python环境下利用opencv进行数字识别(模板匹配)
0.前言
昨天在CSDN上看到了一个用C++实现的字符数字识别,就照着他的方法写了一个关于python的数字识别。这次主要分为两大部分,分别为字符分割和模板匹配,下面直接看主内容吧。
1.字符分割
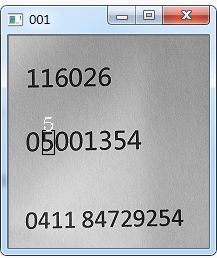
字符分割我主要是用下面的这张照片先进行将上面的数字分割,设计道德方法用水平像素分布和垂直像素分布
1.1图片的获取

我们使用的图片就是上图
1.2图片的水平分割

分割后为以上三张照片
分割的步骤为二值化=》计算水平方向的黑色点数=》根据黑色点数分布进行图片分割
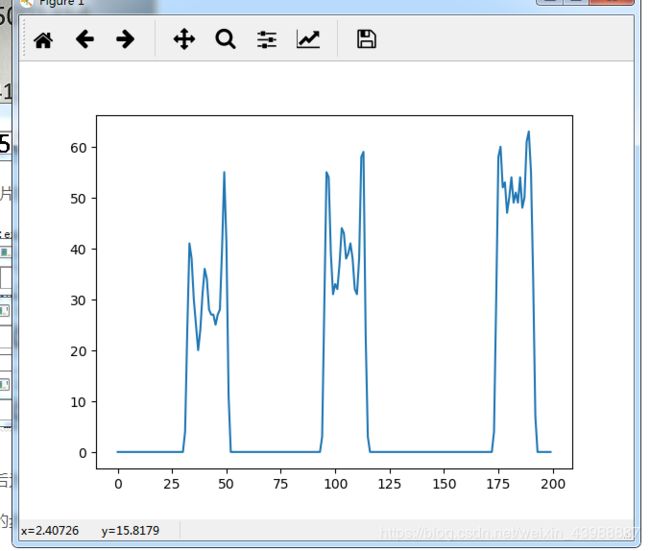
下面直接看代码
#对图片进行水平分割,返回的是分割好的照片数组
def horizontalCut(img):
(x,y)=img.shape #返回的分别是矩阵的行数和列数,x是行数,y是列数
pointCount=np.zeros(y,dtype=np.uint8)#每行黑色的个数
x_axes=np.arange(0,y)
for i in range(0,x):
for j in range(0,y):
if(img[i,j]==0):
pointCount[i]=pointCount[i]+1
plt.plot(x_axes,pointCount)
start=[]#开始索引数组
end=[]#结束索引数组
#对照片进行分割
for index in range(1,y):
#上个为0当前不为0,即为开始
if((pointCount[index]!=0)&(pointCount[index-1]==0)):
start.append(index)
#上个不为0当前为0,即为结束
elif((pointCount[index]==0)&(pointCount[index-1]!=0)):
end.append(index)
img1=img[start[0]:end[0],:]
img2=img[start[1]:end[1],:]
img3=img[start[2]:end[2],:]
imgArr=[img1,img2,img3]
for m in range(3):
cv2.imshow(str(m),imgArr[m])
cv2.waitKey()
plt.show()
return imgArr1.3照片的垂直分割

上图为切割后的照片
主要步骤为:求出图片垂直方向黑色点数=》进行图片切割
# 对图片进行垂直分割,传入的是二值图
def verticalCut(img,img_num):
(x,y)=img.shape #返回的分别是矩阵的行数和列数,x是行数,y是列数
pointCount=np.zeros(y,dtype=np.float32)#每列黑色的个数
x_axes=np.arange(0,y)
#i是列数,j是行数
tempimg=img.copy()
for i in range(0,y):
for j in range(0,x):
# if j<15:
if(tempimg[j,i]==0):
pointCount[i]=pointCount[i]+1
figure=plt.figure(str(img_num))
plt.plot(x_axes,pointCount)
start = []
end = []
# 对照片进行分割
print(pointCount)
for index in range(1, y-1):
# 上个为0当前不为0,即为开始
if ((pointCount[index-1] == 0) & (pointCount[index] != 0)):
start.append(index)
# 上个不为0当前为0,即为结束
elif ((pointCount[index] != 0) & (pointCount[index +1] == 0)):
end.append(index)
imgArr=[]
for idx in range(0,len(start)):
tempimg=img[ :,start[idx]:end[idx]]
cv2.imshow(str(img_num)+"_"+str(idx), tempimg)
cv2.imwrite(img_num+'_'+str(idx)+'.jpg',tempimg)
imgArr.append(tempimg)
return imgArr2.模板匹配
模板匹配的工作方式
模板匹配的工作方式跟直方图的反向投影基本一样,大致过程是这样的:通过在输入图像上滑动图像块对实际的图像块和输入图像进行匹配。
假设我们有一张100x100的输入图像,有一张10x10的模板图像,查找的过程是这样的:
(1)从输入图像的左上角(0,0)开始,切割一块(0,0)至(10,10)的临时图像;
(2)用临时图像和模板图像进行对比,对比结果记为c;
(3)对比结果c,就是结果图像(0,0)处的像素值;
(4)切割输入图像从(0,1)至(10,11)的临时图像,对比,并记录到结果图像;
(5)重复(1)~(4)步直到输入图像的右下角。
大家可以看到,直方图反向投影对比的是直方图,而模板匹配对比的是图像的像素值;模板匹配比直方图反向投影速度要快一些,但是我个人认为直方图反向投影的鲁棒性会更好。
#图像二值化处理
def imgThreshold(img):
rosource,binary=cv2.threshold(img,121,255,cv2.THRESH_BINARY)
return binary
#输入的分别是原图模板和标签
def matchTemplate(src,matchSrc,label):
binaryc=imgThreshold(src)
#返回的是一个矩阵,里面的值为每一个匹配的结果
result=cv2.matchTemplate(binaryc,matchSrc,cv2.TM_CCOEFF_NORMED)
#返回最小值、最大值、最小值的位置、最大值的位置
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)
tw,th=matchSrc.shape[:2]
tl=(max_loc[0]+th+2,max_loc[1]+tw+2)
cv2.rectangle(src,max_loc,tl,[0,0,0])
cv2.putText(src,label,max_loc,fontFace=cv2.FONT_HERSHEY_COMPLEX,fontScale=0.6,color=(240,230,0))
cv2.imshow('001',src)3.主程序
这里就没有把切割部分运行了,大家自己将运行一下方法就行了
import cv2
import numpy as np
import matplotlib.pyplot as plt
#图像二值化处理
def imgThreshold(img):
rosource,binary=cv2.threshold(img,121,255,cv2.THRESH_BINARY)
return binary
#1.先水平分割,再垂直分割
# 对图片进行垂直分割
def verticalCut(img,img_num):
(x,y)=img.shape #返回的分别是矩阵的行数和列数,x是行数,y是列数
pointCount=np.zeros(y,dtype=np.float32)#每列黑色的个数
x_axes=np.arange(0,y)
#i是列数,j是行数
tempimg=img.copy()
for i in range(0,y):
for j in range(0,x):
# if j<15:
if(tempimg[j,i]==0):
pointCount[i]=pointCount[i]+1
figure=plt.figure(str(img_num))
# for num in range(pointCount.size):
# pointCount[num]=pointCount[num]
# if(pointCount[num]<0):
# pointCount[num]=0
plt.plot(x_axes,pointCount)
start = []
end = []
# 对照片进行分割
print(pointCount)
for index in range(1, y-1):
# 上个为0当前不为0,即为开始
if ((pointCount[index-1] == 0) & (pointCount[index] != 0)):
start.append(index)
# 上个不为0当前为0,即为结束
elif ((pointCount[index] != 0) & (pointCount[index +1] == 0)):
end.append(index)
imgArr=[]
for idx in range(0,len(start)):
tempimg=img[ :,start[idx]:end[idx]]
cv2.imshow(str(img_num)+"_"+str(idx), tempimg)
cv2.imwrite(img_num+'_'+str(idx)+'.jpg',tempimg)
imgArr.append(tempimg)
return imgArr
# cv2.waitKey()
# plt.show()
#对图片进行水平分割,返回的事照片数组
def horizontalCut(img):
(x,y)=img.shape #返回的分别是矩阵的行数和列数,x是行数,y是列数
pointCount=np.zeros(y,dtype=np.uint8)#每行黑色的个数
x_axes=np.arange(0,y)
for i in range(0,x):
for j in range(0,y):
if(img[i,j]==0):
pointCount[i]=pointCount[i]+1
plt.plot(x_axes,pointCount)
start=[]
end=[]
#对照片进行分割
print(pointCount)
for index in range(1,y):
#上个为0当前不为0,即为开始
if((pointCount[index]!=0)&(pointCount[index-1]==0)):
start.append(index)
#上个不为0当前为0,即为结束
elif((pointCount[index]==0)&(pointCount[index-1]!=0)):
end.append(index)
img1=img[start[0]:end[0],:]
img2=img[start[1]:end[1],:]
img3=img[start[2]:end[2],:]
imgArr=[img1,img2,img3]
for m in range(3):
cv2.imshow(str(m),imgArr[m])
cv2.waitKey()
plt.show()
return imgArr
#输入的分别是原图模板和标签
def matchTemplate(src,matchSrc,label):
binaryc=imgThreshold(src)
result=cv2.matchTemplate(binaryc,matchSrc,cv2.TM_CCOEFF_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)
tw,th=matchSrc.shape[:2]
tl=(max_loc[0]+th+2,max_loc[1]+tw+2)
cv2.rectangle(src,max_loc,tl,[0,0,0])
cv2.putText(src,label,max_loc,fontFace=cv2.FONT_HERSHEY_COMPLEX,fontScale=0.6,
color=(240,230,0))
cv2.imshow('001',src)
#先读取图片
img = cv2.imread("ocrdetect.jpg")
img=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
binary=imgThreshold(img)
#horizontalCut(binary)#这里就没有把切割部分运行了
cv2.imshow('result',binary)
#再读取分割好的图片
match=cv2.imread('num_1_1.jpg',cv2.COLOR_BGR2GRAY)
matchTemplate(img,match,'5')
cv2.waitKey()
cv2.destroyAllWindows()