Redis 为什么这么快? Redis 的有序集合 zset 的底层实现原理是什么? —— 跳跃表 skiplist
Redis有序集合 zset 的底层实现——跳跃表skiplist
Redis简介
Redis是一个开源的内存中的数据结构存储系统,它可以用作:数据库、缓存和消息中间件。
它支持多种类型的数据结构,如字符串(Strings),散列(Hash),列表(List),集合(Set),有序集合(Sorted Set或者是ZSet)与范围查询,Bitmaps,Hyperloglogs 和地理空间(Geospatial)索引半径查询。其中常见的数据结构类型有:String、List、Set、Hash、ZSet这5种。
Redis 内置了复制(Replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(Transactions) 和不同级别的磁盘持久化(Persistence),并通过 Redis哨兵(Sentinel)和自动分区(Cluster)提供高可用性(High Availability)。
Redis也提供了持久化的选项,这些选项可以让用户将自己的数据保存到磁盘上面进行存储。根据实际情况,可以每隔一定时间将数据集导出到磁盘(快照),或者追加到命令日志中(AOF只追加文件),他会在执行写命令时,将被执行的写命令复制到硬盘里面。您也可以关闭持久化功能,将Redis作为一个高效的网络的缓存数据功能使用。
Redis不使用表,他的数据库不会预定义或者强制去要求用户对Redis存储的不同数据进行关联。
数据库的工作模式按存储方式可分为:硬盘数据库和内存数据库。Redis 将数据储存在内存里面,读写数据的时候都不会受到硬盘 I/O 速度的限制,所以速度极快。
(1)硬盘数据库的工作模式: 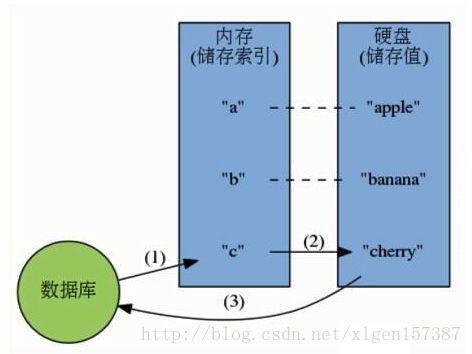
(2)内存数据库的工作模式: 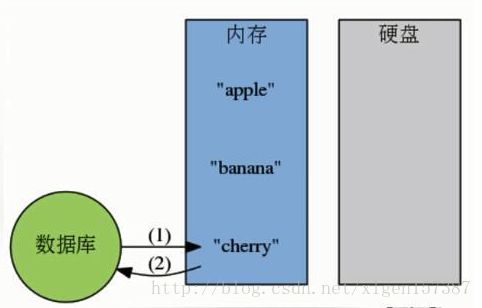
看完上述的描述,对于一些常见的Redis相关的面试题,是否有所认识了,例如:什么是Redis、Redis常见的数据结构类型有哪些、Redis是如何进行持久化的等。
redis作为一种内存KV数据库,提供了string, hash, list, set, zset等多种数据结构。其中有序集合zset在增删改查的性质上类似于C++ stl的map和Java的TreeMap,提供了一组“键-值”对,并且“键”按照“值”的顺序排序。但是与C++ stl或Java的红黑树实现不同的是,redis中有序集合的实现采用了另一种数据结构——跳跃表。跳跃表是有序单链表的一种改进,其查询、插入、删除也是O(logN)的时间复杂度。
Redis到底有多快
Redis采用的是基于内存的采用的是单进程单线程模型的 KV 数据库,由C语言编写,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。这个数据不比采用单进程多线程的同样基于内存的 KV 数据库 Memcached 差!有兴趣的可以参考官方的基准程序测试《How fast is Redis?》(https://redis.io/topics/benchmarks)
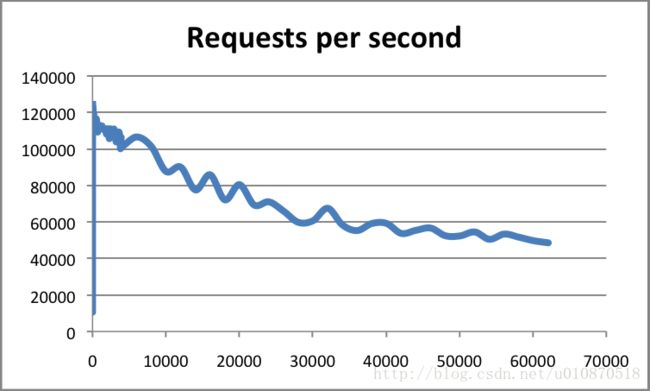
横轴是连接数,纵轴是QPS。此时,这张图反映了一个数量级,希望大家在面试的时候可以正确的描述出来,不要问你的时候,你回答的数量级相差甚远!
Redis为什么这么快
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路I/O复用模型,非阻塞IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
以上几点都比较好理解,下边我们针对多路 I/O 复用模型进行简单的探讨:
(1)多路 I/O 复用模型
多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈,主要由以上几点造就了 Redis 具有很高的吞吐量。
那么,为什么Redis是单线程的
我们首先要明白,上边的种种分析,都是为了营造一个Redis很快的氛围!官方FAQ表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!)。

可以参考:https://redis.io/topics/faq
看到这里,你可能会气哭!本以为会有什么重大的技术要点才使得Redis使用单线程就可以这么快,没想到就是一句官方看似糊弄我们的回答!但是,我们已经可以很清楚的解释了为什么Redis这么快,并且正是由于在单线程模式的情况下已经很快了,就没有必要在使用多线程了!
但是,我们使用单线程的方式是无法发挥多核CPU 性能,不过我们可以通过在单机开多个Redis 实例来完善!
警告1:这里我们一直在强调的单线程,只是在处理我们的网络请求的时候只有一个线程来处理,一个正式的Redis Server运行的时候肯定是不止一个线程的,这里需要大家明确的注意一下!
跳跃表的原理
zskiplist跳表结构保存跳跃表信息,表头、表尾、长度、最大层数
header:表头节点
tail:表尾节点
level:最大层数
length:跳表节点数量
zskiplistNode跳表节点每个节点层高1~32随机数
ele:sds字符串对象,保存节点的member成员,唯一的。
score:double类型的分数,从小到大排序。score相同,按照ele的字典顺序排序。
backward:后退指针,节点的prev节点,用于表尾向表头遍历。
level数组:每个元素都包含一个forward前进指针和span跨度。
forward:前进指针,每一层都有指向表尾方向的前进指针,用于实现多层链表。
span:跨度,记录两个节点之间的距离,用于计算rank排名。
跳跃表的思想来自于一篇论文:Skip Lists: A Probabilistic Alternative to Balanced Trees. 如果想要深入了解跳跃表,可以阅读论文原文。这里引用论文中的一幅图对跳跃表的原理作一个简单的说明。

上图用a,b,c,d,e五种有序链表及其变式(变式的名字是我随便起的)说明了跳跃表的motivation.
[a] 单链表:查询时间复杂度O(n)
[b] level-2单链表:每隔一个节点为一个level-2节点,每个level-2节点有2个后继指针,分别指向单链表中的下一个节点和下一个level-2节点。查询时间复杂度为O(n/2)
[c] level-3单链表:每隔一个节点为一个level-2节点,每隔4个节点为一个level-3节点,查询时间复杂度O(n/4)
[d] 指数式单链表:每2^i个节点的level为i+1,查询时间复杂度为O(log2N)
[e] 跳跃表:各个level的节点个数同指数式单链表,但出现的位置随机,查询复杂度仍然是O(log2N)吗
之所以这里关心查询复杂度,因为有序链表的插入和删除复杂度等于查询复杂度。
作为一种概率性算法,文章证明了跳跃表查询复杂度的期望是O(logN).

redis有序集合采用跳跃表的原因
为什么redis的有序集合采用跳跃表而不是红黑树呢?对于这个问题,可以在 https://news.ycombinator.com/item?id=1171423 找到作者本人的一个回答:
They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
About the Append Only durability & speed, I don’t think it is a good idea to optimize Redis at cost of more code and more complexity for a use case that IMHO should be rare for the Redis target (fsync() at every command). Almost no one is using this feature even with ACID SQL databases, as the performance hint is big anyway.
About threads: our experience shows that Redis is mostly I/O bound. I’m using threads to serve things from Virtual Memory. The long term solution to exploit all the cores, assuming your link is so fast that you can saturate a single core, is running multiple instances of Redis (no locks, almost fully scalable linearly with number of cores), and using the “Redis Cluster” solution that I plan to develop in the future.
可以看到redis选择跳跃表而非红黑树作为有序集合实现方式的原因并非是基于并发上的考虑,因为redis是单线程的,选用跳跃表的原因仅仅是因为跳跃表的实现相较于红黑树更加简洁。
链接:https://blog.csdn.net/da_kao_la/article/details/94744886
redis里面是用skiplist是为了实现zset这种对外的数据结构。zset提供的操作非常丰富,可以满足许多业务场景,同时也意味着zset相对来说实现比较复杂。
skiplist数据结构简介

如图,跳表的底层是一个顺序链表,每隔一个节点有一个上层的指针指向下下一个节点,并层层向上递归。这样设计成类似树形的结构,可以使得对于链表的查找可以到达二分查找的时间复杂度。
按照上面的生成跳表的方式上面每一层节点的个数是下层节点个数的一半,这种方式在插入数据的时候有很大的问题。就是插入一个新节点会打乱上下相邻两层链表节点个数严格的2:1的对应关系。如果要维持这种严格对应关系,就必须重新调整整个跳表,这会让插入/删除的时间复杂度重新退化为O(n)。
为了解决这一问题,skiplist他不要求上下两层链表之间个数的严格对应关系,他为每个节点随机出一个层数。比如,一个节点的随机出的层数是3,那么就把它插入到三层的空间上,如下图。

那么,这就产生了一个问题,每次插入节点时随机出一个层数,真的能保证跳表良好的性能能么,
首先跳表随机数的产生,不是一次执行就产生的,他有自己严格的计算过程,
1首先每个节点都有最下层(第1层)指针
2如果一个节点有第i层指针,那么他有第i层指针的概率为p。
3节点的最大层数不超过MaxLevel
我们注意到,每个节点的插入过程都是随机的,他不依赖于其他节点的情况,即skiplist形成的结构和节点插入的顺序无关。
这样形成的skiplist查找的时间复杂度约为O(log n)。
redis中的skiplist
- 当数据较少的时候,zset是由一个ziplist来实现的
- 当数据较多的时候,zset是一个由dict 和一个 skiplist来实现的,dict用来查询数据到分数的对应关系,而skiplist用来根据分数查询数据。
为了支持排名rank查询,redis中对skiplist做了扩展,使得根据排名能够快速查到数据,或者根据分数查到数据之后容易获得排名,二者都是O(log n)。
| 1 2 3 4 5 6 |
|
dict的key保存元素的值,字典的value保存元素的score,跳表节点的robj保存元素的成员,节点的score保存对应score。并且会通过指针来共享元素相同的robj和score。
skiplist的数据结构定义
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
开头定义了两个常量 ZSKIPLIST_MAXLEVEL和ZSKIPLIST_P,即上文所提到的p和maxlevel。
zskiplistNode表示skiplist的节点结构
- obj字段存放节点数据,存放string robj。
- score字段对应的是节点的分数。
- backward字段是指向前一个节点的指针,节点只有一个向前指针,最底层是一个双向链表。
- level[]存放各层链表的向后指针结构,包含一个forward ,指向对应层后一个节点;span字段指的是这层的指针跨越了多少个节点值,用于计算排名。(level是一个柔性数组,因此他占用的内存不在zskiplistNode里,也需要单独为其分配内存。)
zskiplist 定义了skiplist的外观,包含
- header和tail指针
- 链表长度 length
- level表示 跳表的最大层数

上图就是redis中一个skiplist可能的结构,括号中的数字代表 level数组中span的值,即跨越了多少个节点。
假设我们在这个skiplist中查找score=89的元素,在查找路径上,我们只需要吧所有的level指针对应的span值求和,就可以得到对应的排名;相反,如果查找排名的时候,只需要不断累加span保证他不超过指定的值就可以求得对应的节点元素。
三、REDIS_ENCODING_INTSET
redis中使用intset实现数量较少数字的set。
| 1 |
|
实际上 intset是一个由整数组成的有序集合,为了快速查找元素,数组是有序的,用二分查找判断一个元素是否在这个结合上。在内存分配上与ziplist类似,用一块连续的内存保存数组元素,并且对于大整数和小证书 采用了不同的编码。
结构如下
| 1 2 3 4 5 6 7 8 9 10 |
|
encoding 数据编码 表示intset中的每个元素用几个字节存储。(INTSET_ENC_INT16 用两个字节存储,即两个contents数组位置 INTSET_ENC_INT32表示4个字节 INTSET_ENC_INT64表示8个字节)
length 表示inset中元素的个数
contents 柔性数组,表示存储的实际数据,数组长度 = encoding * length。
另外,intset可能会随着数据的添加改编他的编码,最开始创建的inset使用 INTSET_ENC_INT16编码。

如上图 intset采用小端存储。
关于插入逻辑。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
intsetadd在intset中添加新元素value。如果value在添加前已经存在,则不会重复添加,这个时候success设置值为0
如果要添加的元素编码比当前intset的编码大。调用intsetUpgradeAndAdd将intset的编码进行增长,然后插入。
调用intsetSearch 如果能查找到,不会重复添加。没查到调用intsetResize对其进行扩容(realloc),同时intsetMoveTail将带插入位置后面的元素统一向后移动一个位置。返回值是一个新的intset指针,替换原来的intset指针,总的时间复杂度为O(n)。
https://www.cnblogs.com/chafanbusi/p/10715036.html
Kotlin 开发者社区

国内第一Kotlin 开发者社区公众号,主要分享、交流 Kotlin 编程语言、Spring Boot、Android、React.js/Node.js、函数式编程、编程思想等相关主题。
越是喧嚣的世界,越需要宁静的思考。