生产环境flume日志采集方案
Flume简介
Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
支持在日志系统中定制各类数据发送方,用于收集数据;
同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力。
名词介绍:
Flume OG:Flume original generation,即Flume0.9x版本
Flume NG:Flume next generation,即Flume1.x版本
官网:http://flume.apache.orgFlume体系结构
1、Flume有一个简单、灵活的基于流的数据流结构
2、Flume具有故障转移机制和负载均衡机制
3、Flume使用一个简单可扩展的数据模型(source、channel、sink)
目前,flume-ng处理数据有两种方式:avro-client、agent
avro-client:一次性将数据传输到指定的avro服务的客户端
agent:一个持续传输数据的服务
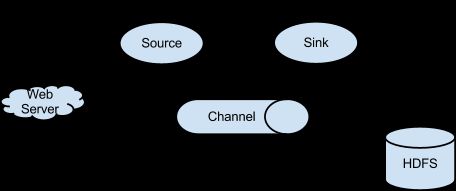
Agent主要的组件包括:Source、Channel、Sink
Source:完成对日志数据的手机,分成transtion和event打入到channel之中。
Channel:主要提供一个队列的功能,对source提供的数据进行简单的缓存。
Sink:取出Channel中的数据,进行相应的存储文件系统,数据库或是提交到远程服务器。
数据在组件传输的单位是Event。Flume基本组件
Source
source意为来源、源头。
主要作用:从外界采集各种类型的数据,将数据传递给Channel。
比如:监控某个文件只要增加数据就立即采集新增的数据、监控某个目录一旦有新文件产生就采集新文件的内容、监控某个端口等等。
常见采集的数据类型:
Exec Source、Avro Source、NetCat Source、Spooling Directory Source等
详细查看:
http://flume.apache.org/FlumeUserGuide.html#flume-sources
或者自带的文档查看。
Source具体作用:
AvroSource:监听一个avro服务端口,采集Avro数据序列化后的数据;
Thrift Source:监听一个Thrift 服务端口,采集Thrift数据序列化后的数据;
Exec Source:基于Unix的command在标准输出上采集数据;
tail -F 和tail -f 区别。基于log4j切割文件时的能否读取问题。
JMS Source:Java消息服务数据源,Java消息服务是一个与具体平台无关的API,这是支持jms规范的数据源采集;
Spooling Directory Source:通过文件夹里的新增的文件作为数据源的采集;
Kafka Source:从kafka服务中采集数据。
NetCat Source: 绑定的端口(tcp、udp),将流经端口的每一个文本行数据作为Event输入
HTTP Source:监听HTTP POST和 GET产生的数据的采集Channel
Channel
一个数据的存储池,中间通道。
主要作用
接受source传出的数据,向sink指定的目的地传输。Channel中的数据直到进入到下一个channel中或者进入终端才会被删除。当sink写入失败后,可以自动重写,不会造成数据丢失,因此很可靠。
channel的类型很多比如:内存中、jdbc数据源中、文件形式存储等。
常见采集的数据类型:
Memory Channel
File Channel
Spillable Memory Channel等
详细查看:
http://flume.apache.org/FlumeUserGuide.html#flume-channels
Channel具体作用:
Memory Channel:使用内存作为数据的存储。速度快
File Channel:使用文件来作为数据的存储。安全可靠
Spillable Memory Channel:使用内存和文件作为数据的存储,即:先存在内存中,如果内存中数据达到阀值则flush到文件中。
JDBC Channel:使用jdbc数据源来作为数据的存储。
Kafka Channel:使用kafka服务来作为数据的存储。Sink
Sink:数据的最终的目的地。
主要作用:接受channel写入的数据以指定的形式表现出来(或存储或展示)。
sink的表现形式很多比如:打印到控制台、hdfs上、avro服务中、文件中等。
常见采集的数据类型:
HDFS Sink
Hive Sink
Logger Sink
Avro Sink
Thrift Sink
File Roll Sink
HBaseSink
Kafka Sink等
详细查看:
http://flume.apache.org/FlumeUserGuide.html#flume-sinks
HDFSSink需要有hdfs的配置文件和类库。一般采取多个sink汇聚到一台采集机器负责推送到hdfs。
Sink具体作用:
Logger Sink:将数据作为日志处理(根据flume中的设置的日志的级别显示)。
HDFS Sink:将数据传输到hdfs集群中。
Avro Sink:数据被转换成Avro Event,然后发送到指定的服务端口上。
Thrift Sink:数据被转换成Thrift Event,然后发送到指定的的服务端口上。
File Roll Sink:数据传输到本地文件中。
Hive Sink:将数据传输到hive的表中。
IRC Sink:数据向指定的IRC服务和端口中发送。
Null Sink:取消数据的传输,即不发送到任何目的地。
HBaseSink:将数据发往hbase数据库中。
MorphlineSolrSink:数据发送到Solr搜索服务器(集群)。
ElasticSearchSink:数据发送到Elastic Search搜索服务器(集群)。
Kafka Sink:将数据发送到kafka服务中。(注意依赖类库)Event
event是Flume NG传输的数据的基本单位,也是事务的基本单位。
在文本文件,通常是一行记录就是一个event。
网络消息传输系统中,一条消息就是一个event。
event里有header、body
Event里面的header类型:Map
我们可以在source中自定义header的key:value,在某些channel和sink中使用header。
练习1:
一个需求:怎么实时监听一个文件的数据增加呢?打印到控制台上。
如果这个文件增加的量特别大呢? Avro client
avro客户端:
往指定接收方相应的主机名:端口 发送本机要监听发送的源文件或者文件夹。
bin/flume-ng avro-client --conf conf/ -H master -p 41414 -F /opt/logs/access.log
需要提供 avro-source
注意:--headerFile选项:追加header信息,文件以空格隔开。
bin/flume-ng avro-client --conf conf/ --host slave01 --port 41414 --filename /opt/logs/access.log --headerFile /opt/logs/kv.log
如果指定了--dirname。则传输后此文件夹里的文件会加上fileSuffix后缀。
练习02:
监控文件的新增内容向另一台机器的source发送数据。怎么处理?Flume安装
系统要求:
1、JRE:JDK1.6+(推荐使用1.7)
2、内存:没有上限和下限,能够配置满足source、channel以及sink即可
3、磁盘空间:同2
4、目录权限:一般的agent操作的目录必须要有读写权限
这里采用的Flume版本为1.8.0,也是目前最新的版本,下载地址为:
http://archive.apache.org/dist/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz
安装步骤:
解压缩:[uplooking@uplooking01 ~]$ tar -zxvf soft/apache-flume-1.8.0-bin.tar.gz -C app/
重命名:[uplooking@uplooking01 ~]$ mv app/apache-flume-1.8.0-bin/ app/flume
添加到环境变量中
vim ~/.bash_profile
export FLUME_HOME=/home/uplooking/app/flume
export PATH=$PATH:$FLUME_HOME/bin
修改配置文件
conf]# cp flume-env.sh.template flume-env.sh
添加JAVA_HOME
export JAVA_HOME=/opt/jdkFlume Agent案例
侦听网络端口数据
定义flume agent配置文件:
#####################################################################
## this's flume log purpose is listenning a socket port which product
## data of stream
## this agent is consists of source which is r1 , sinks which is k1,
## channel which is c1
##
## 这里面的a1 是flume一个实例agent的名字
#####################################################################
#定义了当前agent的名字叫做a1
a1.sources = r1 ##定了该agent中的sources组件叫做r1
a1.sinks = k1 ##定了该agent中的sinks组件叫做k1
a1.channels = c1 ##定了该agent中的channels组件叫做c1
# 监听数据源的方式,这里采用监听网络端口
a1.sources.r1.type = netcat #source的类型为网络字节流
a1.sources.r1.bind = uplooking01 #source监听的网络的hostname
a1.sources.r1.port = 52019 #source监听的网络的port
# 采集的数据的下沉(落地)方式 通过日志
a1.sinks.k1.type = logger #sink的类型为logger日志方式,log4j的级别有INFO、Console、file。。。
# 描述channel的部分,使用内存做数据的临时存储
a1.channels.c1.type = memory #channel的类型使用内存进行数据缓存,这是最常见的一种channel
a1.channels.c1.capacity = 1000 #定义了channel对的容量
a1.channels.c1.transactionCapacity = 100 #定义channel的最大的事务容量
# 使用channel将source和sink连接起来
# 需要将source和sink使用channel连接起来,组成一个类似流水管道
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动flume agent:
flume-ng agent -c conf -n a1 -f conf/flume-nc.conf -Dflume.root.logger=INFO,console
-c conf:使用配置文件的方式
-n a1:指定agent的名称为a1
-f:指定配置文件
因为数据落地是通过日志,所以后面需要指定日志的相关配置选项。通过telnet或者nc向端口发送数据
安装telnet或nc:
yum isntall -y telent
yum install -y nc向端口发送数据:
# 使用telnet
[uplooking@uplooking01 ~]$ telnet uplooking01 52019
Trying 192.168.43.101...
Connected to uplooking01.
Escape character is '^]'.
wo ai ni
OK
sai bei de xue
OK
# 使用nc
[uplooking@uplooking01 ~]$ nc uplooking01 52019
heihei
OK
xpleaf
OK此时可以查看flume agent启动终端的输出:
2018-03-24 20:09:34,390 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/192.168.43.101:52019]
2018-03-24 20:10:13,022 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 77 6F 20 61 69 20 6E 69 0D wo ai ni. }
2018-03-24 20:10:24,139 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 73 61 69 20 62 65 69 20 64 65 20 78 75 65 0D sai bei de xue. }
2018-03-24 20:13:26,190 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 69 68 65 69 heihei }
2018-03-24 20:13:26,463 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 78 70 6C 65 61 66 xpleaf }
2018-03-24 20:17:01,694 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F hello }侦听目录中的新增文件
配置文件如下:
#####################################################################
## 监听目录中的新增文件
## this agent is consists of source which is r1 , sinks which is k1,
## channel which is c1
##
## 这里面的a1 是flume一个实例agent的名字
#####################################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 监听数据源的方式,这里采用监听目录中的新增文件
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/uplooking/data/flume
a1.sources.r1.fileSuffix = .ok
# a1.sources.r1.deletePolicy = immediate
a1.sources.r1.deletePolicy = never
a1.sources.r1.fileHeader = true
# 采集的数据的下沉(落地)方式 通过日志
a1.sinks.k1.type = logger
# 描述channel的部分,使用内存做数据的临时存储
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 使用channel将source和sink连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动flume agent:
flume-ng agent -c conf -n a1 -f conf/flume-dir.conf -Dflume.root.logger=INFO,console在监听目录下新增文件,内容如下:
hello you
hello he
hello me可以看到flume agent终端输出:
2018-03-24 21:23:59,182 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{file=/home/uplooking/data/flume/hello.txt} body: 68 65 6C 6C 6F 20 79 6F 75 hello you }
2018-03-24 21:23:59,182 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{file=/home/uplooking/data/flume/hello.txt} body: 68 65 6C 6C 6F 20 68 65 hello he }
2018-03-24 21:23:59,182 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{file=/home/uplooking/data/flume/hello.txt} body: 68 65 6C 6C 6F 20 6D 65 hello me }
2018-03-24 21:23:59,184 (pool-3-thread-1) [INFO - org.apache.flume.client.avro.ReliableSpoolingFileEventReader.readEvents(ReliableSpoolingFileEventReader.java:324)] Last read took us just up to a file boundary. Rolling to the next file, if there is one.
2018-03-24 21:23:59,184 (pool-3-thread-1) [INFO - org.apache.flume.client.avro.ReliableSpoolingFileEventReader.rollCurrentFile(ReliableSpoolingFileEventReader.java:433)] Preparing to move file /home/uplooking/data/flume/hello.txt to /home/uplooking/data/flume/hello.txt.ok可以看到提示说,原来的文本文件已经被重命名为.ok,查看数据目录中的文件:
[uplooking@uplooking01 flume]$ ls
hello.txt.ok监听文件中的新增数据
tail -f与tail -F的说明:
在生产环境中,为了防止日志文件过大,通常会每天生成一个新的日志文件,
这是通过重命名原来的日志文件,然后touch一个原来的日志文件的方式来实现的。
http-xxx.log
http-xxx.log.2017-03-15
http-xxx.log.2017-03-16
-f不会监听分割之后的文件,而-F则会继续监听。配置文件:
#####################################################################
## 监听文件中的新增数据
##
## this agent is consists of source which is r1 , sinks which is k1,
## channel which is c1
##
## 这里面的a1 是flume一个实例agent的名字
#####################################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 监听数据源的方式,这里监听文件中的新增数据
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/uplooking/data/flume/http-flume.log
# 采集的数据的下沉(落地)方式 通过日志
a1.sinks.k1.type = logger
# 描述channel的部分,使用内存做数据的临时存储
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000000
a1.channels.c1.transactionCapacity = 1000000
# 使用channel将source和sink连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动flume agent:
flume-ng agent -c conf -n a1 -f conf/flume-data.conf -Dflume.root.logger=INFO,console向监听文件中添加数据:
cat hello.txt.ok > http-flume.log 查看flume agent终端的输出:
2018-03-25 01:28:39,359 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 79 6F 75 hello you }
2018-03-25 01:28:40,465 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 68 65 hello he }
2018-03-25 01:28:40,465 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 6D 65 hello me }数据过大导致的内存溢出问题与解决方案
使用jps -v命令可以查看启动flume时,分配的内存大小:
20837 Application -Xmx20m -Dflume.root.logger=INFO,console -Djava.library.path=:/home/uplooking/app/hadoop/lib/native:/home/uplooking/app/hadoop/lib/native可以看到分配的最大内存为20M,因为我们使用的是将channel中的数据保存到内存中,所以一旦监听的文本数据过大,就会造成内存溢出,先使用下面的脚本生成一个比较大的文本数据:
for i in `seq 1 10000000`
do
echo "${i}.I like bigdata, I would like to do something with bigdata." >> /home/uplooking/data/mr/bigData.log
done然后向监听的日志中打数据:
cat bigData.log > ../flume/http-flume.log 这时可以在flume agent终端中看到异常:
Exception in thread "SinkRunner-PollingRunner-DefaultSinkProcessor" java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.util.Arrays.copyOfRange(Arrays.java:3664)
at java.lang.String.<init>(String.java:207)
at java.lang.StringBuilder.toString(StringBuilder.java:407)
at sun.net.www.protocol.jar.Handler.parseContextSpec(Handler.java:207)
at sun.net.www.protocol.jar.Handler.parseURL(Handler.java:153)
at java.net.URL.<init>(URL.java:622)
at java.net.URL.<init>(URL.java:490)
Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "SinkRunner-PollingRunner-DefaultSinkProcessor"解决方案:
通过调整
# 描述channel的部分,使用内存做数据的临时存储
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000000
a1.channels.c1.transactionCapacity = 1000000
执行案例监听日志文件中的新增记录,操作一下异常
java.lang.OutOfMemoryError: GC overhead limit exceeded,简称OOM/OOME
两种方案解决:
第一种方案:给该flume程序加大内存存储容量
默认值为-Xmx20m(最大堆内存大小),--->-Xmx 2000m
-Xms10m(初始堆内存大小)
flume-ng agent -Xms1000m -Xmx1000m -c conf -n a1 -f conf/flume-data.conf -Dflume.root.logger=INFO,console
第二种方案:第一种搞不定的时候,比如机器可用内存不够的话的,使用其它channel解决
比如磁盘文件,比如jdbc如果文本数据不是特别大,那么用第一种方案也是可以解决的,但是一旦文本数据过大,第一种方案需要分配很大的内存空间,所以下面演示使用第二种方案。
配置文件如下:
#####################################################################
## 监听文件中的新增数据
## 使用文件做为channel
##
## this agent is consists of source which is r1 , sinks which is k1,
## channel which is c1
##
## 这里面的a1 是flume一个实例agent的名字
#####################################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 监听数据源的方式,这里监听文件中的新增数据
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/uplooking/data/flume/http-flume.log
# 采集的数据的下沉(落地)方式 通过日志
a1.sinks.k1.type = logger
# 描述channel的部分,使用内存做数据的临时存储
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/uplooking/data/flume/checkpoint
a1.channels.c1.transactionCapacity = 1000000
a1.channels.c1.dataDirs = /home/uplooking/data/flume/data
# 使用channel将source和sink连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1注意需要创建下面两个目录:
/home/uplooking/data/flume/checkpoint # 存放检查点数据
/home/uplooking/data/flume/data # 存放channel的数据这样再向监听文件中打数据,会在终端中看到不停地刷数据。
flume数据下沉之hdfs目录
可以将channel中的数据最终保存到hdfs中,配置文件如下:
#####################################################################
## 监听文件中的新增数据
## 使用文件做为channel
## this agent is consists of source which is r1 , sinks which is k1,
## channel which is c1
##
## 这里面的a1 是flume一个实例agent的名字
#####################################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 监听数据源的方式,这里采用监听网络端口
a1.sources.r1.type = netcat
a1.sources.r1.bind = uplooking01
a1.sources.r1.port = 52019
# 采集的数据的下沉(落地)方式 存储到hdfs的某一路径
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://ns1/input/flume/%Y/%m/%d
# 文件生成后的前缀
a1.sinks.k1.hdfs.filePrefix = http
# 文件生成后的后缀,如http.1521927418991.log
a1.sinks.k1.hdfs.fileSuffix = .log
# 文件使用时的前缀
a1.sinks.k1.hdfs.inUsePrefix = xttzm.
# 文件使用时的后缀,如xttzm.http.1521927418992.log.zdhm
a1.sinks.k1.hdfs.inUseSuffix = .zdhm
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 默认为SequenceFile,查看hdfs上的文件时为序列化的
a1.sinks.k1.hdfs.fileType = DataStream
# 上面的要配置,这个也要配置,写入的数据格式为文本内容
a1.sinks.k1.hdfs.writeFormat = Text
# 下面这个配置选项不加,那么rollInterval rollSize rollCount是不会生效的
a1.sinks.k1.hdfs.minBlockReplicas = 1
# 描述channel的部分,使用文件做数据的临时存储
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/uplooking/data/flume/checkpoint
a1.channels.c1.transactionCapacity = 1000000
a1.channels.c1.dataDirs = /home/uplooking/data/flume/data
# 使用channel将source和sink连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动flume agent:
flume-ng agent -c conf -n a1 -f conf/flume-hdfs-sink.conf -Dflume.root.logger=INFO,console通过nc发送数据:
$ nc uplooking01 52019
1
OK
2
OK
3
OK
......
12
OK
13
OK
14
OK
15
OK
16
OK这样,在hdfs目录下会生成三个正式文件,同时还应该有一个临时文件:
$ hdfs dfs -ls /input/flume/2018/03/25/
Found 4 items
-rw-r--r-- 3 uplooking supergroup 10 2018-03-25 06:00 /input/flume/2018/03/25/http.1521928799720.log
-rw-r--r-- 3 uplooking supergroup 11 2018-03-25 06:00 /input/flume/2018/03/25/http.1521928799721.log
-rw-r--r-- 3 uplooking supergroup 15 2018-03-25 06:00 /input/flume/2018/03/25/http.1521928799722.log
-rw-r--r-- 3 uplooking supergroup 3 2018-03-25 06:00 /input/flume/2018/03/25/xttzm.http.152192879