型特征数据处理
此处为ID3和C45的处理方式的一般方式,而CART算法处理方式为不停的二分离散特征。主要区别为ID3和C45在选取某个特征进行划分后,接下来的子树便不再使用该特征进行划分了,而CART是不断的二分离散特征,即将特征的取值二分化后,对每个子区域再次选择最优特征和最优划分点。
当然对于此处的ID3和C45算法也可以选择用其他划分方法,可以多划分几段。而CART则必须分为二段。
def divide_feature_value(series,D):
#series为要处理的特征Series
#D 为数据集的label
sets = set(series)
mid_value = []
a = float(sets.pop())
#取相邻点的中值
for par in sets:
a = (a + par) / 2.0
mid_value.append(a)
a = float(par)
max_divide = mid_value[0]
max_ent = 0.0
ent_d = calc_ent(D)
#查找最好的分裂点
for mid in mid_value:
Q1 = D[series < mid]
Q2 = D[series >= mid]
D_length = float(D.shape[0])
Q1_length = Q1.shape[0]
Q2_length = D_length - Q1_length
#条件熵
H_Q_D = Q1_length / D_length * calc_ent(Q1) + Q2_length / D_length * calc_ent(Q2)
H = ent_d - H_Q_D
if(H > max_ent):
max_ent = H
max_divide = mid
return max_divide
#使用,对其他六个特征同样使用
D = np.array(adult_train_df['label']).reshape(adult_train_df.shape[0], 1)
age_div = divide_feature_value(adult_train_df['age'],D)
mask1 = adult_train_df['age'] >= age_div
mask2 = adult_train_df['age'] < age_div
adult_train_df['age'][mask1]=1
adult_train_df['age'][mask1]=2
此处我的实现的是先将各个属性值转换为数值型,然后对连续型特征通过观察进行分段处理的,没有按照计算信息增益来找最佳切分点。
def transToValues(file_name,save_name,remove_unKnowValue=True,remove_duplicates=True):
converters = {0: adult_age,1: adult_workclass,3: adult_education,4: adult_education_num,5: adult_marital_status,
6: adult_occupation,7: adult_relationship,8: adult_race,9: adult_sex,10: adult_capital_gain_loss,
11: adult_capital_gain_loss,12: adult_hours_per_week,13: adult_native_country,14: adult_label}
adult_df = pd.read_table(file_name, header=None ,sep=',',converters=converters,
names=['age', 'workclass', 'fnlwgt', 'education', 'education-num', 'marital-status',
'occupation','relationship', 'race', 'sex', 'capital-gain', 'capital-loss',
'hours-per-week', 'native-country','label'],engine='python')
if remove_duplicates:
# 移除df中重复的值
adult_df.drop_duplicates(inplace=True)
print('delete duplicates shape train-test =================')
print(adult_df.shape)
if remove_unKnowValue:
# 移除df中缺失的值
adult_df.replace(['?'], np.NaN, inplace=True)
adult_df.dropna(inplace=True)
print('delete unKnowValues shape train-test =================')
print(adult_df.shape)
adult_df.drop('fnlwgt',axis=1,inplace=True)
adult_df.to_csv(save_name,header=False,index=False)
if __name__ == '__main__':
train_file = '../data/adult/adult.data'
test_file = '../data/adult/adult.test'
train_deal_file = '../data/adult/adult_deal.data'
test_deal_file = '../data/adult/adult_deal.test'
#deal with duplicates and unKnowValue
transToValues(train_file,train_deal_file)
transToValues(test_file,test_deal_file)
# trans to value
transToValues(train_deal_file,'../data/adult/adult_deal_value.data',remove_duplicates=False,remove_unKnowValue=False)
transToValues(test_deal_file,'../data/adult/adult_deal_value.test',remove_duplicates=False,remove_unKnowValue=False)
Step3 特征选择
此处将ID3和C45算法重构为一个模板,只需要传入一个特征选择的select_func的函数名即可调用。
其中ID3是选择信息增益最大的特征进行划分;而C45是选择信息增益比最大的特征进行划分。
#ID3或C45
def _select_feature(self,X,y,feature_list,select_func):
ent_gain_max = 0.0
ent_max_feature_index = 0
for feature in feature_list:
A = X[:,feature]
D = y
ent_gain = select_func(A,D)
if(ent_gain > ent_gain_max):
ent_gain_max = ent_gain
ent_max_feature_index = feature
return ent_gain_max,ent_max_feature_index
#使用方式
select_func = calc_ent_gain /select_func = calc_ent_gain_rate #特征选择函数设置
ent_gain_max, ent_max_feature_index = self._select_feature(X,y,feature_list,select_func)
Step4 递归创建生成树(自上而下的创建的)
ID3和C45算法思想(网上截图)

实现1-构造决策树的结点:
class TreeNode():
"""
树节点类
"""
def __init__(self):
#叶子结点需要的属性
self.type = -1 # 结点的类型label-类标记
#非叶子结点需要的属性
self.next_nodes = [] # 该结点指向的下一层结点
self.feature_index = -1 #该结点对应的特征编号
# self.feature_value = 0 #该结点划分的特征取值
self.select_value = 0 #特征选择(信息增益、信息增益比、gini)值
def add_next_node(self,node):
if type(node) == TreeNode:
self.next_nodes.append(node)
else:
raise Exception('node not belong to TreeNode type')
def add_attr_and_value(self,attr_name,attr_value):
"""
动态给节点添加属性,因为结点分为叶子结点,正常结点
:param attr_name:属性名
:param attr_value:属性值
"""
setattr(self,attr_name,attr_value)
实现2-生成树:
def _create_tree(self,X,y,feature_list,epsoion,start_node,Vi=-1):
"""
:param X: 数据集X
:param y: label集合
:param feature_list: 特征的id list
:param epsoion:阈值
:param start_node:决策树的启始结点
:param Vi: feature value
:return: 指向决策树的根结点的指针
"""
# 结点
node = TreeNode()
#若所有实例都属于一个类别
C = set(y[:,0]) #分类的类别集合
if(len(C) == 1 ):
node.type = tuple(C)[0] #该Ck作为该结点的类标记
start_node.add_next_node(node)
return
# 特征集合A为空,将D中实例数最大的类Ck作为该结点的类标记
if(len(feature_list) == 0):
max_value = self._get_max_count_array(y[:,0])
node.type = max_value
start_node.add_next_node(node)
return
# select feature
if self._mode == 'ID3' or self._mode == 'C4.5':
select_func = calc_ent_gain
if self._mode == 'C4.5':
select_func = calc_ent_gain_rate
ent_gain_max, ent_max_feature_index = self._select_feature(X,y,feature_list,select_func)
# 最大信息增益小于设定的某个阈值
if ent_gain_max < epsoion:
type_value = self._get_max_count_array(y[:, 0])
node.type = type_value
start_node.add_next_node(node)
return
else:
node.feature_index = ent_max_feature_index
node.select_value = ent_gain_max
type_value = self._get_max_count_array(y[:,0])
node.type = type_value
if (Vi != -1):
node.add_attr_and_value("feature_value", Vi)
start_node.add_next_node(node)
# 获取选取的特征的所有可能值
Ag_v = set(X[:,ent_max_feature_index])
# A - Ag
feature_list.remove(ent_max_feature_index)
# Di
for v in Ag_v:
# Di 为 Xi , yi
mask = X[:,ent_max_feature_index] == v
Xi = X[mask]
yi = y[mask]
#此处有个深度拷贝
feature_list_new = copy.deepcopy(feature_list)
self._create_tree(Xi, yi, feature_list_new, epsoion, node, Vi=v)
return
step5 剪枝算法
剪枝主要是为了解决决策树分类带来的模型过拟合问题,两种方式剪枝和随机森林。其中随机森林下篇详述。
5.1说明
我们都知道过拟合的问题可能有
三个原因:数据中有噪声;训练数据数据不足;训练模型过度导致模型非常复杂。一般来说,决策树主要是由于第三个原因造成的。所以需要对生成的复杂模型进行一定程度上的简化。
5.2理解
1.决策树的剪枝是通过极小化决策树的代价函数来实现的。决策树的代价函数公式:
其中树T的叶结点个数为|T|,t是树T的叶结点,该叶结点有Nt个样本点,其中k类样本点有Ntk个,k=1,2,…,K,Ht(T)为叶结点t上的经验熵,α≥0为超参数。一个叶节点由于误差的原因可能分到多个类别的样本点,所以存在一个叶子结点有K类样本点。其中经验熵Ht(T)的公式最上面有。
2.决策树代价函数Ca(T)的理解
C|T|表示模型对训练数据的预测误差,此处还是不是很明白为什么C|T|的公式这样的原因,猜想:C|T|为模型对训练数据后的遗留下的样本数的不确定性的多少。|T|表示模型的复杂度,使用参数a权衡C|T|与|T|之间的影响即模型的复杂度和模型与训练数据的拟合度。模型过于复杂容易过拟合,需要调节a的值降低复杂度。此处是通过剪枝来实现。剪枝的过程中a的值和|T|的变化的需要动态规划的思想来求解最优值。
3.从机器学习训练模型的思路理解Ca(T)
决策树模型训练的C(T)极大似然估计为:
代价函数为正则化的极大似然估计,剪枝的过程为不断极小化代价函数,
正则项可以理解为a|T|.

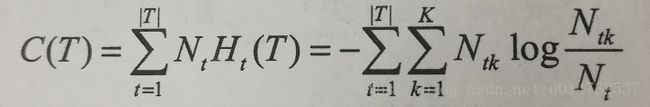

5.3简单的剪枝算法实现(此处是设置合适的a值)
此图是网上截图,重在理解前面的剪枝思想

从坑中爬起来
1.进行算法实践前,一定需要对数据集进行详细分析——包括但不限于数据的特征缺失,分布问题的观察,
数据的各个特征的离散、连续状态,取值分布情况的查看。
2.了解的算法不要仅仅限于了解,时间充足的话最好能亲自去实现,#因为在实现的过程中,平常不关注的细节性的东西更容易暴露出来。具体表现在程序的某个细节没处理好,程序运行的结果就很可能不理想。
参考链接
决策树剪枝实现
Adult数据集说明