python 绘制三国演义人物关系图
"""
author:魏振东
data:2019.12.18
func:绘制三国演义人物关系图
"""
import codecs
import jieba.posseg as pseg
import xlwt
def excel_write(names,workbook):
# 创建一个worksheet
worksheet = workbook.add_sheet('node')
worksheet.write(0, 0, label='ID')
worksheet.write(0, 1, label='Label')
worksheet.write(0, 2, label='Weight')
i=1
for name, times in names.items():
if times > 10:
worksheet.write(i, 0, label=str(name))
worksheet.write(i, 1, label=str(name))
worksheet.write(i, 2, label=str(times))
i = i+1
# 创建一个worksheet
worksheet1 = workbook.add_sheet('edge')
worksheet1.write(0, 0, label='Source')
worksheet1.write(0, 1, label='Target')
worksheet1.write(0, 2, label='Weight')
i=1
for name, edges in relationships.items():
for v, w in edges.items():
if w > 10:
worksheet1.write(i, 0, label=name)
worksheet1.write(i, 1, label=v)
worksheet1.write(i, 2, label=str(w))
i = i+1
workbook.save('People_node.xls')
names = {}# 保存人物,键为人物名称,值为该人物在全文中出现的次数
relationships = {}#保存人物关系的有向边,键为有向边的起点,值为一个字典 edge ,edge 的键为有向边的终点,值是有向边的权值
lineNames = []# 缓存变量,保存对每一段分词得到当前段中出现的人物名称
excludes = {'将军', '却说', '令人', '赶来', '徐州', '不见', '下马', '喊声', '因此', '未知', '大败', '百姓', '大事', '一军', '之后', '接应', '起兵',
'成都', '原来', '江东', '正是', '忽然', '原来', '大叫', '上马', '天子', '一面', '太守', '不如', '忽报', '后人', '背后', '先主', '此人',
'城中', '然后', '大军', '何不', '先生', '何故', '夫人', '不如', '先锋', '二人', '不可', '如何', '荆州', '不能', '如此', '主公', '军士',
'商议', '引兵', '次日', '大喜', '魏兵', '军马', '于是', '东吴', '今日', '左右', '天下', '不敢', '陛下', '人马', '不知', '都督', '汉中',
'一人', '众将', '后主', '只见', '蜀兵','马军','黄巾','立功','白发','大吉','红旗','士卒','钱粮','于汉','郎舅', '龙凤', '古之', '白虎',
'古人云', '尔乃', '马飞报', '轩昂', '史官', '侍臣', '列阵','玉玺','车驾','老夫','伏兵','都尉','侍中','西凉','安民','张曰','文武','白旗',
'祖宗','寻思'} # 排除的词汇
with codecs.open("111111.txt",'r',encoding='utf-8',errors='ignore') as f:
for line in f.readlines():
poss = pseg.cut(line) # 分词,返回词性
lineNames.append([]) # 为本段增加一个人物列表
for w in poss:
if w.flag != 'nr' or len(w.word) < 2 or w.word in excludes:
continue # 当分词长度小于2或该词词性不为nr(人名)时认为该词不为人名
elif w.word == '孔明' or w.word == '孔明曰' or w.word == '卧龙先生':
real_word = '诸葛亮'
elif w.word == '云长' or w.word == '关公曰' or w.word == '关公':
real_word = '关羽'
elif w.word == '玄德' or w.word == '玄德曰' or w.word == '玄德甚' or w.word == '玄德遂' or w.word == '玄德兵' or w.word == '玄德领' \
or w.word == '玄德同' or w.word == '刘豫州' or w.word == '刘玄德':
real_word = '刘备'
elif w.word == '孟德' or w.word == '丞相' or w.word == '曹贼' or w.word == '阿瞒' or w.word == '曹丞相' or w.word == '曹将军':
real_word = '曹操'
elif w.word == '高祖':
real_word = '刘邦'
elif w.word == '光武':
real_word = '刘秀'
elif w.word == '桓帝':
real_word = '刘志'
elif w.word == '灵帝':
real_word = '刘宏'
elif w.word == '公瑾':
real_word = '周瑜'
elif w.word == '伯符':
real_word = '孙策'
elif w.word == '吕奉先' or w.word == '布乃' or w.word == '布大怒' or w.word == '吕布之':
real_word = '吕布'
elif w.word == '赵子龙' or w.word == '子龙':
real_word = '赵云'
elif w.word == '卓大喜' or w.word == '卓大怒':
real_word = '董卓'
else:
real_word = w.word
lineNames[-1].append(real_word) # 为当前段的环境增加一个人物
if names.get(real_word) is None: # 如果某人物(w.word)不在人物字典中
names[real_word] = 0
relationships[real_word] = {}
names[real_word] += 1
# 输出人物出现次数统计结果
# for name, times in names.items():
# print(name, times)
# 对于 lineNames 中每一行,我们为该行中出现的所有人物两两相连。如果两个人物之间尚未有边建立,则将新建的边权值设为 1,
# 否则将已存在的边的权值加 1。这种方法将产生很多的冗余边,这些冗余边将在最后处理。
for line in lineNames:
for name1 in line:
for name2 in line:
if name1 == name2:
continue
if relationships[name1].get(name2) is None:
relationships[name1][name2] = 1
else:
relationships[name1][name2] = relationships[name1][name2] + 1
# 由于分词的不准确会出现很多不是人名的“人名”,从而导致出现很多冗余边,
# 为此可设置阈值为10,即当边出现10次以上则认为不是冗余
# 创建一个workbook 设置编码
workbook = xlwt.Workbook(encoding = 'utf-8')
# 数据存储
excel_write(names,workbook)


基础数据获取完毕!
下面利用Gephi进行可视化操作下载地址:https://gephi.org/users/download/
具体操作见大佬博客








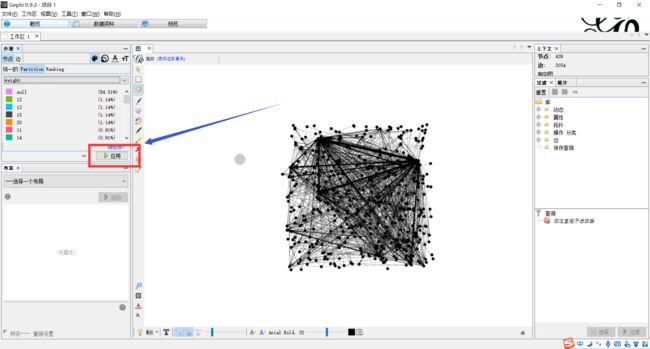

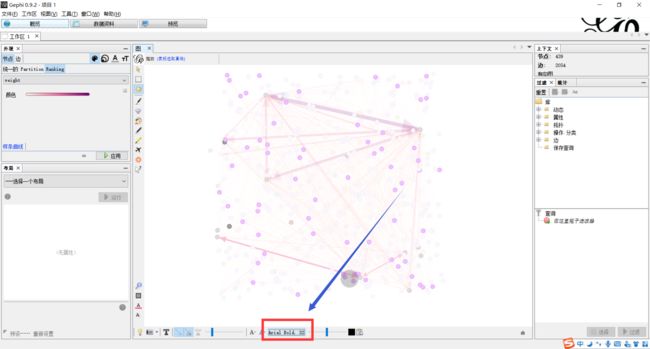




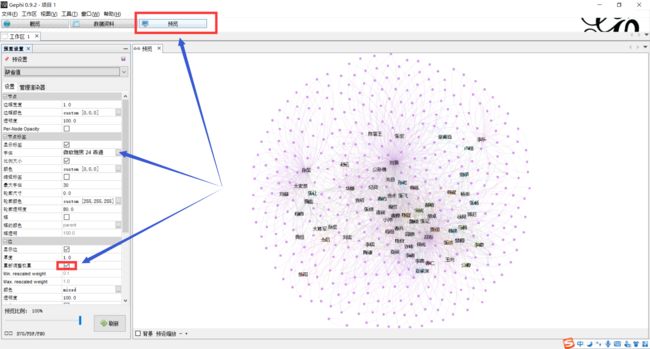
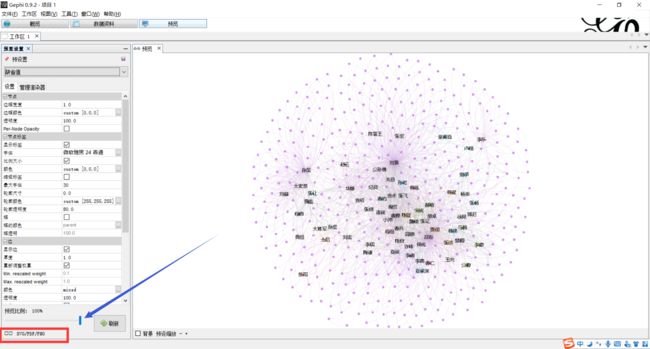
gephi操作指南