pytorch深度学习框架--gpu和cpu的选择
pytorch深度学习框架–gpu和cpu的选择
基于pytorch框架,最近实现了一个简单的手写数字识别的程序,我安装的pytorch是gpu版(你也可以安装cpu版本的,根据个人需要),这里我介绍pytorch的gpu版本和cpu版本的安装以及训练手写数字识别时gpu和cpu之间的切换。
1、pytorch的安装
1.1 pytorch(带有gpu)安装
首先进入pytorch官网,选择自己所需要的版本,这里我选择的版本如下图所示。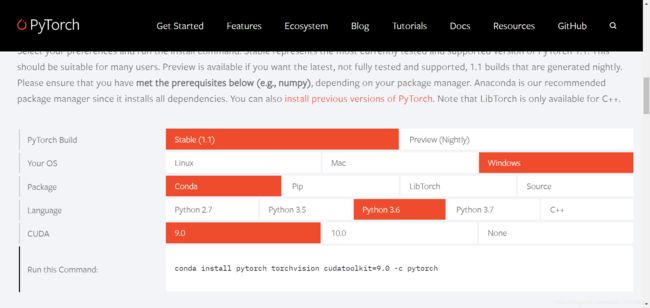
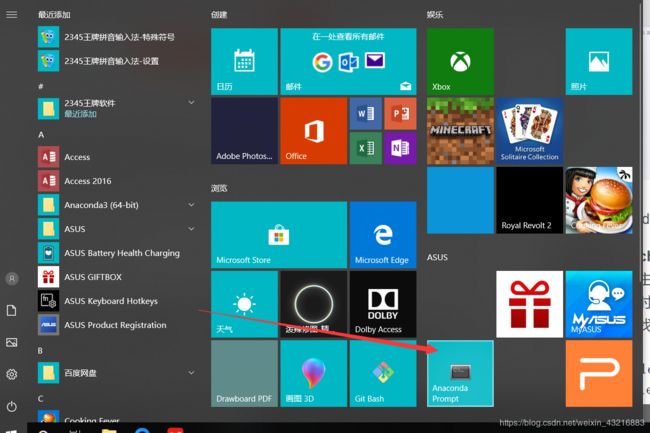
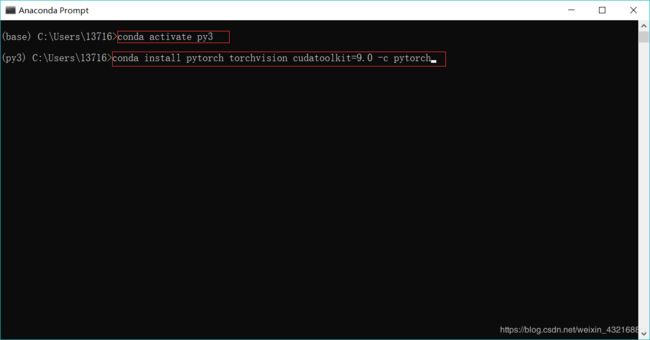
然后打开anaconda Prompt,首先输入:conda activate py3激活py3(解释一下为什么是py3,因为我之前装的是python3.6,创建的名字为py3),然后输入:conda install pytorch torchvision cudatoolkit=9.0 -c pytorch安装pytorch,等待安装就好,如下图所示。
1.2 pytorch(无gpu)安装
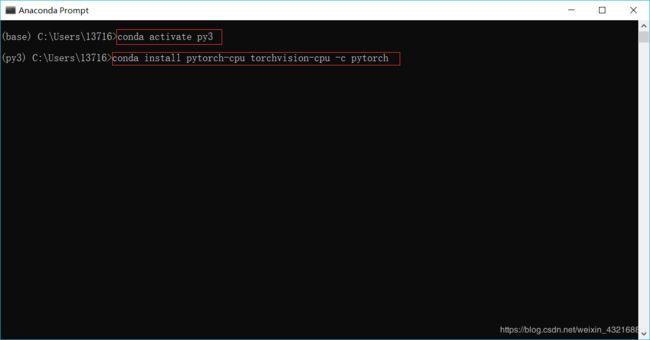
这时CUDA选择none即可

打开anaconda终端,首先激活py3,然后输入这个命令:conda install pytorch-cpu torchvision-cpu -c pytorch,等待安装就好,如下图所示,
1.3 测试是否安装成功
首先cmd打开终端,输入python即可查看当前安装的python的版本,然后import torch 等待几秒出现如下图所示,这样就成功安装了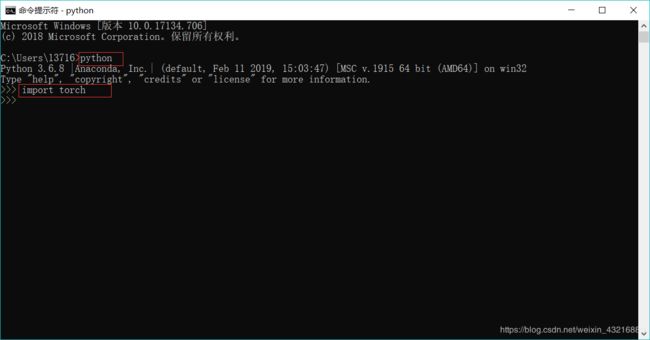
2、选择cpu进行网络的训练(推荐下载带有gpu的)
2.1新建一个model.py模块
from torch import nn
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 使用序列工具快速构建
self.conv1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, padding=2), # 2?
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2))
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc = nn.Linear(7 * 7 * 32, 10) # ?
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = out.view(out.size(0), -1) # reshape
out = self.fc(out)
return out
2.2 新建一个train.py模块(使用cpu训练的)
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
from torchvision import datasets, transforms
from torch.autograd import Variable
import os
batch_size = 64
learning_rate = 0.001
# 将数据处理成Variable, 如果有GPU, 可以转成cuda形式
def get_variable(x):
x = Variable(x)
return x.cpu() if torch.cuda.is_available() else x
train_dataset = datasets.MNIST(
root='./mnist/',
train=True,
transform=transforms.ToTensor(),
download=True)
transforms = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
images, labels = next(iter(train_loader))
img = torchvision.utils.make_grid(images)
img = img.numpy().transpose(1, 2, 0)
print(labels)
plt.imshow(img)
plt.show()
# 两层卷积
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 使用序列工具快速构建
self.conv1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2))
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc = nn.Linear(7 * 7 * 32, 10) # ?
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = out.view(out.size(0), -1) # reshape
out = self.fc(out)
return out
cnn = CNN()
if torch.cuda.is_available():
cnn = cnn.cpu()
# 选择损失函数和优化方法
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(cnn.parameters(), lr=learning_rate)
print(cnn)
num_epochs = 2
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = get_variable(images)
labels = get_variable(labels) ##?
outputs = cnn(images)
optimizer.zero_grad() ##
loss = loss_func(outputs, labels)
loss.backward() # 反向传播,自动计算每个节点的锑度至
optimizer.step()
if (i + 1) % 100 == 0:
print('Epoch [%d/%d], Iter [%d/%d] Loss: %.4f'
% (epoch + 1, num_epochs, i + 1, len(train_dataset) // batch_size, loss.item()))
torch.save(cnn.state_dict(), 'cnn.pkl')
2.3 新建一个test.py模块
import torch
import torchvision
import matplotlib.pyplot as plt
import torchvision.datasets as normal_datasets
import torchvision.transforms as transforms
from torch.autograd import Variable
from mymodel import CNN
# 见数据加载器和batch
test_dataset = normal_datasets.MNIST(root='./mnist/',
train=False,
transform=transforms.ToTensor())
data_loader_test=torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=4,
shuffle=True)
model = CNN()
model.load_state_dict(torch.load('cnn.pkl'))
X_test, y_test = next(iter(data_loader_test))
inputs = Variable(X_test)
pred = model(inputs)
_, pred = torch.max(pred, 1)
print("Predict Label is:", [i for i in pred.data])
print("Real Label is :", [i for i in y_test])
img = torchvision.utils.make_grid(X_test)
img = img.numpy().transpose(1, 2, 0)
plt.imshow(img)
plt.show()
3、选择gpu进行网络的训练
3.1 model.py模块不变,可以参考以上2.1
3.2 train.py模块(gpu训练)代码如下,可以对比以上2.2
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
from torchvision import datasets, transforms
from torch.autograd import Variable
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
batch_size = 64
learning_rate = 0.001
# 将数据处理成Variable, 如果有GPU, 可以转成cuda形式
def get_variable(x):
x = Variable(x)
return x.cuda() if torch.cuda.is_available() else x
# return nn.DataParallel(x, device_ids=[0])if torch.cuda.device_count() > 1 else x
#如果有多个gpu时可以选择上面的语句,例如上面写的时设备0
train_dataset = datasets.MNIST(
root='./mnist/',
train=True,
transform=transforms.ToTensor(),
download=True)
transforms = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
images, labels = next(iter(train_loader))
img = torchvision.utils.make_grid(images)
img = img.numpy().transpose(1, 2, 0)
print(labels)
plt.imshow(img)
plt.show()
# 两层卷积
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 使用序列工具快速构建
self.conv1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2))
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc = nn.Linear(7 * 7 * 32, 10)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = out.view(out.size(0), -1) # reshape
out = self.fc(out)
return out
cnn = CNN()
if torch.cuda.is_available():
cnn = cnn.cuda()
# if torch.cuda.device_count() > 1:
# cnn = nn.DataParallel(cnn, device_ids=[0])
#如果多个gpu时,需要修改如上
# 选择损失函数和优化方法
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(cnn.parameters(), lr=learning_rate)
print(cnn)
num_epochs = 2
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = get_variable(images)
labels = get_variable(labels)
# print(labels)
outputs = cnn(images)
optimizer.zero_grad()
loss = loss_func(outputs, labels)
loss.backward() # 反向传播,自动计算每个节点的锑度至
optimizer.step()
if (i + 1) % 100 == 0:
print('Epoch [%d/%d], Iter [%d/%d] Loss: %.4f'
% (epoch + 1, num_epochs, i + 1, len(train_dataset) // batch_size, loss.item()))
torch.save(cnn.state_dict(), 'cnn.pkl')
3.3 test.py模块不变,可以参考以上2.3
4、最后附上测试结果
