如何评价亚马逊AI新开源自动机器学习项目AutoGluon?
链接:https://www.zhihu.com/question/360250836
编辑:深度学习与计算机视觉
声明:仅做学术分享,侵删
作者:李沐
https://www.zhihu.com/question/360250836/answer/971500560
看到灵魂调参师@Justin ho的朋友圈顺手转了下,结果被报道了 https://mp.weixin.qq.com/s/ChYLuxGxsQK0g6MImimSDQ
不过我们确实观察到了相似的结论。AutoML使用大概15倍于单次训练的代价,得到的结果可能比手调的要好。这个主要是对于CV而言,尤其是detection模型,预计GluonCV里面模型很快赢来一大波提升。
但更一般的AutoML还是比较难。例如Tabular数据的,很多时候手工设计的特征还是挺好。
AutoGluon取了一个巧,我们目前只支持GluonCV和GluonNLP里面的任务,和额外的Tabular数据(因为一个小哥之前有过经验)。所以我们可以把以前的很有经验东西放进去来减小搜参空间,从而提升速度。
当然AutoGluon还是早期项目,我本来想是让团队再开发一些时间再公开。还有太多有意思的应用、算法、硬件加速可以做的。非常欢迎小伙伴能一起贡献。
作者:张航
https://www.zhihu.com/question/360250836/answer/1224137065
AutoGluon 这个项目是我在产假期间开始做的,所以对她的感情像我的女儿一样。第一个commit基本上包含了 AutoGluon 这个项目的整体设计。个人认为从 API 角度,AutoGluon 是调参工具里面设计最为精巧的,可以通过加几行代码,就可以轻松地将已有的 python 代码转化为可以搜索的主函数,并且开始搜索:
系统里面每一个部分都是模块化的,便于扩展,下面给一个系统图:
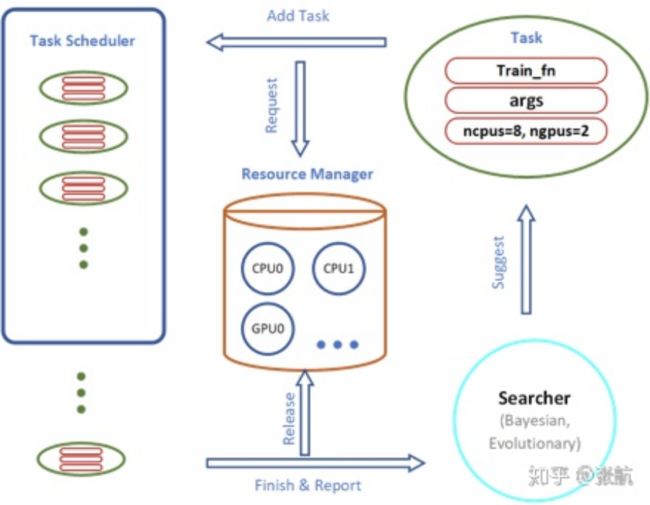
每一个任务都由:1. 主函数,2. 参数,3. 计算资源 组成。其中搜索算法可以提供参数优化,资源管理器动态管理分发计算资源,任务调度器来管理任务调度和提前终止。
AutoGluon的另外一个优势就是分布式训练,不管你有没有分布式训练的经验,只需要提供一个 IP 地址,autogluon会自动地把任务分发到远端的机器上:
后台系统会自动地根据不同机器的计算资源,自动调配,下面是分布式的资源管理流程图:
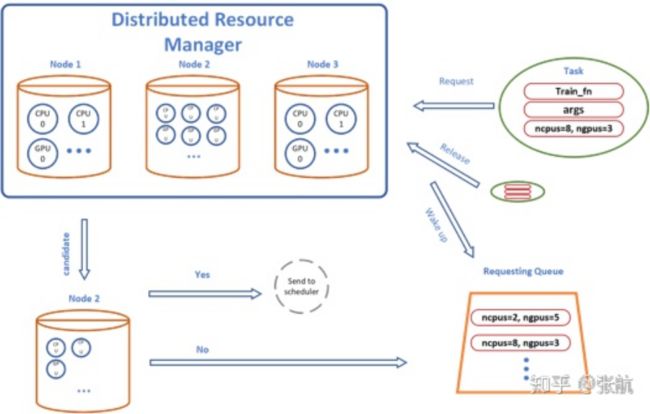
AutoGluon 的兼容性和扩展性,可以很容易地将科研算法 开展到大规模实验中。在 AutoGluon 开发的之初就吸引到了亚马逊内部的 AutoML 大佬 Matthias ,他们团队使用 AutoGluon 做了 multi-fidelity 的搜索算法,有兴趣的小伙伴可以关注一下他们最新的论文:Model-based Asynchronous Hyperparameter Optimization https://arxiv.org/abs/2003.10865 。这个算法也很快会开源到 AutoGluon 项目里。
作者:mileistone
https://www.zhihu.com/question/360250836/answer/1039923243
AutoGluon特点总结如下。
三大应用领域
image(image classification、object detection)
text(text classification)
tabular data(tabular prediction)
两大功能
自动调参
不仅支持mxnet,还支持PyTorch
支持的搜索策略包括random search、grid search、RL、Bayesian optimization等
NAS(仅支持image classification,目前只有ENAS)
与AutoGluon类似的AutoML工具还有下图所示项目。
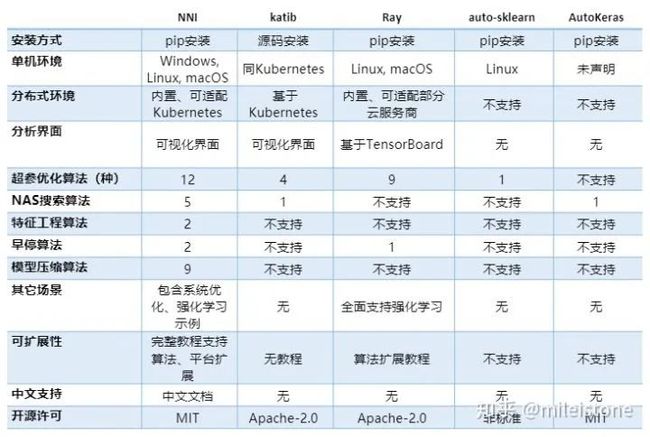
其中最值得一提的是微软的NNI。支持多种框架;包括四大功能:feature engineering、architecture search、hyperparameter tuning、model compression。其中architucture search包括5种算法(AutoGluon当前包括ENAS),hyperparameter tuning包括12种算法(AutoGluon当前是4种)。

相比NNI,AutoGluon当前还比较单薄,不过AutoGluon有一个优势——GluonCV和GluonNLP,基于这两个非常棒的工具箱,AutoGluon可以在CV和NLP两个领域做出自己的特色。但是这个优势同时又不算优势,因为GluonCV和GluonNLP是基于mxnet的,mxnet的用户量不够大。
题外话
Justin Ho的回答不太严谨,Justin Ho想对比手工调参与NAS谁更优,“手工调参”一方用的是GluonCV的Faster R-CNN,“NAS”一方用的是AutoGluon的检测demo(基于YOLOv3),但是AutoGluon的检测demo并没有使用NAS,搜索空间只针对LR(5e-4和1e-4)。Justin Ho的结论“被NAS打爆了”,“还爆了5个点”值得商榷。
作者:费特杨
https://www.zhihu.com/question/360250836/answer/972747536
讲道理,构建涉及图像,文本和表格数据集的机器学习应用程序还是很麻烦的,需要特征工程或使用数据领域知识来创建使AI算法起作用的特征,此外还需要进行大量数据预处理,从而确保在经过训练的模型中不会出现偏差。
而现在有了AutoGluon,可以自动执行许多复杂任务了。开发需要做的事被进一步简化,指定希望对其模型进行训练的速度,AutoGluon将在给定的时间内提出最强大的模型。
其实这东西已经开发一段时间了,只是这几天才在G站放出来:
作者:贺定圆
https://www.zhihu.com/question/360250836/answer/972680275
在AutoML(Automated Machine Learning)领域存在现实的多个痛点:
构建机器学习模型环节多、流程长
依赖数据科学、机器学习专家知识
模型难以通用
专业人才数量缺乏
其次,在业务上也存在越来越明显的诉求:
缩短AI 项目的投产时间,降低建模所需人员规模和专业能力的门槛,通过自动化技术将 AI的构建时间缩短至数天甚至数小时;
降低AI 项目的建设成本,通过标准化的建模过程,实现AI的规模化应用,减少AI落地所需的总成本;
支撑业务的快速变化,利用高性能的AI开发工具实现模型的快速迭代,灵活适应业务变化。
AutoML的核心目标,是无需人工干预即可实现更低的计算开销,输出更好的泛化能力模型。
所以,AutoGluon其实在预期之内。
由于一线大厂工程师众多,“研发要提效”是绕不开的KPI,往往会利用平台技术和资源优势,朝着解放生产力的方向发展,比如研发流程的自动化、平台化、智能化(减少测试、运维、DBA等角色和数量的依赖),来保障研发规范的统一和过程的高效,使得工程师可以更专注于核心能力的投入。
但企业要解决AI项目数量规模化之后所带来的挑战,要解决特定领域人才短缺的挑战,就会涉及到对开发、计算、流程能力的组件化、平台化、智能化方向演进,随着内部能力的足够成熟,要么开放开源、要么上云端实现能力的商业化增值,这是接下来大厂对待技术的主流趋势。
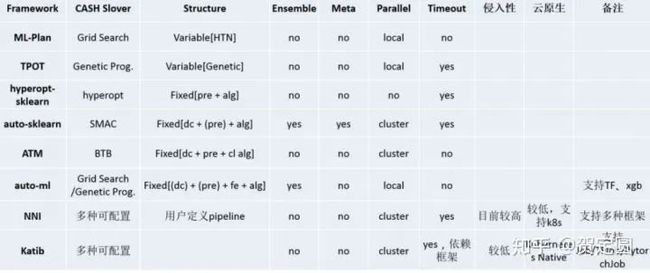
AutoML领域的开源框架对比
AutoGluon如作者所说,大部分场景的能力还有限,外界期望高于现阶段的实际能力,但开源后至少减少了部分工程师头疼的次数,完全值得肯定。而手工调参的工作,不管在哪个领域迟早会被程序自动接管,包括在传统编程领域,系统或运行时环境应该有能力实现自我调参,或执行更优的(内存或算法)模型,无需人为输入,人工的优势在于理解使用本次程序要达到的真实目的是什么,基于外界环境给出更贴合人类自身真实情感和内心诉求的反馈,所以人工智能始终需要人工设定策略和指导,分工协作,从这方面来说,擅长调参的工程师将来可能会失业,但懂得利用开源技术手段来覆盖和满足产品诉求的算法工程师不会,这方面来说AutoGluon并不是孤独者,AutoSklearn、微软的NNI等,都是可选的开源提效工具。
作者:匿名用户
https://www.zhihu.com/question/360250836/answer/1271515137
很不错的项目,应该是未来的一大方向,希望mxnet能够撑下去。
我们组也对这个有尝试,实际效果比调参好那么一点,但是我们还是爱弄模型迁移,迁移做出来效果好点。
为什么这样说呢,因为我们组严格意义上并没有算法工程师。平常都是做做迁移学习,调参这种基本业余。只有数据量过大的时候,调参才有价值,小样本通常都是迁移学习。平常做项目都是caffe直接上,迁移微调几层,也不需要太注意调参。
最爱的就是caffe,实际工程上caffe还是用的最多的。C++部署也容易,pc端和手机端上的openvino和ncnn对caffe非常友好。我们从来不管框架先不先进,反正常用的就是yolov3,mobilenet之类的,实在是没有太多样本,这是工业界的现状。
所以现在对于工业界最希望的是autoML和auto deployment,希望mxnet团队能够花多一点时间在C++/java等部署上,方便我们这样的专门做部署的。
不过总而言之autogluon好东西,再接再厉。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇高质量博文(无广告)。
↓扫描二维码添加小编↓
