还在嫌弃作业不够秀?快来试试streamlit+heroku 搭建自己的炫酷app叭
文章目录
- 一、基本介绍
- (一)streamlit
- (二)app效果
- 二、开始搭建
- (一)注册heroku账号
- (二)添加配置文件
- 1、app.py
- 2、requirements.txt
- 3、setup.sh
- 4、Procfile
- (三)发布app
- 1、创建app
- 2、填写app信息
- 3、app连接github仓库
- 4、发布app
- 5、查看发布过程
- 6、完成发布
- 三、总结
- 四、代码:
大家好,我是练习时长一天的偶像练习生“陈独秀”!
童鞋们,你们是否还在为平时作业不够秀,不够高大上,无法引起老师注意而苦恼?
同志们,你们是否还在为向甲方爸爸汇报成果的时候,没有一个华丽的展示方法,秀的他两眼发光,连连叫好而头秃?

请大家搬好小板凳且看在下秀一波操作。
带你们入职偶像练习生!!!

一、基本介绍
(一)streamlit
先简单介绍一下
streamlit
一个python的包,无需任何的HTML,CSS,JS,VUE……
基础就可以做出一个好看又实用的web网页
最最最重要的是他可以和机器学习,数据分析等嵌套
这样就使得streamlit成为一个非常好的可视化成果展示的工具
先看看streamlit的效果
一个官网上的模板
这时候如果再和一些云服务器平台双剑合璧
想一想,给老师或者甲方交过去作业或者方案的时候
直接配上一个网址,他们点进去之后……
简直不要太香

咱在这里先列出一些必看的网站
-
一篇介绍性的文章https://baijiahao.baidu.com/s?id=1648882060644341406&wfr=spider&for=pc
-
streamlit的官网:https://www.streamlit.io -
中文API开发手册http://cw.hubwiz.com/card/c/streamlit-manual/
-
社区https://discuss.streamlit.io
由于这是个比较新兴的项目,有许多的地方还不是特别的优秀,遇到问题的时候可以到社区里查查,说不定一些大佬会给出解决方法哦
streamlit可以和很多的云平台配套
比如说:EC2,Glitch,Heroku
我这里仅给出Heroku的搭建方法
那么为啥选择这个平台嘞?
当然是,Heroku对于像我这样的穷苦学生党和免费用户来说还是比较友好的,每个月有550h的免费挂载时长
算下来大概是23天,应该够用了
下面仅以我的一个作业作为演示
(二)app效果
使用Block-Stripe Update algorithm实现pagerank算法
代码会在最后部分给出
app地址
https://streamlit-pagerank.herokuapp.com
注:该app我只是为了交作业
将于2020年5月20日左右到期
二、开始搭建
(一)注册heroku账号
首先需要用Gmail邮箱注册一个heroku的账号(要用wai wang)
heroku官网
https://www.heroku.com/
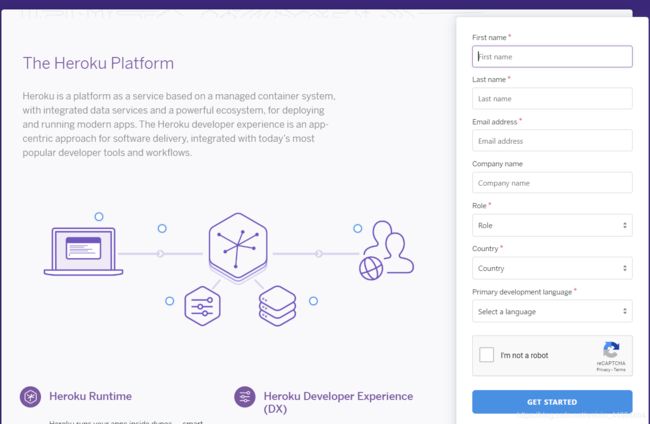
非常方便的一点是heroku可以直接和github仓库关联
这样就可以直接将github仓库里的文件导入进去然后发布就行了
(二)添加配置文件
这里我们需要添加几个配置文件
现在文件目录是
app.pyrequirements.txtsetup.shProcfile
1、app.py
app.py就是我们的自己写的代码了
2、requirements.txt
requirements.txt里需要填好自己所用到的包以及对应的版本
基本格式
numpy==1.17.3
streamlit==0.56.0
graphviz==0.13.2
matplotlib==3.2.1
pandas==1.0.2
3、setup.sh
setup.sh
mkdir -p ~/.streamlit/
echo "\
[general]\n\
email = \"你注册heroku的gmail邮箱\"\n\
" > ~/.streamlit/credentials.toml
echo "\
[server]\n\
headless = true\n\
enableCORS=false\n\
port = $PORT\n\
" > ~/.streamlit/config.toml
4、Procfile
web: sh setup.sh && streamlit run app.py
run后面写你的python文件的名称
(三)发布app
将这些文件push到github之后咱就可以进入heroku发布app啦
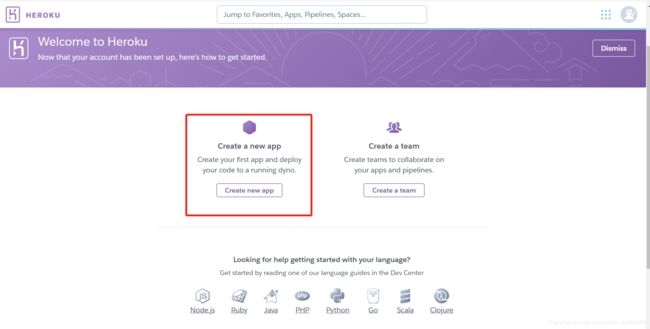
1、创建app
登陆heroku之后先要创建一个app
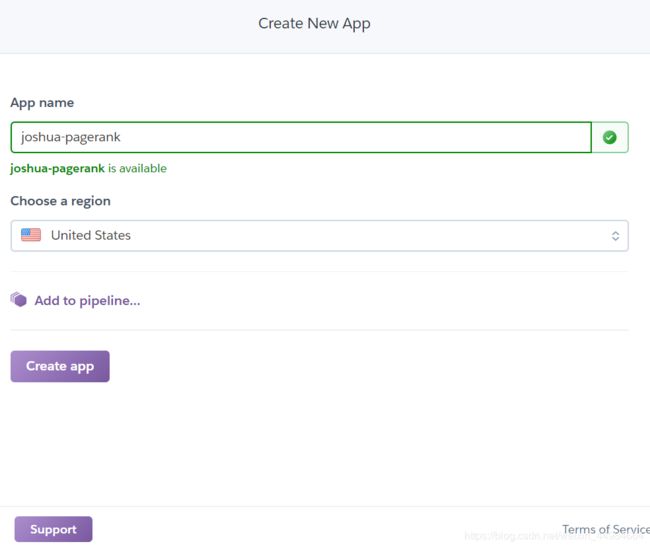
2、填写app信息
填写app的信息
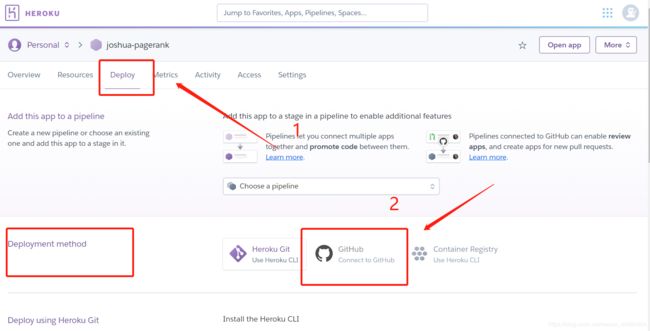
3、app连接github仓库
在发布板块里连接github仓库
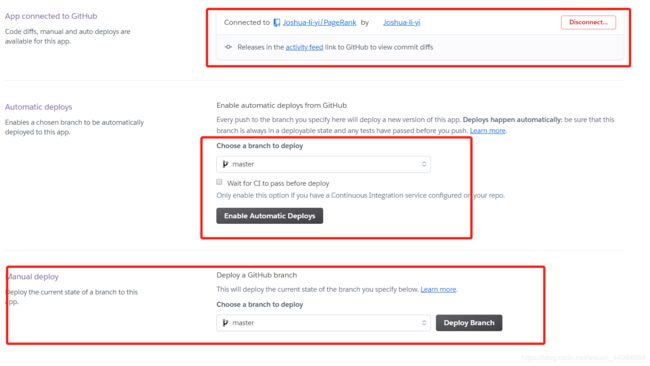
4、发布app
可以选择对应的分支,以及自动发布还是手动发布
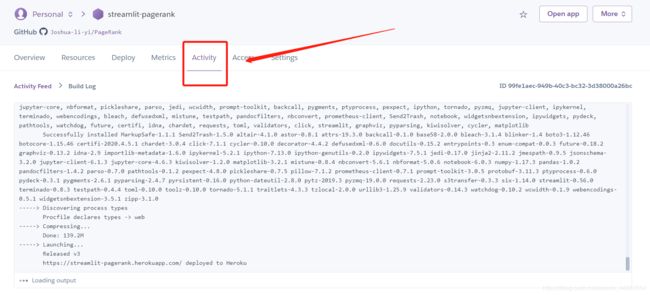
5、查看发布过程
在activity里阔以看到app准备时的信息,方便知道哪里报错了
6、完成发布
最后在setting里就可以看到app的信息啦
Heroku URL就是咱app的网址啦
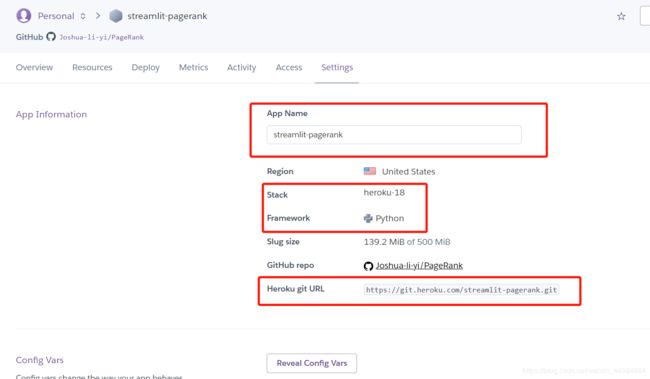
注:我这里的app名字不一样,是因为该文章是分两次写的。
三、总结
以上我们讲述了streamlit和heroku的搭建教程
整个项目可以在我的github上获取
https://github.com/Joshua-li-yi/PageRank/tree/liyi
(包括代码、数据集、配置文件)
敲代码写文章不易,若要转载请附上本文链接~~
如果老铁们觉得有用的话,请给个三连鼓励一下小编吧~~

四、代码:
import time
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import graphviz
# from PIL import Image
import base64
import streamlit as st
import os
# import fitz
# 在画网络关系图时需要重新设置路径
# os.environ["PATH"] += os.pathsep + r'C:\Program Files (x86)\graphviz-2.38\release\bin'
# 设置参数
derta = 0.00001
# 设置pycharm显示宽度和高度
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
# 从txt导入数据、将数据转化成 csv 格式 nodes 输入和输出,类似于将边存起来
# 输出nodes--------dataframe 格式 和all_node --------list,frac 设置随机取文件中数的比例
def load_data(filePath, output_csv=False, frac=1.):
print('begin load data')
txt = np.loadtxt(filePath)
nodes = pd.DataFrame(data=txt, columns=['input_node', 'output_node'])
# 将值转化为int类型
nodes['input_node'] = nodes['input_node'].astype(int)
nodes['output_node'] = nodes['output_node'].astype(int)
# 设置随机取多少行
if frac != 1.:
print('random select', frac * 100, '% data')
nodes = nodes.sample(frac=frac, random_state=1)
if output_csv is True:
nodes.to_csv('WikiData.csv')
# 根据inputpage的值排序
nodes.sort_values('input_node', inplace=True)
# 重置索引
nodes.reset_index(inplace=True, drop=True)
# all_node 加载为list 有重复值
all_node = nodes['input_node'].values.tolist()
all_node.extend(nodes['output_node'].values.tolist())
# all_node 转为set 再转为list
all_node = set(all_node)
all_node = list(all_node)
# all_note 升序排列
all_node.sort()
# print(all_node)
print('load data finish')
return nodes, all_node
# 预处理函数
def pre_process(nodes,show_info=True):
print('begin Preprocessing')
if show_info is True:
st.info("数据预处理")
st.info("重复的行")
st.write(nodes[nodes.duplicated()])
print('Determine whether there are duplicate lines')
print(nodes[nodes.duplicated()])
print('Preprocessing finish')
# 生成rank值
def generate_rank(all_node):
initial_old_rank = 1 / len(all_node)
rank = {node: initial_old_rank for node in all_node}
print('generate initial rank finish')
return rank
# 将一个列表划分为多个小列表
def list_to_groups(list_info, per_list_len):
'''
:param list_info: 列表
:param per_list_len: 每个小列表的长度
:return:
'''
list_of_group = zip(*(iter(list_info),) * per_list_len)
end_list = [list(i) for i in list_of_group] # i is a tuple
count = len(list_info) % per_list_len
end_list.append(list_info[-count:]) if count != 0 else end_list
return end_list
# 计算每个节点的出度
def comput_node_output_time(nodes):
node_output_time = nodes.apply(pd.value_counts)['input_node']
return node_output_time
# 新的分块方法,原先使用dataframe格式存的分块
# 现在改为使用list格式,相应读取时也要使用list格式的方法
def quick_block_stripe(nodes, block_node_groups,show_info=True):
# 存最后的各个划分后的M
node_output_time = comput_node_output_time(nodes)
M_block_list = []
# 根据input_node 进行分组进行分组
grouped = nodes.groupby('input_node')
if show_info is True:
temp_len = len(block_node_groups)
st.info("block strip progress")
bar = st.progress(0)
temp_i = 0
for node_group in block_node_groups:
temp_i += 1
# 将大的M 根据 划分后的node节点,进行块条化最后结果存到M_block_stripe列表中
for key, group in grouped:
# print(group)
output_node_list = group['output_node'].values.tolist()
intersect_set = set(node_group).intersection(output_node_list)
intersect_set = list(intersect_set)
if len(intersect_set):
M_block_list.append([key, node_output_time[key], intersect_set])
bar.progress(temp_i/temp_len)
else:
for node_group in block_node_groups:
# 将大的M 根据 划分后的node节点,进行块条化最后结果存到M_block_stripe列表中
for key, group in grouped:
# print(group)
output_node_list = group['output_node'].values.tolist()
intersect_set = set(node_group).intersection(output_node_list)
intersect_set = list(intersect_set)
# np.where(len(intersect_set),M_block_list.append([]))
if len(intersect_set):
M_block_list.append([key, node_output_time[key], intersect_set])
return M_block_list
# rank值计算
def pageRank(M_list, old_rank, all_node,show_info=True):
num = len(all_node)
initial_rank_new = (1 - Beta) / num
sum_new_sub_old = 1.0
# 是否显示迭代信息
if show_info is True:
st.info("开始迭代")
iter_time = 0
while sum_new_sub_old > derta:
iter_time += 1
new_rank = {node: initial_rank_new for node in all_node}
for m in M_list:
temp_old_rank = old_rank[m[0]]
temp_degree = m[1]
for per_node in m[2]:
new_rank[per_node] += Beta * temp_old_rank / temp_degree
# 解决dead-ends和Spider-traps
# 所有new_rank的score加和得s,再将每一个new_rank的score加上(1-sum)/len(all_node),使和为1
s = sum(new_rank.values())
ss = (1 - s) / num
new_rank = {k: new_rank[k] + ss for k in new_rank}
# 计算sum_new_sub_old
temp_list = list(map(lambda x: abs(x[0] - x[1]), zip(new_rank.values(), old_rank.values())))
sum_new_sub_old = np.sum(temp_list)
old_rank = new_rank
st.write("迭代次数:", iter_time)
else:
while sum_new_sub_old > derta:
new_rank = {node: initial_rank_new for node in all_node}
for m in M_list:
temp_old_rank = old_rank[m[0]]
temp_degree = m[1]
for per_node in m[2]:
new_rank[per_node] += Beta * temp_old_rank / temp_degree
# 解决dead-ends和Spider-traps
# 所有new_rank的score加和得s,再将每一个new_rank的score加上(1-sum)/len(all_node),使和为1
s = sum(new_rank.values())
ss = (1 - s) / num
new_rank = {k: new_rank[k] + ss for k in new_rank}
# 计算sum_new_sub_old
temp_list = list(map(lambda x: abs(x[0] - x[1]), zip(new_rank.values(), old_rank.values())))
sum_new_sub_old = np.sum(temp_list)
old_rank = new_rank
print('rank compute finish')
return new_rank
# 相当于main,输入文件路径,输出rank值
# step 设置块条化的步长
# show_info 是否显示过程信息
def mypageRank(nodes, all_node, step,show_info=True):
# nodes, all_node = load_data(file, output_csv=False, frac=row_frac)
rank = generate_rank(all_node)
pre_process(nodes,show_info)
# print(rank)
# 将allnode分成小块
block_node_groups = list_to_groups(all_node, step)
# print(block_node_groups)
# quick block strip
start_quick_block = time.perf_counter()
M_block_list = quick_block_stripe(nodes, block_node_groups,show_info)
end_quick_block = time.perf_counter()
print('Running time: %s Seconds' % (end_quick_block - start_quick_block))
# print(M_block_stripe)
# 计算pagerank值
start_pagerank = time.perf_counter()
new_rank = pageRank(M_block_list, rank, all_node,show_info)
end_pagerank = time.perf_counter()
print('Running time: %s Seconds' % (end_pagerank - start_pagerank))
st.info('执行时间: %s Seconds' % (end_pagerank - start_pagerank))
new_rank = pd.DataFrame(new_rank.items(), columns=['page', 'score'])
new_rank.set_index('page', inplace=True)
# rank排序 从大到小
new_rank.sort_values('score', inplace=True, ascending=0)
# 取前一百
sort_rank = new_rank.head(100)
return sort_rank, new_rank
# 下载结果文件csv格式
def get_table_download_link(df,file_name):
"""Generates a link allowing the data in a given panda dataframe to be downloaded
in: dataframe
out: href string
"""
csv = df.to_csv(index=False)
b64 = base64.b64encode(
csv.encode()
).decode() # some strings <-> bytes conversions necessary here
return f'Download csv file'
st.title("PAGERANK 结果可视化")
st.markdown("### 1、参数控制")
# st.write('
')
st.info("设置teleport的值")
Beta = st.slider(label='teleport', min_value=0., max_value=1.,key=1)
# 设置取的随机行数的比例
# st.info("设置取的随机行数的比例,考虑到运行时间的因素,最好设置在0.05以下")
# row_frac = st.slider(label='frac', min_value=0., max_value=1.,key=2)
st.write("teleport=", Beta)
nodes = pd.DataFrame()
all_node = []
# 导入数据
st.markdown("### 2、导入数据集")
upload_file = st.file_uploader("", type="txt")
if upload_file is not None:
temp_nodes, temp_all_node = load_data(upload_file, frac=1.)
nodes = temp_nodes
all_node = temp_all_node
st.success('导入数据集成功!')
length = len(nodes)
st.write("数据有", length, "条")
# 空行
st.write("")
# 需要用外网,若有,请取消注释
# st.write("下载当前数据集到本地")
# st.markdown(get_table_download_link(nodes,'node'), unsafe_allow_html=True)
# 块儿条化
st.write("")
st.info("设置块条化的步长,不同的步长执行时间不同")
block_step= st.slider(label='step', min_value=0, max_value=10000,step=50,key=3)
st.write("块条化步长为",block_step)
# 计算rank值
st.write("")
st.markdown("### 3、rank值计算和可视化")
def comput_rank(show_info=True):
temp_scores, temp_all_scores = mypageRank(nodes, all_node, step=block_step,show_info=show_info)
# 将page一列重新转化为非index列,并增加新的一列
temp_scores = temp_scores.reset_index()
temp_all_scores = temp_all_scores.reset_index()
# 从1开始索引
temp_scores.index += 1
return temp_scores,temp_all_scores
# 计算rank值的按钮
st.write("")
btn_compute_pageRank = st.button("计算rank值")
if btn_compute_pageRank:
scores,all_score = comput_rank()
st.info("页面及其分数如下")
st.table(scores)
st.success("计算rank值成功!")
st.markdown('')
# 需要用外网,若有,请取消注释
# st.write("下载score到本地")
# 下载链接
# st.markdown(get_table_download_link(scores,'rank'), unsafe_allow_html=True)
# 将PDF转化为图片
# pdfPath pdf文件的路径
# imgPath 图像要保存的文件夹
# zoom_x x方向的缩放系数
# zoom_y y方向的缩放系数
# rotation_angle 旋转角度
# zoom_x和zoom_y一般取相同值,值越大,图像分辨率越高。
# def pdf_image(pdfPath, imgPath, zoom_x, zoom_y, rotation_angle):
# # 打开PDF文件
# pdf = fitz.open(pdfPath)
# # 逐页读取PDF
# for pg in range(0, pdf.pageCount):
# page = pdf[pg]
# # 设置缩放和旋转系数
# trans = fitz.Matrix(zoom_x, zoom_y).preRotate(rotation_angle)
# pm = page.getPixmap(matrix=trans, alpha=False)
# # 开始写图像
# pm.writePNG(imgPath + str(pg) + ".png")
# pdf.close()
def comput_subset(row,node_list):
if set([row[0], row[1]]).issubset(node_list):
return True
else:
return False
# 可视化图表的按钮
st.write("")
btn_show_pageRank = st.button("可视化图表")
if btn_show_pageRank:
st.info("正在计算")
scores, all_score = comput_rank(show_info=False)
# 取排名前20的点
temp_scores = scores.head(20)
node_list = temp_scores['page'].tolist()
st.info("排名前20的网络关系图")
graph = graphviz.Digraph()
# 取出node的子集,根据是否在前20名
new_nodes = nodes[nodes.apply(lambda row: comput_subset(row, node_list), axis=1)]
# 为graph添加边
new_nodes.apply(lambda row: graph.edge(str(row[0]), str(row[1])), axis=1)
# 保存图形为pdf
graph.render('newwork_graph')
st.graphviz_chart(graph)
# pdf转为png
# pdf_image(r"newwork_graph.pdf", "", 5, 5, 0)
# # 打开png
# img = Image.open("0.png")
# # 显示img
# st.image(img, width=800)
# all_score.sort_values('page', inplace=True, ascending=True)
x = all_score['page'].tolist()
y = all_score['score'].tolist()
st.info("条形图")
plt.bar(x, y)
plt.ylabel("score")
plt.xlabel("page")
# 显示图形
st.pyplot()
st.info("散点图")
plt.scatter(x, y)
plt.ylabel("score")
plt.xlabel("page")
st.pyplot()
st.info("箱型图")
all_score.set_index('page', inplace=True)
all_score.boxplot()
st.pyplot()
st.markdown("### 4、结束")
if st.button("结束"):
st.balloons()