IT学习笔记--日志收集系统EFK之Kibana
简介
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。
你用Kibana来搜索,查看,并和存储在Elasticsearch索引中的数据进行交互。
你可以轻松地执行高级数据分析,并且以各种图标、表格和地图的形式可视化数据。
Kibana使得理解大量数据变得很容易。它简单的、基于浏览器的界面使你能够快速创建和共享动态仪表板,实时显示Elasticsearch查询的变化。
支持的平台和配套的Elasticsearch版本:
Kibana 有 Linux、Darwin 和 Windows 版本的安装包。由于 Kibana 基于 Node.js 运行,我们在这些平台上包含了一些必要的 Node.js 二进制文件。Kibana 不支持在独立维护的 Node.js 版本上运行。
Kibana 的版本需要和 Elasticsearch 的版本一致。这是官方支持的配置。
运行不同主版本号的 Kibana 和 Elasticsearch 是不支持的(例如 Kibana 5.x 和 Elasticsearch 2.x),若主版本号相同,运行 Kibana 子版本号比 Elasticsearch 子版本号新的版本也是不支持的(例如 Kibana 5.1 和 Elasticsearch 5.0)。
运行一个 Elasticsearch 子版本号大于 Kibana 的版本基本不会有问题,这种情况一般是便于先将 Elasticsearch 升级(例如 Kibana 5.0 和 Elasticsearch 5.1)。在这种配置下,Kibana 启动日志中会出现一个警告,所以一般只是使用于 Kibana 即将要升级到和 Elasticsearch 相同版本的场景。
运行不同的 Kibana 和 Elasticsearch 补丁版本一般是支持的(例如:Kibana 5.0.0 和 Elasticsearch 5.0.1),尽管我们鼓励用户去运行最新的补丁更新版本。
安装
使用 .tar.gz 安装 Kibana:
Kibana 为 Linux 和 Darwin 平台提供了 .tar.gz 安装包。这些类型的包非常容易使用。
Kibana 的最新稳定版本可以在 Kibana 下载页找到。其它版本可以在 已发布版本中查看。
下载安装 Linux 64 位包
Kibana v6.0.0 的 Linux 文件可以按照如下方式下载和安装:
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.0.0-linux-x86_64.tar.gz
sha1sum kibana-6.0.0-linux-x86_64.tar.gz
tar -xzf kibana-6.0.0-linux-x86_64.tar.gz
cd kibana/ Kibana 可以从命令行启动,命令如下:
./bin/kibana
默认 Kibana 在前台启动,打印日志到标准输出 (stdout),可以通过 Ctrl-C 命令终止运行。
.tar.gz 文件目录结构
.tar.gz 整个包是独立的。默认情况下,所有的文件和目录都在 $KIBANA_HOME — 解压包时创建的目录下。这样非常方便,因为您不需要创建任何目录来使用 Kibana,卸载 Kibana 就是简单地删除 $KIBANA_HOME 目录。但还是建议修改一下配置文件和数据目录,这样就不会删除重要数据。
| 类型 | 描述 | 默认位置 | 设置 |
|---|---|---|---|
| home |
Kibana home 目录或 |
解压包时创建的目录 |
|
| bin |
二进制脚本,包括 |
|
|
| config |
配置文件,包括 |
|
|
| data |
Kibana 和其插件写入磁盘的数据文件位置。 |
|
|
| optimize |
编译过的源码。某些管理操作(如,插件安装)导致运行时重新编译源码。 |
|
|
| plugins |
插件文件位置。每一个插件都有一个单独的二级目录。 |
|
在 Windows 上安装 Kibana:
在 Windows 中安装 Kibana 使用 .zip 包。
最新稳定版 Kibana 可以从 Kibana 下载页获得。其他版本可以在 已发布版本中查看。
下载安装 .zip 包
下载 Kibana v6.0.0 的 .zip windows 文件: https://artifacts.elastic.co/downloads/kibana/kibana-6.0.0-windows-x86_64.zip
用您喜欢的解压工具解压下载的 zip 包。会创建一个文件夹叫 kibana-6.0.0-windows-x86_64,也就是我们指的 $KIBANA_HOME 。在一个终端窗口中, CD 到 $KIBANA_HOME 目录,例如:
CD c:\kibana-6.0.0-windows-x86_64
Kibana 可以从命令行启动,如下:
.\bin\kibana
默认情况下,Kibana 在前台启动,输出 log 到 STDOUT ,可以通过 Ctrl-C 停止 Kibana。
Kibana 默认情况下从 $KIBANA_HOME/config/kibana.yml 加载配置文件。
.zip 文件目录结构:
.zip 整个包是独立的。默认情况下,所有的文件和目录都在 $KIBANA_HOME — 解压包时创建的目录下。这是非常方便的,因为您不需要创建任何目录来使用 Kibana,卸载 Kibana 只需要简单的删除 $KIBANA_HOME目录。但还是建议修改一下配置文件和数据目录,这样就不会删除重要数据。
| 类型 | 描述 | 默认位置 | 设置 |
|---|---|---|---|
| home |
Kibana home 目录或 |
解压包时创建的目录 |
|
| bin |
二进制脚本,包括 |
|
|
| config |
配置文件包括 |
|
|
| data |
Kibana 和其插件写入磁盘的数据文件位置。 |
|
|
| optimize |
编译过的源码。某些管理操作(如,插件安装)导致运行时重新编译源码。 |
|
|
| plugins |
插件文件位置。每一个插件都一个单独的二级目录。 |
|
配置
Kibana server 启动时从 kibana.yml 文件中读取配置属性。Kibana 默认配置 localhost:5601 。改变主机和端口号,或者连接其他机器上的 Elasticsearch,需要更新 kibana.yml 文件。也可以启用 SSL 和设置其他选项。
Kibana配置项:
server.port:
默认值: 5601 Kibana 由后端服务器提供服务,该配置指定使用的端口号。
server.host:
默认值: "localhost" 指定后端服务器的主机地址。
server.basePath:
如果启用了代理,指定 Kibana 的路径,该配置项只影响 Kibana 生成的 URLs,转发请求到 Kibana 时代理会移除基础路径值,该配置项不能以斜杠 (/)结尾。
server.maxPayloadBytes:
默认值: 1048576 服务器请求的最大负载,单位字节。
server.name:
默认值: "您的主机名" Kibana 实例对外展示的名称。
server.defaultRoute:
默认值: "/app/kibana" Kibana 的默认路径,该配置项可改变 Kibana 的登录页面。
elasticsearch.url:
默认值: "http://localhost:9200" 用来处理所有查询的 Elasticsearch 实例的 URL 。
elasticsearch.preserveHost:
默认值: true 该设置项的值为 true 时,Kibana 使用 server.host 设定的主机名,该设置项的值为 false 时,Kibana 使用主机的主机名来连接 Kibana 实例。
kibana.index:
默认值: ".kibana" Kibana 使用 Elasticsearch 中的索引来存储保存的检索,可视化控件以及仪表板。如果没有索引,Kibana 会创建一个新的索引。
kibana.defaultAppId:
默认值: "discover" 默认加载的应用。
tilemap.url:
Kibana 用来在 tile 地图可视化组件中展示地图服务的 URL。默认时,Kibana 从外部的元数据服务读取 url,用户也可以覆盖该参数,使用自己的 tile 地图服务。例如:"https://tiles.elastic.co/v2/default/{z}/{x}/{y}.png?elastic_tile_service_tos=agree&my_app_name=kibana"
tilemap.options.minZoom:
默认值: 1 最小缩放级别。
tilemap.options.maxZoom:
默认值: 10 最大缩放级别。
tilemap.options.attribution:
默认值: "© [Elastic Tile Service](https://www.elastic.co/elastic-tile-service)" 地图属性字符串。
tilemap.options.subdomains:
服务使用的二级域名列表,用 {s} 指定二级域名的 URL 地址。
elasticsearch.username: 和 elasticsearch.password:
Elasticsearch 设置了基本的权限认证,该配置项提供了用户名和密码,用于 Kibana 启动时维护索引。Kibana 用户仍需要 Elasticsearch 由 Kibana 服务端代理的认证。
server.ssl.enabled
默认值: "false" 对到浏览器端的请求启用 SSL,设为 true 时, server.ssl.certificate 和 server.ssl.key 也要设置。
server.ssl.certificate: 和 server.ssl.key:
PEM 格式 SSL 证书和 SSL 密钥文件的路径。
server.ssl.keyPassphrase
解密私钥的口令,该设置项可选,因为密钥可能没有加密。
server.ssl.certificateAuthorities
可信任 PEM 编码的证书文件路径列表。
server.ssl.supportedProtocols
默认值: TLSv1、TLSv1.1、TLSv1.2 版本支持的协议,有效的协议类型: TLSv1 、 TLSv1.1 、 TLSv1.2 。
server.ssl.cipherSuites
默认值: ECDHE-RSA-AES128-GCM-SHA256, ECDHE-ECDSA-AES128-GCM-SHA256, ECDHE-RSA-AES256-GCM-SHA384, ECDHE-ECDSA-AES256-GCM-SHA384, DHE-RSA-AES128-GCM-SHA256, ECDHE-RSA-AES128-SHA256, DHE-RSA-AES128-SHA256, ECDHE-RSA-AES256-SHA384, DHE-RSA-AES256-SHA384, ECDHE-RSA-AES256-SHA256, DHE-RSA-AES256-SHA256, HIGH,!aNULL, !eNULL, !EXPORT, !DES, !RC4, !MD5, !PSK, !SRP, !CAMELLIA. 具体格式和有效参数可通过[OpenSSL cipher list format documentation](https://www.openssl.org/docs/man1.0.2/apps/ciphers.html#CIPHER-LIST-FORMAT) 获得。
elasticsearch.ssl.certificate: 和 elasticsearch.ssl.key:
可选配置项,提供 PEM格式 SSL 证书和密钥文件的路径。这些文件确保 Elasticsearch 后端使用同样的密钥文件。
elasticsearch.ssl.keyPassphrase
解密私钥的口令,该设置项可选,因为密钥可能没有加密。
elasticsearch.ssl.certificateAuthorities:
指定用于 Elasticsearch 实例的 PEM 证书文件路径。
elasticsearch.ssl.verificationMode:
默认值: full 控制证书的认证,可用的值有 none 、 certificate 、 full 。 full 执行主机名验证,certificate 不执行主机名验证。
elasticsearch.pingTimeout:
默认值: elasticsearch.requestTimeout setting 的值,等待 Elasticsearch 的响应时间。
elasticsearch.requestTimeout:
默认值: 30000 等待后端或 Elasticsearch 的响应时间,单位微秒,该值必须为正整数。
elasticsearch.requestHeadersWhitelist:
默认值: [ 'authorization' ] Kibana 客户端发送到 Elasticsearch 头体,发送 no 头体,设置该值为[]。
elasticsearch.customHeaders:
默认值: {} 发往 Elasticsearch的头体和值, 不管 elasticsearch.requestHeadersWhitelist 如何配置,任何自定义的头体不会被客户端头体覆盖。
elasticsearch.shardTimeout:
默认值: 0 Elasticsearch 等待分片响应时间,单位微秒,0即禁用。
elasticsearch.startupTimeout:
默认值: 5000 Kibana 启动时等待 Elasticsearch 的时间,单位微秒。
pid.file:
指定 Kibana 的进程 ID 文件的路径。
logging.dest:
默认值: stdout 指定 Kibana 日志输出的文件。
logging.silent:
默认值: false 该值设为 true 时,禁止所有日志输出。
logging.quiet:
默认值: false 该值设为 true 时,禁止除错误信息除外的所有日志输出。
logging.verbose
默认值: false 该值设为 true 时,记下所有事件包括系统使用信息和所有请求的日志。
ops.interval
默认值: 5000 设置系统和进程取样间隔,单位微妙,最小值100。
status.allowAnonymous
默认值: false 如果启用了权限,该项设置为 true 即允许所有非授权用户访问 Kibana 服务端 API 和状态页面。
cpu.cgroup.path.override
如果挂载点跟 /proc/self/cgroup 不一致,覆盖 cgroup cpu 路径。
cpuacct.cgroup.path.override
如果挂载点跟 /proc/self/cgroup 不一致,覆盖 cgroup cpuacct 路径。
console.enabled
默认值: true 设为 false 来禁用控制台,切换该值后服务端下次启动时会重新生成资源文件,因此会导致页面服务有点延迟。
elasticsearch.tribe.url:
Elasticsearch tribe 实例的 URL,用于所有查询。
elasticsearch.tribe.username: 和 elasticsearch.tribe.password:
Elasticsearch 设置了基本的权限认证,该配置项提供了用户名和密码,用于 Kibana 启动时维护索引。Kibana 用户仍需要 Elasticsearch 由 Kibana 服务端代理的认证。
elasticsearch.tribe.ssl.certificate: 和 elasticsearch.tribe.ssl.key:
可选配置项,提供 PEM 格式 SSL 证书和密钥文件的路径。这些文件确保 Elasticsearch 后端使用同样的密钥文件。
elasticsearch.tribe.ssl.keyPassphrase
解密私钥的口令,该设置项可选,因为密钥可能没有加密。
elasticsearch.tribe.ssl.certificateAuthorities:
指定用于 Elasticsearch tribe 实例的 PEM 证书文件路径。
elasticsearch.tribe.ssl.verificationMode:
默认值: full 控制证书的认证,可用的值有 none 、 certificate 、 full 。 full 执行主机名验证, certificate 不执行主机名验证。
elasticsearch.tribe.pingTimeout:
默认值: elasticsearch.tribe.requestTimeout setting 的值,等待 Elasticsearch 的响应时间。
elasticsearch.tribe.requestTimeout:
Default: 30000 等待后端或 Elasticsearch 的响应时间,单位微秒,该值必须为正整数。
elasticsearch.tribe.requestHeadersWhitelist:
默认值: [ 'authorization' ] Kibana 发往 Elasticsearch 的客户端头体,发送 no 头体,设置该值为[]。
elasticsearch.tribe.customHeaders:
默认值: {} 发往 Elasticsearch的头体和值,不管 elasticsearch.tribe.requestHeadersWhitelist 如何配置,任何自定义的头体不会被客户端头体覆盖。访问 Kibana
Kibana 是一个 web 应用,可以通过5601端口访问。只需要在浏览器中指定 Kibana 运行的机器,然后指定端口号即可。例如, localhost:5601 或者 http://YOURDOMAIN.com:5601 。
当访问 Kibana 时,Discover 页默认会加载默认的索引模式。时间过滤器设置的时间为过去15分钟,查询设置为匹配所有 (\*) 。
如果看不到任何文档,试着把时间过滤器的范围调大。如果还是看不到任何结果,很可能是根本就 没有 任何文档。
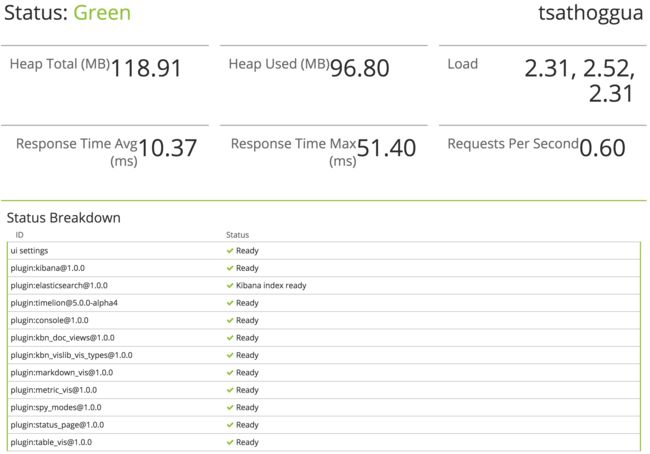
检查 Kibana 状态
您可以通过 localhost:5601/status 来访问 Kibana 的服务器状态页,状态页展示了服务器资源使用情况和已安装插件列表。
加载示例数据
从官方教程下载数据集:
- 威廉·莎士比亚全集,解析成合适的字段。点击这里下载这个数据集: shakespeare.json.
- 一组虚构的账户与随机生成的数据。点击这里下载这个数据集: accounts.zip.
- 一组随机生成的日志文件。点击这里下载这个数据集: logs.jsonl.gz.
莎士比亚数据集的组织方式如下:
{
"line_id": INT,
"play_name": "String",
"speech_number": INT,
"line_number": "String",
"speaker": "String",
"text_entry": "String",
}帐户数据集的组织方式如下:
{
"account_number": INT,
"balance": INT,
"firstname": "String",
"lastname": "String",
"age": INT,
"gender": "M or F",
"address": "String",
"employer": "String",
"email": "String",
"city": "String",
"state": "String"
}日志数据集的结构有许多不同的字段,以下是其中比较重要的字段:
{
"memory": INT,
"geo.coordinates": "geo_point"
"@timestamp": "date"
}在莎士比亚和日志数据集加载之前,我们需要为字段设置 映射。 映射把索引中的文档按逻辑分组并指定了字段的属性,比如字段的可搜索性或者该字段是否是 tokenized ,或分解成单独的单词。
使用head创建一个莎士比亚数据集的映射:
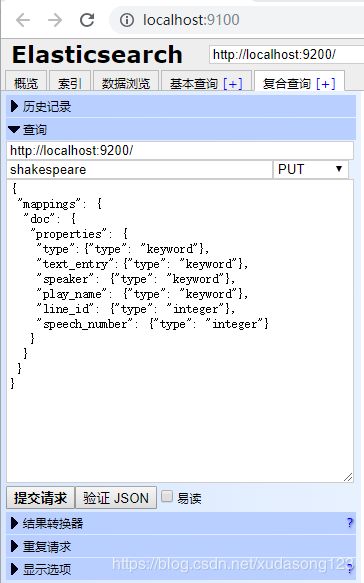
这个映射指定了数据集的以下特点:
- 因为 speaker 和 play_name 字段是关键字字段,它们不需要分析。字符串即使包含多个词也仍被视为一个整体。
- line_id 和 speech_number 字段是整数。
日志数据集映射需要利用 geo_point 类型来标记经度/纬度地理位置字段。
在head使用下面的命令来为日志建立 geo_point 映射:
logstash-2015.05.18 put
logstash-2015.05.19 put
logstash-2015.05.20 put
创建三个:
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
账户数据集不需要任何映射,基于这一点我们准备用 Elasticsearch bulk API 来加载数据集,Luninx环境下命令如下:
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary @accounts.json
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/shakespeare/doc/_bulk?pretty' --data-binary @shakespeare_6.0.json
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/_bulk?pretty' --data-binary @logs.jsonl使用下面的命令来验证加载是否成功:
GET /_cat/indices?vWindows环境下,用cmd定位为示例数据的位置,使用如下命令:
curl -H "Content-Type: application/x-ndjson" -XPOST "http://localhost:9200/shakespeare/doc/_bulk?pretty" --data-binary "@shakespeare_6.0.json"
curl -H "Content-Type: application/x-ndjson" -XPOST "http://localhost:9200/bank/account/_bulk?pretty" --data-binary "@accounts.json"
curl -H "Content-Type: application/x-ndjson" -XPOST "http://localhost:9200/_bulk?pretty" --data-binary "@logs.jsonl"
使用下面的命令来验证加载是否成功:
curl "http://localhost:9200/_cat/indices?v"您应该会看到类似下面的输出:
health status index pri rep docs.count docs.deleted store.size pri.store.size
yellow open bank 5 1 1000 0 418.2kb 418.2kb
yellow open shakespeare 5 1 111396 0 17.6mb 17.6mb
yellow open logstash-2015.05.18 5 1 4631 0 15.6mb 15.6mb
yellow open logstash-2015.05.19 5 1 4624 0 15.7mb 15.7mb
yellow open logstash-2015.05.20 5 1 4750 0 16.4mb 用Elasticsearch连接到Kibana
在你开始用Kibana之前,你需要告诉Kibana你想探索哪个Elasticsearch索引。第一次访问Kibana是,系统会提示你定义一个索引模式以匹配一个或多个索引的名字。
(提示:默认情况下,Kibana连接允许在localhost上的Elasticsearch实例。为了连接到一个不同的Elasticsearch实例,修改kabana.yml中Elasticsearch的URL,然后重启Kibana。)
为了配置你想要用Kibana访问的Elasticsearch索引:
1、访问Kibana UI。例如,localhost:56011 或者 http://YOURDOMAIN.com:5601
2、指定一个索引模式来匹配一个或多个你的Elasticsearch索引。当你指定了你的索引模式以后,任何匹配到的索引都将被展示出来。
(画外音:*匹配0个或多个字符; 指定索引默认是为了匹配索引,确切的说是匹配索引名字)
3、点击“Next Step”以选择你想要用来执行基于时间比较的包含timestamp字段的索引。如果你的索引没有基于时间的数据,那么选择“I don’t want to use the Time Filter”选项。
4、点击“Create index pattern”按钮来添加索引模式。第一个索引模式自动配置为默认的索引默认,以后当你有多个索引模式的时候,你就可以选择将哪一个设为默认。(提示:Management > Index Patterns)
Discover
你可以从Discover页面交互式的探索你的数据。你可以访问与所选择的索引默认匹配的每个索引中的每个文档。你可以提交查询请求,过滤搜索结构,并查看文档数据。你也可以看到匹配查询请求的文档数量,以及字段值统计信息。如果你选择的索引模式配置了time字段,则文档随时间的分布将显示在页面顶部的直方图中。


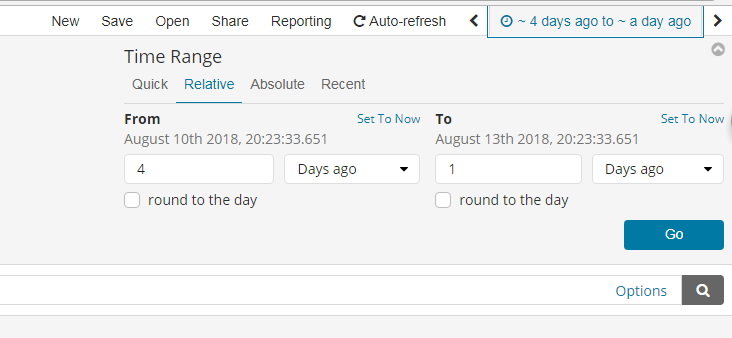
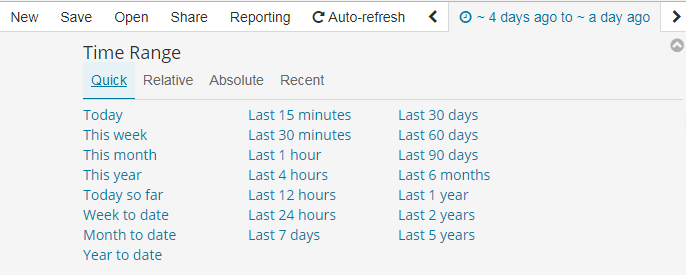
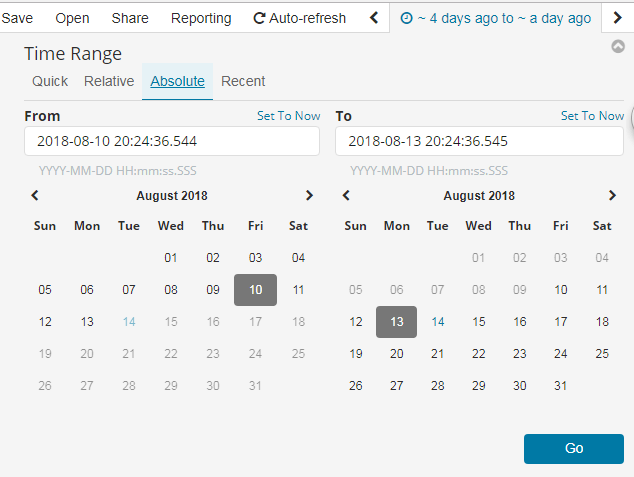
1. 设置时间过滤
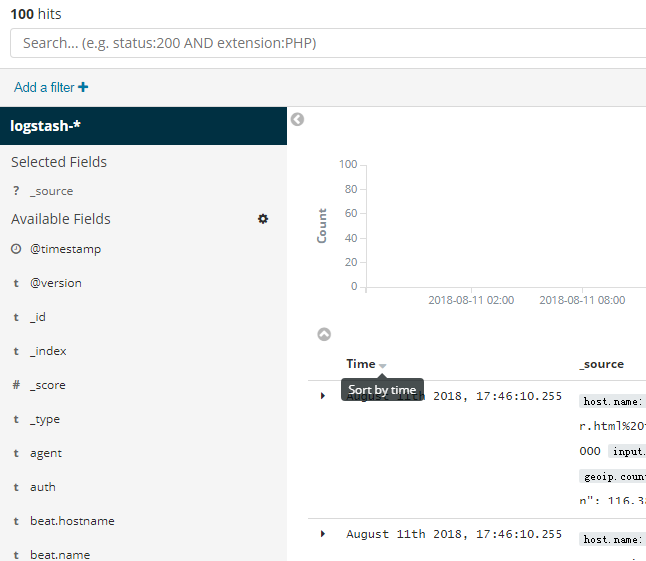
2. 搜索数据
你可以在搜索框中输入查询条件来查询当前索引模式匹配的索引。在查询的时候,你可以使用Kibana标准的查询语言(基于Lucene的查询语法)或者完全基于JSON的Elasticsearch查询语言DSL。Kibana查询语言可以使用自动完成和简化的查询语法作为实验特性,您可以在查询栏的“选项”菜单下进行选择。
当你提交一个查询请求时,直方图、文档表和字段列表都会更新,以反映搜索结果。命中(匹配到的文档)总数会显示在工具栏中。文档表格中显示了前500个命中。默认情况下,按时间倒序排列,首先显示最新的文档。你可以通过点击“Time”列来逆转排序顺序。

2.1. Lucene查询语法
Kibana查询语言基于Lucene查询语法。下面是一些提示,可能会帮到你:
- 为了执行一个文本搜索,可以简单的输入一个文本字符串。例如,如果你想搜索web服务器的日志,你可以输入关键字"safari",这样你就可以搜索到所有有关"safari"的字段
- 为了搜索一个特定字段的特定值,可以用字段的名称作为前缀。例如,你输入"status:200",将会找到所有status字段的值是200的文档
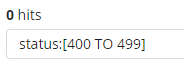
- 为了搜索一个范围值,你可以用括号范围语法,[START_VALUE TO END_VALUE]。例如,为了找到状态码是4xx的文档,你可以输入status:[400 TO 499]
- 为了指定更改复杂的查询条件,你可以用布尔操作符 AND , OR , 和 NOT。例如,为了找到状态码是4xx并且extension字段是php或者html的文档,你可以输入status:[400 TO 499] AND (extension:php OR extension:html)


2.2. Kibana查询语法增强
新的更简单的语法
如果你熟悉Kibana的旧Lucene查询语法,那么你应该对这种新的语法也不会陌生。基本原理保持不变,我们只是简单地改进了一些东西,使查询语言更易于使用。
response:200 将匹配response字段的值是200的文档
用引号引起来的一段字符串叫短语搜索。例如,message:"Quick brown fox" 将在message字段中搜索"quick brown fox"这个短语。如果没有引号,将会匹配到包含这些词的所有文档,而不管它们的顺序如何。这就意味着,会匹配到"Quick brown fox",而不会匹配"quick fox brown"。(画外音:引号引起来作为一个整体)
查询解析器将不再基于空格进行分割。多个搜索项必须由明确的布尔运算符分隔。注意,布尔运算符不区分大小写。
在Lucene中,response:200 extension:php 等价于 response:200 and extension:php。这将匹配response字段值匹配200并且extenion字段值匹配php的文档。
如果我们把中间换成or,那么response:200 or extension:php将匹配response字段匹配200 或者 extension字段匹配php的文档。
默认情况下,and 比 or 具有更高优先级。
response:200 and extension:php or extension:css 将匹配response是200并且extension是php,或者匹配extension是css而response任意
括号可以改变这种优先级
response:200 and (extension:php or extension:css) 将匹配response是200并且extension是php或者css的文档
还有一种简写的方式:
response:(200 or 404) 将匹配response字段是200或404的文档。字符值也可以是多个,比如:tags:(success and info and security)
还可以用not
not response:200 将匹配response不是200的文档
response:200 and not (extension:php or extension:css) 将匹配response是200并且extension不是php也不是css的文档
范围检索和Lucene有一点点不同
代替 byte:>1000,我们用byte > 1000
>, >=, <, <= 都是有效的操作符
response:* 将匹配所有存在response字段的文档
通配符查询也是可以的。machine.os:win* 将匹配machine.os字段以win开头的文档,像"windows 7"和"windows 10"这样的值都会被匹配到。
通配符也允许我们一次搜索多个字段,例如,假设我们有machine.os和machine.os.keyword两个字段,我们想要搜索这两个字段都有"windows 10",那么我们可以这样写"machine.os*:windows 10"
2.3. 刷新搜索结果
3. 按字段过滤
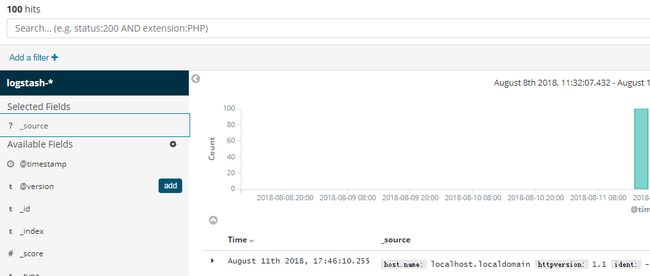

以上是控制列表显示哪些字段,还有一种方式是在查看文档数据的时候点那个像书一样的小图标
删除也是可以的

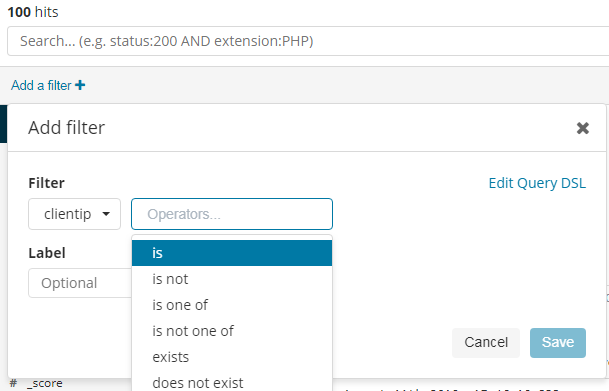
我们还可以编辑一个DSL查询语句,用于过滤筛选,例如
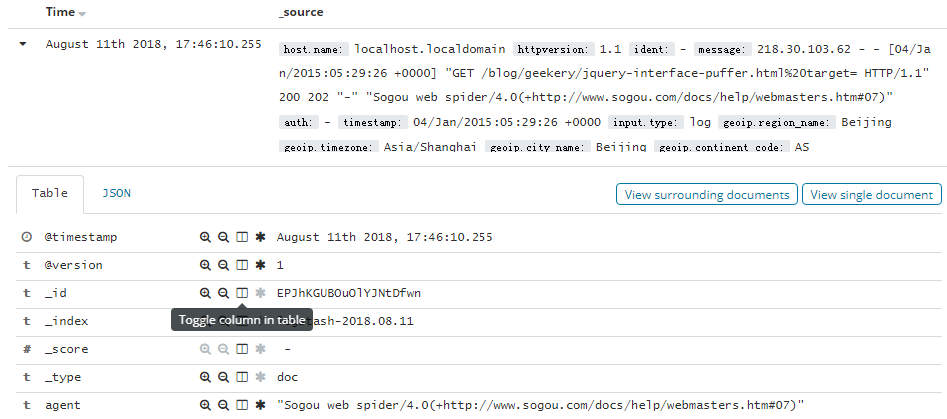
4. 查看文档数据
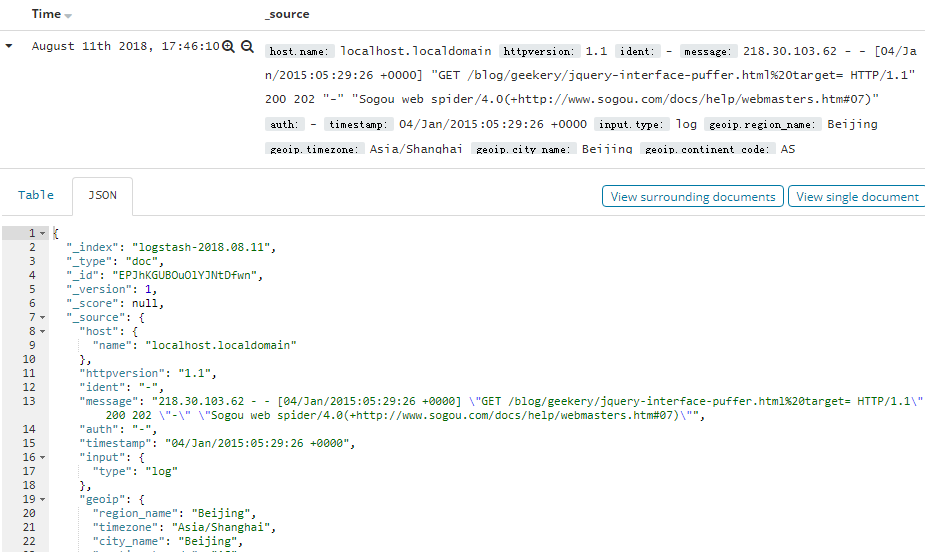
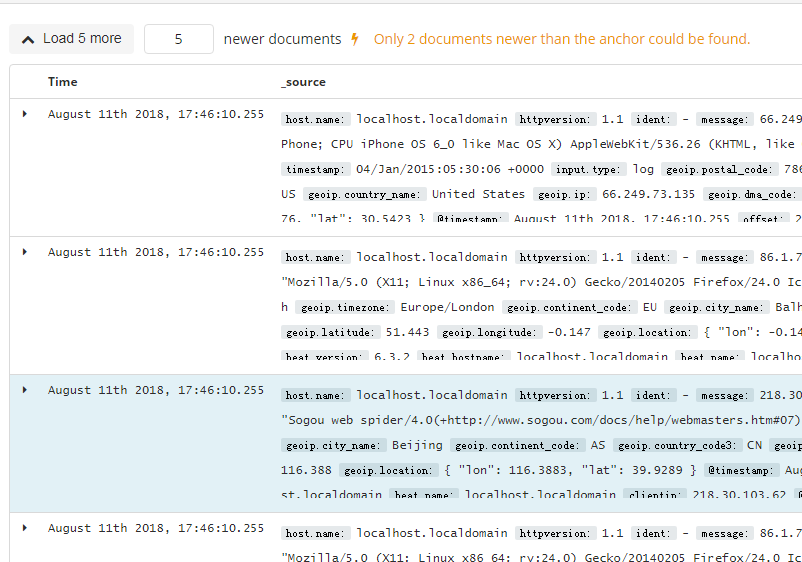
5. 查看文档上下文

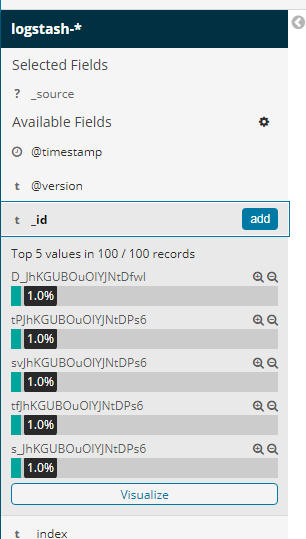
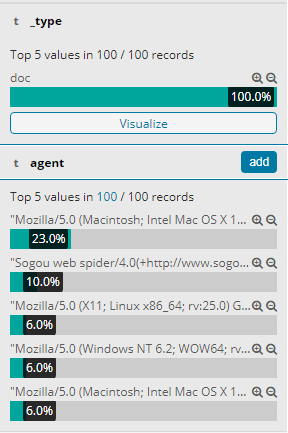
6. 查看字段数据统计
Visualize
Visualize使得你可以创建在你的Elasticsearch索引中的数据的可视化效果。然后,你可以构建dashboard来展示相关可视化。
Kibana可视化是基于Elasticsearch查询的。通过用一系列的Elasticsearch聚集来提取并处理你的数据,你可以创建图片来线上你需要了解的趋势、峰值和低点。
1. 创建一个可视化
为了创建一个可视化的视图:
第1步:点击左侧导航条中的“Visualize”按钮
第2步:点击“Create new visualization”按钮或者加号(+)按钮
第3步:选择一个可视化类型
第4步:指定一个搜索查询来检索可视化数据
第5步:在可视化的构建器中选择Y轴的聚合操作。例如,sum,average,count等等
第6步:设置X轴
例如:



更多请看这里
https://www.elastic.co/guide/en/kibana/current/createvis.html
https://www.elastic.co/guide/en/kibana/current/xy-chart.html
https://www.elastic.co/guide/en/kibana/current/visualize.html
Dashboard
Kibana仪表板显示可视化和搜索的集合。你可以安排、调整和编辑仪表板内容,然后保存仪表板以便共享它。
1. 构建一个Dashboard
第1步:在导航条上点击“Dashboard”
第2步:点击“Create new dashboard”或者“加号(+)”按钮
第3步:点击“Add”按钮
第4步:为了添加一个可视化,从可视化列表中选择一个,或者点击“Add new visualization”按钮新创建一个
第5步:为了添加一个已保存的查询,点击“Saved Search”选项卡,然后从列表中选择一个
第6步:当你完成添加并且调整了dashboard的内容后,去顶部菜单栏,点击“Save”,然后输入一个名字。
默认情况下,Kibana仪表板使用浅色主题。要使用深色主题,单击“选项”并选择“使用深色主题”。要将dark主题设置为默认,请转到管理>Management > Advanced ,并将dashboard:defaultDarkTheme设置为On。
Monitoring
Elasticsearch控制台打印日志 [2018-08-15T14:48:26,874][INFO ][o.e.c.m.MetaDataCreateIndexService] [Px524Ts] [.monitoring-kibana-6-2018.08.15] creating index, cause [auto(bulk api)], templates [.monitoring-kibana], shards [1]/[0], mappings [doc] Kibana控制台打印日志 log [03:26:53.605] [info][license][xpack] Imported license information from Elasticsearch for the [monitoring] cluster: mode: basic | status: active
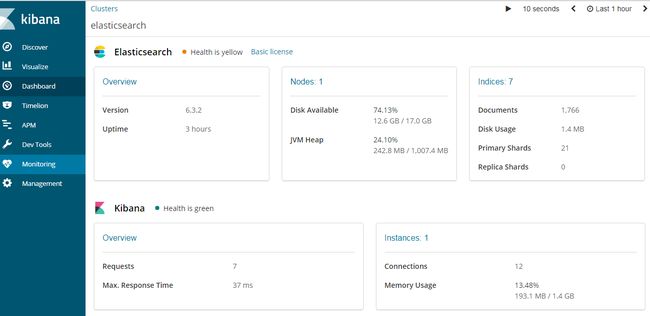
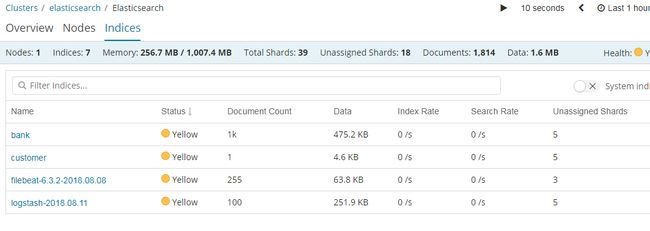
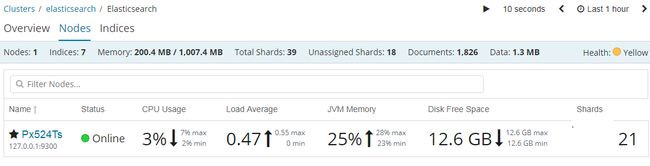
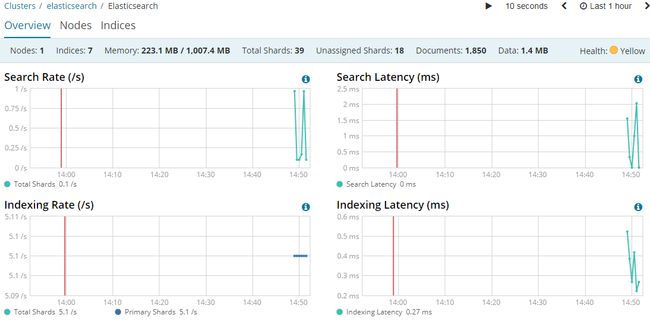
https://www.elastic.co/guide/en/kibana/current/elasticsearch-metrics.html
参考文档:
Kibana 用户手册;
Kibana(一张图片胜过千万行日志);
Kibana入门教程