干货速看 | FATE首届圆桌会,专家团深度揭秘1.4版本
6月3日,咱们FATE开源社区首届圆桌会完美落幕。这场圆桌会上,我们邀请了40+位社区朋友,他们有的是踊跃帮助其他人解决技术问题的“热心群众”,有的已经把联邦学习应用于生产环境的FATE成为生产力工具的人。
在这场圆桌会上,首先由咱们FATE 内部专家团队对FATE 1.4新版本的各模块功能点进行简介说明,并对大家遇到的一些问题进行交流解答,以下为专家分享主题&大纲(PPT可添加FATE社区助手获取):
FATE:1.4更新简介
1、横向SecureBoost树
2、早停机制(Early Stop)
3、纵向广义线性模型逐步回归
4、联邦学习开源平台-FATE
——MingChao Tan

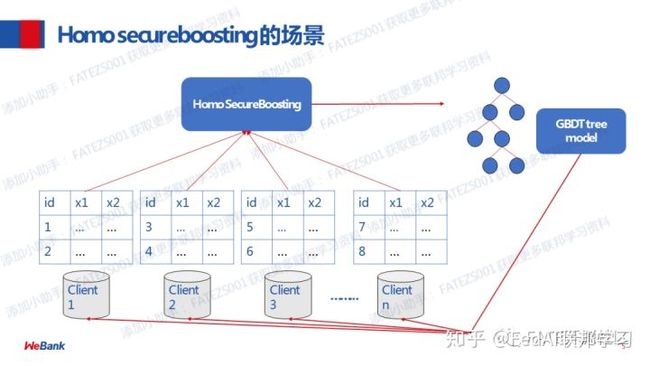
Eggroll 2:新一代的计算引擎
1、Eggroll 2的改进
2、全新的session与资源管理
3、参数配置及常见排错方法
——MAX

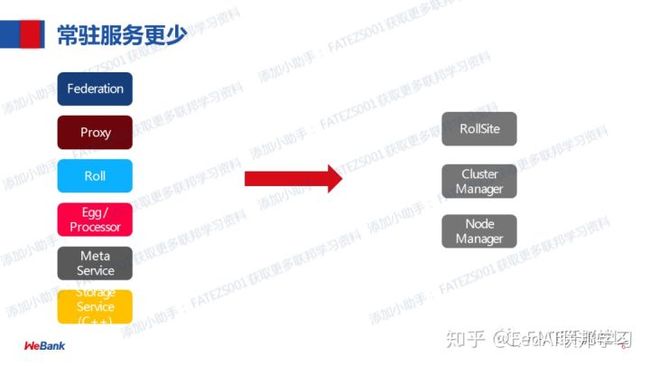
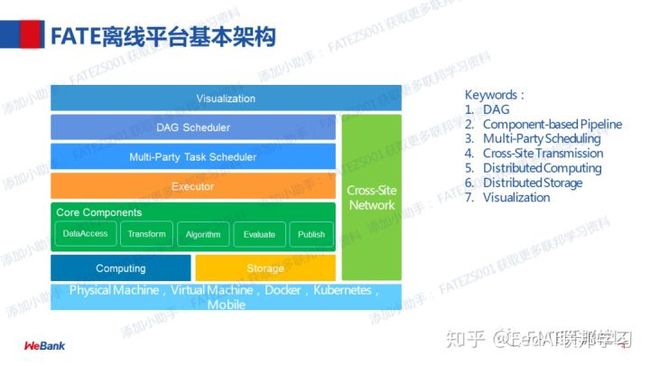
FATE v1.4 主要更新-系统工程部分
1、FATE v1.4 整体架构优化
2、FATE v1.4 部署介绍
——Jarvis Zeng

在专题分享后,我们共同探讨了FATE存在的一些问题并提出了解决方案与思路,并对FATE的后续版本能力的可能性进行论述,一起对FATE未来的应用畅想探讨,以下为本次圆桌会上的互动环节的问答内容(节选):
Q1、FATE的计算引擎能否直接用已经比较成熟的引擎,比如Spark?
当前版本(1.4)已经支持Spark。另外,其实EggRoll吸取了现有引擎的一些经验,尤其在联邦学习场景下非常有优势,所以其会是FATE主推的引擎。当然为了生态的多样性、打通不同框架的互操作性,FATE同时也在持续优化支持更多的引擎。
Q2、可否再详细列举下Spark 和EggRoll在设计上的不同呢?
其中一个比较大的差异是,Spark和EggRoll对于存储这一点的理解,设计上是有不同的。Spark可能更多地使用hdfs,它在调度的时候,需要把数据从hdfs拉到执行计算的节点,或者拉到比较接近计算的那个节点去执行的。如果用一种流行说法来说,spark采取的做法叫:存储和计算分离。
EggRoll跟Spark这一方面对比,走了另外一条路线。EggRoll是把存储和计算绑定在一起的,就是不传输数据,而是把计算逻辑传输到数据所在的地方去执行。由于计算逻辑较小,所以不需要进行大规模的数据移动。
另外一点不同,EggRoll的每个节点是有状态的。前面提到EggRoll是要把存储和计算绑在一起,所以在使用集群的时候,每个节点是有状态的。因为每一个节点上存储的数据是属于不同分片的。所以这两点可能是其中两个与spark比较大的区别。
Q3、 FATE1.4后续是否提供helm部署方式(在k8s上)?
已经支持,可以参考子项目KubeFATE:
https://github.com/FederatedAI/KubeFATE
Q4、任务运行时间比较久的话,会有大量的僵尸进程占据内存,如何kill掉之前任务的僵尸进程?
需要僵尸进程具体的名称进行具体分析。作为一个已大规模在生产使用的工业级框架,FATE做了大量且严格的性能测试与稳定性测试。尤其在1.4版本EggRoll引擎大升级的情况下,过去这段时间实际生产运行的观察也符合预期。
Q5、关于模型导入和导出的问题,模型导出后还是分布式模型,但无法在本地的环境中还原成中心化的模型来做预测吗?
此前的1.3版本,横向的模型通过component_model的接口,导出后是个zip的文件包,解开后可以还原成keras的模型。纵向的模型的话,本来就是分布式的,所以导出后也无法在本地使用?
这是两个不同的问题,模型的导入导出,是指模型的拥有方可以在其不同的运行环境下复用模型。纵向联邦的模型,本身就无法支持一方单独使用,这个是其原理所决定的。
Q6、关于加密的问题,在对比了官方提供的三个横向的模型,发现存在多种加密方式paillier加密、Secure Aggregation。为什么不用统一点的方式呢?因为横向模型差异较少的情况下,为什么有的选择用Paillier,有的用secure aggregation?
在横向中,Paillier加密和Secure Aggregation的作用是不一样的。paillier只会在lr里用的paillier加密,是为了不希望Host方拿到这个模型,所以我们对它加密,在LR当中也可以不用Paillier加密,只使用Secure Aggregation也是可以的。
Secure Aggregation的作用就是不希望Arbiter会拿到每一个单独某一方的这个模型,他只能拿到这个所有方聚合后的模型,所以它作用是不太一样的。
Q7、 FATE为什么只用paillier做加密?
FATE不会聚焦于特定的一种产品算法,比如Paillier。现在它已经支持了SecureSharing,以及一些仿射变换的同态加密、对称加密等多种算法。我们会根据你算法特点、实际情况去选择合适的加密算法来满足特定需求。
Q8、 请问是否会考虑,通过直连外部各种异构数据源将数据直接将数据写入lmdb,进行后续计算。不用将数据写成离线文件,在p再上传到lmdb?
这个能力正在开发当中,也是FATE正在逐步去支持当前现有的大数据生态和一些计划,如后期我们会支持直接从hdfs和hive去直接导入数据到fate的集群里面。
从EggRoll角度分析,其实外部的多种异构数据源,在EggRoll 2里面是比较容易去支持的。在我们的另外一个业务里面,已经实现了直接读写hdfs,这个后续内部会讨论具体哪种方式去比较好。因为在刚才介绍架构的图的最底层,看到EggRoll已经支持不同的存储介质,然后这里面我们已经做了抽象,所以已经可以只读写htfs这种了,按性能的话肯定不如lmdb好。
Q9、问下升级后的版本对资源要求如何?
Eggroll方面而言,因常驻进程的减少,所以它的常驻占用的内存是少了的,在具体去执行的时候,计算引擎的资源要求跟以前应该是差不多的。总的来说常驻的一部分是少了,而且计算引擎执行完以后会释放。
Q10、请问老师能不能省去第三方,第三方能不能是合作的某一方?
我们的纵向算法不是所有的算法都一定有第三方,比如纵向的secure boost布置就没有第三方,纵向的nn也没有第三方,未来的话lr也是希望往消除第三方的思路方式发展。有第三方确实是比较麻烦,如果说目前你必须在lr里面是使用第三方的情况下呢,但只有两方又要使用lr算法的情况下,我们会推荐把Arbiter放在Host这边,相对而言,arbiter和host的串通,若想要破解guest方的数据,是比较困难的。但这仅是权宜之计,从安全考量还是尽量加入第三方。
想与官方专家团队面对面交流?添加FATE助手(微信号:FATEZS001),加入到FATE开源社区,与更多开发者一同探索联邦学习,享受更多开源社区特权福利。
