如何优化WebRTC提升直播体验?

全民快乐资深音视频工程师郭奕在LiveVideoStackCon 2018音视频技术大会的演讲中从工程师的角度讲述了如何利用WebRTC打造出具备实时互动能力的应用,包括从信令的交互到媒体的传输需要完成的工作。LiveVideoStack对演讲内容进行了整理。
文 / 郭奕
整理 / LiveVideoStack
大家好,我是来自全民快乐科技有限公司的郭奕,接下来我将从一个工程师的角度为大家分享如何更好地利用WebRTC为应用赋能。本次分享将以“给音视频实时通讯应用打分“为线索,与大家一起探索如何提升以直播连麦、传统音视频会议等为主要应用场景的实时互动音视频通讯用户体验。
1. 给音视频实时通讯应用打个分

如果按照颜值为上图中的几位人物打分,我想绝大多数人会把最高分留给右二的秋香,这其实告诉我们一定要结合实际场景才能为音视频实时通讯应用打出客观准确的分数。
本次赋能的目标APP为StarMaker——全民快乐旗下一款活跃用户主要集中在印度、印尼、中东等地区的音乐视频社交APP,Android端用户规模远大于iOS端。

虽然StarMaker的品类应当被定义为社交应用,但却具备非常多的音乐基因,这就使得单纯的人声清晰已无法满足用户对这款APP的需求,我们需要进一步提高此款产品在音乐方面的综合质量。
在我们引入RTC之前此应用就已具备直播等功能,且已经具备一套非常完善的音视频采集、处理体系。考虑到平台的可维护性与模块的复用性,我们需要在对其进行改造的同时尽可能保持其核心模块的完整与稳定。

一款优秀的RTC应用具备哪些特质呢?最重要的应当是实时性。优秀的RTC应用能够给用户近乎面对面交流的快感,用户需要做的也仅是联网后打开APP即可。如果不考虑服务本身与服务器架构,在良好的网络环境与理想的终端条件下实现上述目标并不是一件十分困难的事情,而这显然是不现实的。因此面对复杂的网络环境与碎片化的终端情况我们能做的只有努力适应与提高兼容性,这也是实现良好用户体验的必由之路。

首先我们给自己定一个小目标:为实现70分的RTC应用我们应当做出什么努力?
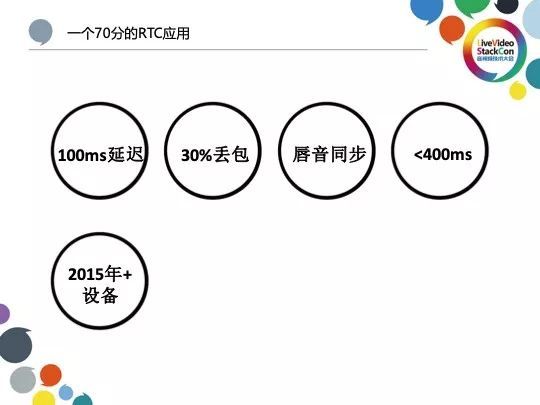
首先从设备端到服务器的往返时延需要被控制在100ms,且在此基础上控制丢包率在30%;唇音同步也是一项需要达到的关键指标,而端对端的延迟需小于400毫秒;最后一点需达到的便是能够为2015年以后的设备提供流畅完整的服务。这些数据并非简单的确立,经过统计我们发现北京办公室与一个部署在印度的机房之间的RTT大约在150ms左右,而印度机房中里有80%以上的RTT都在100ms以下;30%的随机丢包则是一个RCT SDK较为入门的达标水准,而根据Google最新的官方统计大约70%以上的Android用户所使用的移动终端已经预装或升级至Android 6.0以上的系统,且Android 6.0 的发布时间在2015年4月左右。由于我们的用户多集中于 Android 平台,这就要求我们在设计之初需要考虑到平台可在NEXUS 6与iPhone 6以后的设备上稳定运行。
2. 集成WebRTC
我们的工作就是将WebRTC集成至应用,主要从服务器端与客户端两方面入手工作。虽然WebRTC是一开始是按照P2P设计的,但是为提高服务稳定性我们需要背后需要强大的服务器作为支撑;而从信令角度来说WebRTC也不能完全算作P2P。
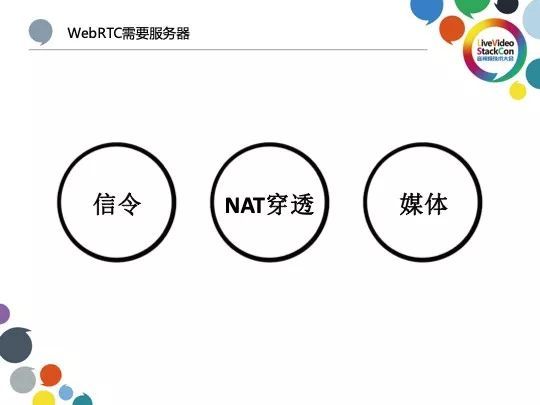
作为建立通话实现控制的基础,信令服务器在WebRTC所需服务器中至关重要,而NAT穿透服务器则是WebRTC中建立媒体过程必需的服务器支持;媒体服务器则是为完成诸如多方通讯、视频录制等较为繁重的媒体处理任务必不可少的关键一环。其中媒体服务器主要分为RTP转发与混流,前者是我们较为熟悉的SFU而后者则是MCU。

上图展示的是一个互动直播所需的基本框架,可以看到我们使用了SFU与MCU。SFU的优点在于可节省一部分宝贵的上行带宽而MCU的优点则是可明显节省流量成本并将多路流混成一路流,再将其转为RTMP并转推至CDN。结合连麦场景,上图左侧连接SFU并传输媒体流的三个设备可以理解为连麦的三方,SFU在接受来自连麦三方的媒体流的同时会将此三方媒体流转至MCU并进行混流与RTMP流转换处理,处理完成的媒体流会被推送至CDN从而让观众端可从CDN上拉去相应媒体流并观看视频。

如何快速搭建可完成上述处理流程的服务器框架?这里我们就需要借助开源的力量,上图展示了一些我们所参与社区提供的良好解决方案:SFU的开源服务器解决方案有Licode、Janus、Jitsi与Mediasoup,在选择时我们需要考虑整个团队的技术栈情况,若团队技术栈偏向于底层,那么推荐选择更多使用C++的Janus方案,而如果习惯基于Java开发那么Jitsi则是不错的选择;这里需要提醒的是,Licode中包含一个官方称之为MCU的模块,但实际上其并不具备混流的功能。
如果是MCU的开源服务器解决方案我们推荐选择Kurento,其内部使用了GStreamer而最底层则使用glib;但Kurento的学习曲线非常陡峭这样的好处在于其整个接口的灵活性非常出色,但出色的灵活性也意味着内部的高复杂性,这也是我们在选择此方案是需要重点关注的方面。如果对MCU的要求没有如此严苛,我们也可以使用FFmpeg自研的服务器。
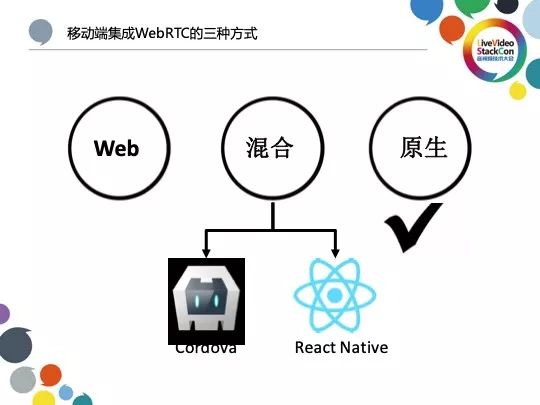
我们的客户端集成了WebRTC,在iOS平台的Safari浏览器支持WebRTC后移动端集成WebRTC的方式主要分为以下三种:依赖手机浏览器的Web方式与直接将WebRTC原生代码集成至应用端的原生方式,以及兼具二者特性的混合方式。
混合方式的好处在于其可跨越平台限制为Web端带来接近于原生的特性与交互体验,其代表有Cordova与React Native;但这两种方案还远不能满足我们期待的一个Web在所有平台都能提供一致体验的需求且Cordova的版本更新迭代频繁,因此选择此方案的前提是技术栈更偏向前端而底层如WebRTC则需支持,同时混合方式的试错成本也比较高。
当然我们也可以选择原生的方式,前提是并没有非常强的跨平台需求。由于我们的业务不需要PC端仅依赖移动端开展,原生自然而然成为我们集成WebTRTC的首选方式。
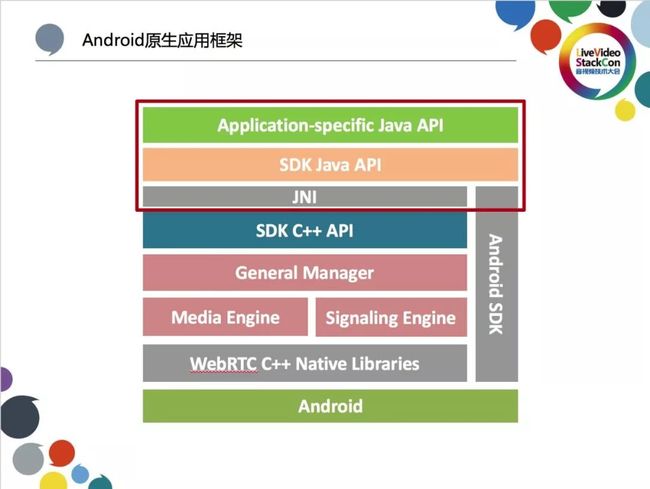
上图展示的是我们的Android原生应用软件框架图,主要基于以下几个关键点进行架构:首先框架需要具有一定移植性,允许我们在Android端完成开发后将平台快速移植至iOS端;其次请观察图中标为橙红色的三个基于WebRTC C++原生代码库建立的模块,分别为通话管理、媒体引擎与信令模块;而在最上层使用红框标记的部分则是API接口。其中第一层与应用相关,根据不同应用场景区分;左侧的Android API则包含传统的RTC通话等。当我们将应用迁移至iOS时所需完成的工作量可以明显减小,仅需要将上层接口换成OC,媒体引擎做一些适就可以了。
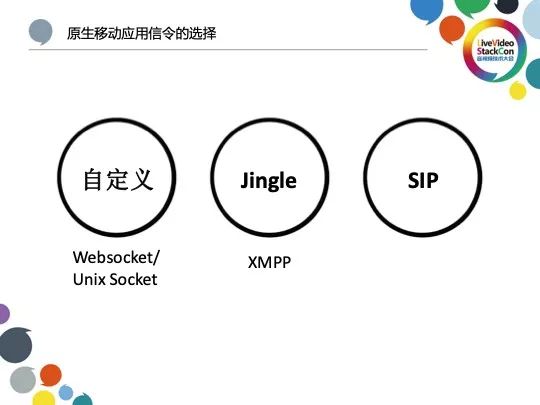
原生移动应用信令的选择是接下来需要我们关注的工作内容。考虑到信令模块的移植性,我们通常会通过以下三种方式完成对原生移动信令的选择:第一种是自定义信令,之所以考虑这种信令是因为WebRTC并没有限制信令的用途,我们只需选择一种合适的信令类型并将足够的信息传递给WebRTC即可,因此Websocket或Unix Socket都是我们考虑的方式;而Jingle也是我们考虑的一种,多用于早期WebRTC版本;SIP是满足传统VoIP设备兼容的不二选择,发展至今也有许多非常成熟的开源解决方案。完成以上集成WebRTC的步骤,一个70分的RTC应用便初步构建完成。
3. 满足现有应用需求
为了让集成的应用初步满足现有需求,接下来我们需要完成的工作是外部音频与视频的采集。

上图展示了外部音频采集的大致流程,其中红色部分为SDK的使用者也就是APP所需完成的工作,黑色部分则是WebRTC的SDK负责的模块,(红框部分则是我们需要重点实现的模块)。外部采集到的音频会首先进入External Audio Device Module流程,随后交由Fine Buffer处理;随后Fine Buffer会将传入的音频流按照10毫秒的粒度传送至Audio Processing Module这一WebRTC的重要模块,其中音频会经过回声消除等处理;经由Audio Processing Module处理完成后的音频数据会被推回至调用者以做音效处理最终被传输至编码器进行编码以为发送至网络做好准备。
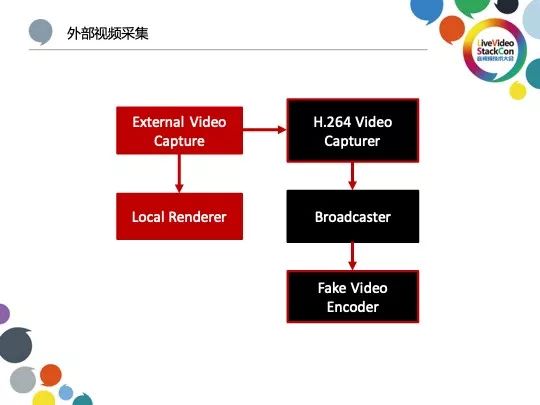
外部视频采集流程与音频有所不同,本地视频的渲染工作交由外部流程完成,采集到的视频流会首先传输至H.264 Video Capturer处理,通过不参与渲染与编码的Broadcaster统计重要信息并通知Fake Video Encoder对来自Broadcaster的视频数据流进行编码处理。
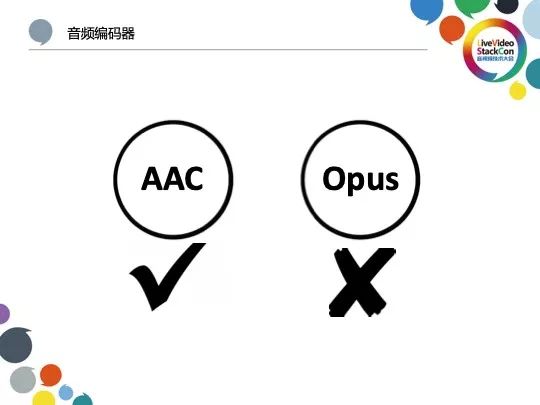
为了确保音频质量符合StarMaker的较高需求,我们选择业界较为优秀的AAC而非Opus作为音频编码器。
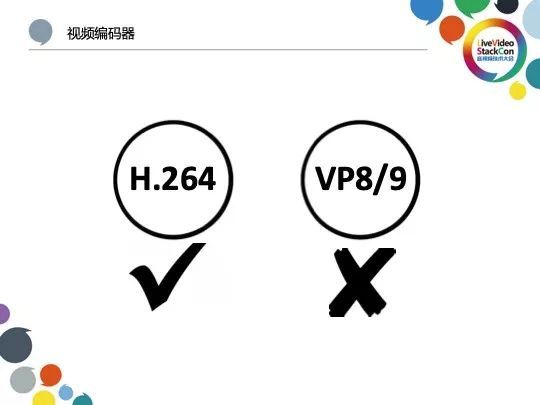
为了更提高兼容性与控制转码负担,我们选择了传统的H.264而非VP8/VP9作为视频编码器。虽然在性能与带宽节省方面H.264不算最优秀的编码方案,考虑到在我们的实际应用场景中有RTMP推流的工作,H.264对整个硬件生态的支持更佳符合我们的需求。
4. 适应网络环境
单纯的满足现有应用需求距离我们的目标还远远不够,适应网络环境尤其如何对抗弱网是摆在我们面前的另一项关键命题。

来自于Facebook的开源工具Augmented Traffic Control是我们选择的一个物美价廉的网络环境模拟方案,其本质为底层基于Linux的一个TC工具,同时提供了非常完善的上下性丢包、带宽限制、坏包、乱序等模拟方式,其简单高效甚至可以像上图右侧那样使用单片机进行部署。
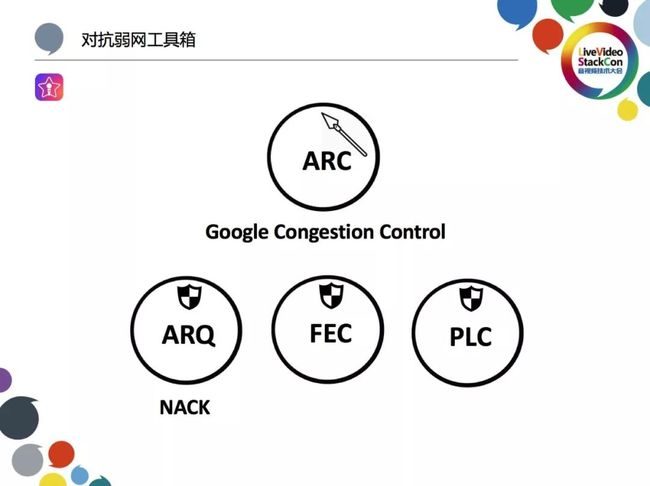
我们使用以下两种类型的工具箱作为对抗弱网的方案:如矛般包含拥塞算法可实现主动攻击的ARC自动码率控制,也被称为GCC或Client Side BWE,主要从客户端进行带宽估计;而如盾般进行被动防御的有ARQ自动重传请求(WebRTC中还有与ARQ类似的选择性重传)、FEC前项编码纠错与PLC丢包补偿。可以看出WebRTC在此方面做出了大量努力,如果存在一款集成以上所有工具的编码器是否会为我们带来较为出色的弱网对抗效果呢?事实也的确如此,如Opus就集成了FEC与PLC。由于视频的带宽资源更多,ARC更多用于视频场景,可调节空间也较为充裕。WebRTC中也集成了针对音频的类似于ARC的模块,其被称为ANA(Audio Network Adaptor),作用主要是对音频码率进行微调,但仅针对Opus。这里需要提醒的是,PLC与ARQ、FEC有所不同,PLC主要通过信号处理的原理人为构造出流畅度较高的音频。
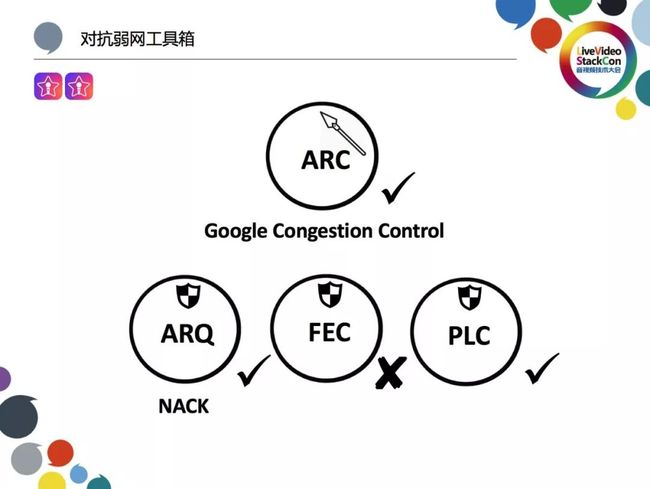
但在实际应用当中我们一开始并没有选择FEC,主要原因如下:
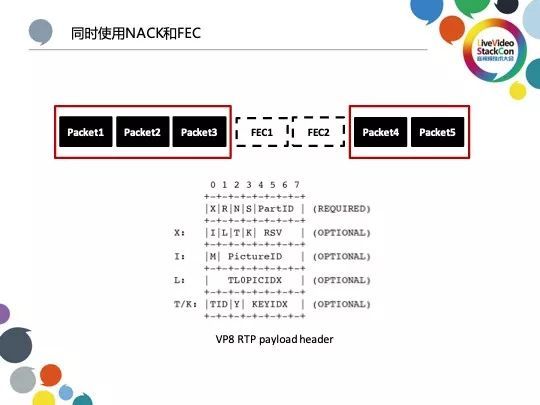
谷歌并不推荐在H.264条件下同时使用FEC与NACK,二者只能选一运用,混合使用FEC与NACK主要针对于VP8、VP9。如上图所示,以上7个Packet中Packet 1~Packet 3为一帧图像而Packet 4~Packet 5则为另外一帧图像,中间的FEC 1与FEC 2两个包则是用于视频恢复的冗余数据。假设FEC 1与FEC 2发生丢失现象即会出现首先我们需要知道的是RTP包中的Sequence Number必须连续,我们才能根据Sequence Number判断哪些包丢失,而H.264即通过此方式判断丢包;当FEC 1与FEC 2丢失之后,H.264会判断丢失一个关键帧或P帧,实际上仅丢失一段冗余信息而已,但此时H.264便会发起丢包重传,这无疑是一种对带宽的浪费。之所以VP8、VP9不存在类似的问题,是因为VP8、VP9具有非常丰富的RTP Payload Header,不仅包括各种的边界检查,也携带了更多的额外信息。其中最重要的便是用于标识包属于哪一帧并正确排序的Picture ID,可在出现FEC 1与FEC 2 丢失情况时侦测到Packet 3之后的Packet 4依旧存在,从而有效避免了不必要的重传操作,这便是我们不选择FEC的一个重要原因。

既然我们在音频与视频都使用了NACK,就需要注意以下几个关键点:首先NACK仅适用于低延迟场景,所经历的RTT时间并不长;如果用于高延迟场景便会出现重传效果不尽如人意的状况,因此面对高延迟场景我们应当有效控制重传频率,极力避免反复重传甚至重传风暴的现象发生。其次,丢包率的统计也易受到影响,RTCP的丢包统计严重依赖所收到包的数量,接收到两个完全一样包的概率可能会增加,其会极大影响丢包率的准确性,也许会造成丢包率数据符合要求而实际丢包控制效果却十分糟糕的情况;加之丢包率会对拥塞控制算法产生影响,一旦相关参数设置对丢包的敏感不够就会令拥塞控制形同虚设。
经过上述优化,获得一个70分的RTC应用便不再成为一件困难的事情。
5. 更上一层楼
当然,70分还远远不够,我们应该给自己设立更高的目标。如何实现出色的RTC应用,便是我们接下来探索的方向。
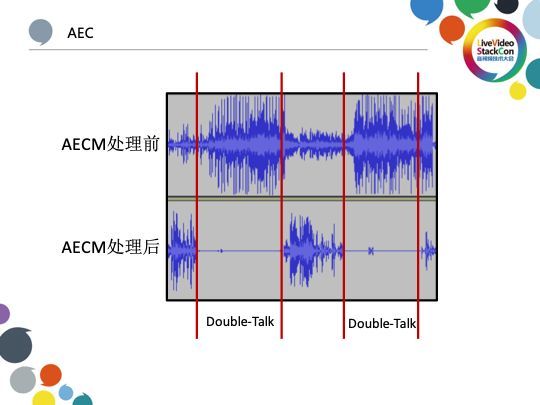
AEC是第一个需要改进的方面,WebRTC会优先选择AEC处理。对于iOS而言其AEC整体性能较为出色,而对Android来说其AEC依旧具备非常大的提升空间,有些Android设备的AEC甚至并没有发挥其应有的效果。由于Android平台的碎片化特征,我们需要尽可能通过集成在软件内部的AEC解决方案实现满足较为一致的处理效果。WebRTC中的AECM处理算法专用于移动端的回声消除,考虑到整个移动端包括CPU在内的硬件整体计算能力,AECM被简化了许多环节,这样带来的副作用便如上图展示的那样,对比AECM处理前后的音频频谱我们可以发现部分音频会被直接删去,这一定不是我们期待的优化结果。因此,我们可以针对以上缺点对AECM优化。
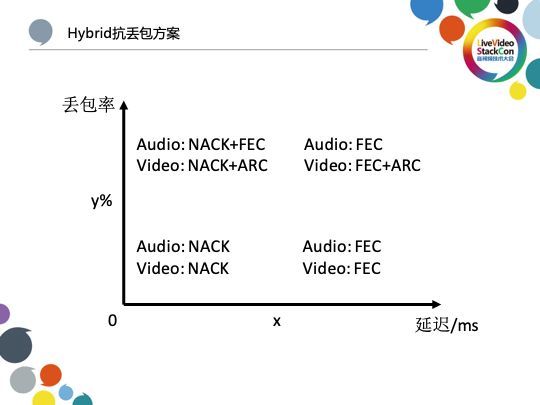
除了AEC,上图展示的那样是一种基于丢包阈值与延迟阈值制定的混合抗丢包解决方案也是一个优化的方向:在高延迟条件下我们尽量采用FEC方案,当延迟低于某一阈值时则采用NACK方案;在高丢包率条件下我们采用ARC处理以实现对编码率的控制,而在低丢包率条件下则不使用ARC。

点击【阅读原文】或扫描图中二维码了解更多LiveVideoStackCon 2019 上海 音视频技术大会 讲师信息。