随机抽样一致性(RANSAC)算法能够有效的剔除特征匹配中的错误匹配点。
实际上,RANSAC能够有效拟合存在噪声模型下的拟合函数。实际上,RANSAC算法的核心在于将点划分为“内点”和“外点”。在一组包含“外点”的数据集中,采用不断迭代的方法,寻找最优参数模型,不符合最优模型的点,被定义为“外点”。这就是RANSAC的核心思想。
RANSAC原理
OpenCV中滤除误匹配对采用RANSAC算法寻找一个最佳单应性矩阵H,矩阵大小为3×3。RANSAC目的是找到最优的参数矩阵使得满足该矩阵的数据点个数最多,通常令h33=1来归一化矩阵。由于单应性矩阵有8个未知参数,至少需要8个线性方程求解,对应到点位置信息上,一组点对可以列出两个方程,则至少包含4组匹配点对。
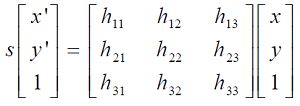
RANSAC算法从匹配数据集中随机抽出4个样本并保证这4个样本之间不共线,计算出单应性矩阵,然后利用这个模型测试所有数据,并计算满足这个模型数据点的个数与投影误差(即代价函数),若此模型为最优模型,则对应的代价函数最小。
损失函数:

也就是通过随机抽样求解得到一个矩阵,然后验证其他的点是否符合模型,然后符合的点成为“内点”,不符合的点成为“外点”。下次依然从“新的内点集合”中抽取点构造新的矩阵,重新计算误差。最后误差最小,点数最多就是最终的模型。
RANSAC算法步骤:
RANSAC算法步骤:
1. 随机从数据集中随机抽出4个样本数据 (此4个样本之间不能共线),计算出变换矩阵H,记为模型M;
2. 计算数据集中所有数据与模型M的投影误差,若误差小于阈值,加入内点集 I ;
3. 如果当前内点集 I 元素个数大于最优内点集 I_best , 则更新 I_best = I,同时更新迭代次数k ;
4. 如果迭代次数大于k,则退出 ; 否则迭代次数加1,并重复上述步骤;
注:迭代次数k在不大于最大迭代次数的情况下,是在不断更新而不是固定的;

其中,p为置信度,一般取0.995;w为"内点"的比例 ; m为计算模型所需要的最少样本数=4;
关于RANSAC算法的思想,可以用下图表示
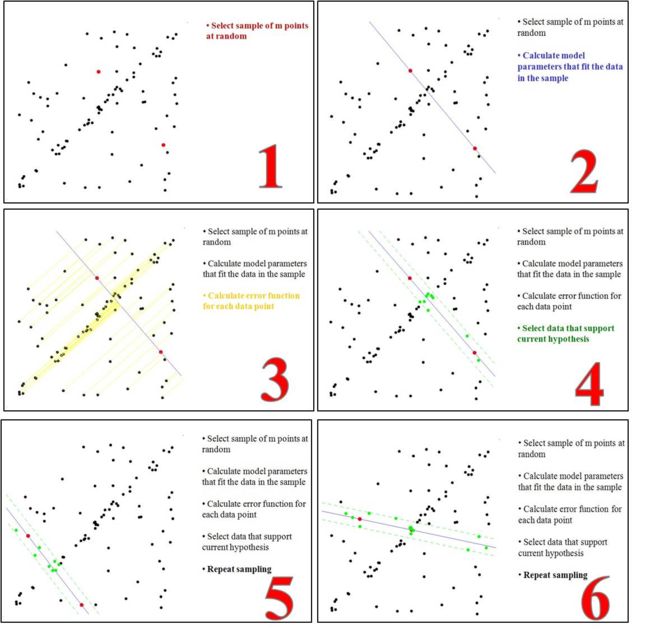
也就是RANSAC算法的本质是:在存在噪声的数据中,我们求解一个模型,使得非噪声数据可以用该模型表示,而噪声数据被排除在外。
分享三个讲解RANSAC算法的网址:
https://www.csdn.net/gather_2d/MtjaMg3sNDAwNS1ibG9n.html
https://www.cnblogs.com/xrwang/archive/2011/03/09/ransac-1.html
https://blog.csdn.net/yanghan742915081/article/details/83005442