Faster RCNN paper https://arxiv.org/abs/1506.01497
Faster RCNN 可以看成 Region Proposal + RCNN相结合的一个网络模型,即区域生成网络RPN+ 目标识别 image classifier。
Faster RCNN 在某种意义上解决了Region Proposal耗费大量时间的问题。
具体流程如下:
- 通过特征提取层,即一系列conv, relu, pooling得到feature map, 该map被用于RPN层以及后续的全连接层。
- 在feature map的每个像素上生成多个Anchor(定义请看下文)。
- 利用RPN层生成region proposals,该层主要有两个目的: 1, 通过softmax判断anchors属于foreground 还是background, 再利用bounding box regression 修正anchors获取相对精确的proposals。
- 从之前生成的feature map 和RPN层获取的 proposals获取proposal feature map, 然后经过ROI Pooling层。
- 最后将ROI Pooling层获取的结果通过全连接层来计算proposals的类别,同时再次bounding box regression获取检测框的最终位置。

下面我们从源码的角度来分析这些模块
一、数据载入
tools/trainval_net.py
# train set
imdb, roidb = combined_roidb(args.imdb_name)
print('{:d} roidb entries'.format(len(roidb)))
- imdb:是一个base class, 实例有pascal_voc、coco。主要对所有图片的类别,名称,路径做了一个汇总。
- roidb:是imdb的一个属性,里面是一个dictionary, 包含了它的GTbox,真实标签的信息以及翻转标签。
tools/trainval_net.py
def combined_roidb(imdb_names):
"""
Combine multiple roidbs
"""
def get_roidb(imdb_name):
imdb = get_imdb(imdb_name)
print('Loaded dataset `{:s}` for training'.format(imdb.name))
imdb.set_proposal_method(cfg.TRAIN.PROPOSAL_METHOD)
print('Set proposal method: {:s}'.format(cfg.TRAIN.PROPOSAL_METHOD))
roidb = get_training_roidb(imdb)
return roidb
roidbs = [get_roidb(s) for s in imdb_names.split('+')]
roidb = roidbs[0]
if len(roidbs) > 1:
for r in roidbs[1:]:
roidb.extend(r)
tmp = get_imdb(imdb_names.split('+')[1])
imdb = datasets.imdb.imdb(imdb_names, tmp.classes)
else:
imdb = get_imdb(imdb_names)
return imdb, roidb
这里的参数imdb_names是启动的时指定的,例如pascal_voc, pascal_voc_0712, coco
lib/datasets/factory.py
# Set up voc__
for year in ['2007', '2012']:
for split in ['train', 'val', 'trainval', 'test']:
name = 'voc_{}_{}'.format(year, split)
__sets[name] = (lambda split=split, year=year: pascal_voc(split, year))
for year in ['2007', '2012']:
for split in ['train', 'val', 'trainval', 'test']:
name = 'voc_{}_{}_diff'.format(year, split)
__sets[name] = (lambda split=split, year=year: pascal_voc(split, year, use_diff=True))
# Set up coco_2014_
for year in ['2014']:
for split in ['train', 'val', 'minival', 'valminusminival', 'trainval']:
name = 'coco_{}_{}'.format(year, split)
__sets[name] = (lambda split=split, year=year: coco(split, year))
# Set up coco_2015_
for year in ['2015']:
for split in ['test', 'test-dev']:
name = 'coco_{}_{}'.format(year, split)
__sets[name] = (lambda split=split, year=year: coco(split, year))
def get_imdb(name):
"""Get an imdb (image database) by name."""
if name not in __sets:
raise KeyError('Unknown dataset: {}'.format(name))
return __sets[name]()
工厂类,负责生成不同的imdb的实例,我们以pascal_voc为例。
lib/datasets/pascal_voc.py
class pascal_voc(imdb):
def __init__(self, image_set, year, use_diff=False):
name = 'voc_' + year + '_' + image_set
if use_diff:
name += '_diff'
imdb.__init__(self, name)
self._year = year
self._image_set = image_set
self._devkit_path = self._get_default_path()
self._data_path = os.path.join(self._devkit_path, 'VOC' + self._year)
self._classes = ('__background__', # always index 0
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
self._class_to_ind = dict(list(zip(self.classes, list(range(self.num_classes)))))
self._image_ext = '.jpg'
self._image_index = self._load_image_set_index()
# Default to roidb handler
self._roidb_handler = self.gt_roidb
self._salt = str(uuid.uuid4())
self._comp_id = 'comp4'
# PASCAL specific config options
self.config = {'cleanup': True,
'use_salt': True,
'use_diff': use_diff,
'matlab_eval': False,
'rpn_file': None}
assert os.path.exists(self._devkit_path), \
'VOCdevkit path does not exist: {}'.format(self._devkit_path)
assert os.path.exists(self._data_path), \
'Path does not exist: {}'.format(self._data_path)
这个类有两个蛮重要的成员
- self._image_index: 图片数据集(例如 /VOCdevkit2007/VOC2007/ImageSets/Main/val.txt)中的索引数组。
- self._roidb_handler: ground truth感兴趣的区域,如果存在缓存文件,从缓存中读取,否则调用self._load_pascal_annotation()从xml文件中读取图像的标注。
lib/datasets/pascal_voc.py
def _load_image_set_index(self):
"""
Load the indexes listed in this dataset's image set file.
"""
# Example path to image set file:
# self._devkit_path + /VOCdevkit2007/VOC2007/ImageSets/Main/val.txt
image_set_file = os.path.join(self._data_path, 'ImageSets', 'Main',
self._image_set + '.txt')
assert os.path.exists(image_set_file), \
'Path does not exist: {}'.format(image_set_file)
with open(image_set_file) as f:
image_index = [x.strip() for x in f.readlines()]
return image_index
lib/datasets/pascal_voc.py
def gt_roidb(self):
"""
Return the database of ground-truth regions of interest.
This function loads/saves from/to a cache file to speed up future calls.
"""
cache_file = os.path.join(self.cache_path, self.name + '_gt_roidb.pkl')
if os.path.exists(cache_file):
with open(cache_file, 'rb') as fid:
try:
roidb = pickle.load(fid)
except:
roidb = pickle.load(fid, encoding='bytes')
print('{} gt roidb loaded from {}'.format(self.name, cache_file))
return roidb
gt_roidb = [self._load_pascal_annotation(index)
for index in self.image_index]
with open(cache_file, 'wb') as fid:
pickle.dump(gt_roidb, fid, pickle.HIGHEST_PROTOCOL)
print('wrote gt roidb to {}'.format(cache_file))
return gt_roidb
函数返回一个字典:
- boxes: 二维数组 [num_objs,4], 每行4个值分别表示边界框的左上和右下角坐标。
- gt_classes: 一位数组 [num_objs] 每行的数字代表类别。
- gt_overlaps: 二维数组[num_objs,num_classes] 每行表示一个物体,在该物体对应的哪一列设为1.0。
- flipped: 是否经过了翻转。
- seg_areas: 以为数组[num_objs] 边界框包含区域的面积。
lib/datasets/pascal_voc.py
def _load_pascal_annotation(self, index):
"""
Load image and bounding boxes info from XML file in the PASCAL VOC
format.
"""
filename = os.path.join(self._data_path, 'Annotations', index + '.xml')
tree = ET.parse(filename)
objs = tree.findall('object')
if not self.config['use_diff']:
# Exclude the samples labeled as difficult
non_diff_objs = [
obj for obj in objs if int(obj.find('difficult').text) == 0]
# if len(non_diff_objs) != len(objs):
# print 'Removed {} difficult objects'.format(
# len(objs) - len(non_diff_objs))
objs = non_diff_objs
num_objs = len(objs)
boxes = np.zeros((num_objs, 4), dtype=np.uint16)
gt_classes = np.zeros((num_objs), dtype=np.int32)
overlaps = np.zeros((num_objs, self.num_classes), dtype=np.float32)
# "Seg" area for pascal is just the box area
seg_areas = np.zeros((num_objs), dtype=np.float32)
# Load object bounding boxes into a data frame.
for ix, obj in enumerate(objs):
bbox = obj.find('bndbox')
# Make pixel indexes 0-based
x1 = float(bbox.find('xmin').text) - 1
y1 = float(bbox.find('ymin').text) - 1
x2 = float(bbox.find('xmax').text) - 1
y2 = float(bbox.find('ymax').text) - 1
cls = self._class_to_ind[obj.find('name').text.lower().strip()]
boxes[ix, :] = [x1, y1, x2, y2]
gt_classes[ix] = cls
overlaps[ix, cls] = 1.0
seg_areas[ix] = (x2 - x1 + 1) * (y2 - y1 + 1)
overlaps = scipy.sparse.csr_matrix(overlaps)
return {'boxes': boxes,
'gt_classes': gt_classes,
'gt_overlaps': overlaps,
'flipped': False,
'seg_areas': seg_areas}
方法def get_roidb(imdb_name)中还有一个重要的步骤: roidb = get_training_roidb(imdb)
下面的函数返回一个用于训练的roidb
lib/model/train_val.py
def get_training_roidb(imdb):
"""Returns a roidb (Region of Interest database) for use in training."""
if cfg.TRAIN.USE_FLIPPED:
print('Appending horizontally-flipped training examples...')
imdb.append_flipped_images()
print('done')
print('Preparing training data...')
rdl_roidb.prepare_roidb(imdb)
print('done')
return imdb.roidb
下面的函数就是将图片做一个翻转,并且添加到原来的roidb中
lib/datasets/imdb.py
def append_flipped_images(self):
num_images = self.num_images
widths = self._get_widths()
for i in range(num_images):
boxes = self.roidb[i]['boxes'].copy()
oldx1 = boxes[:, 0].copy()
oldx2 = boxes[:, 2].copy()
boxes[:, 0] = widths[i] - oldx2 - 1
boxes[:, 2] = widths[i] - oldx1 - 1
assert (boxes[:, 2] >= boxes[:, 0]).all()
entry = {'boxes': boxes,
'gt_overlaps': self.roidb[i]['gt_overlaps'],
'gt_classes': self.roidb[i]['gt_classes'],
'flipped': True}
self.roidb.append(entry)
self._image_index = self._image_index * 2
将之前的生成的roidb转换成一个可以用来训练的roidb,添加了一些元数据
- max_classes: 图片的类别,由于使用的是ground truth,所以这里的类别就是物体自己的类别。
- max_overlaps: 表示物体的框架与某个物体边界框的重合度,这里自己和自己重合了为1,不过我们下面rpn会用到它。
lib/roi_data_layer/roidb.py
def prepare_roidb(imdb):
"""Enrich the imdb's roidb by adding some derived quantities that
are useful for training. This function precomputes the maximum
overlap, taken over ground-truth boxes, between each ROI and
each ground-truth box. The class with maximum overlap is also
recorded.
"""
roidb = imdb.roidb
if not (imdb.name.startswith('coco')):
sizes = [PIL.Image.open(imdb.image_path_at(i)).size
for i in range(imdb.num_images)]
for i in range(len(imdb.image_index)):
roidb[i]['image'] = imdb.image_path_at(i)
if not (imdb.name.startswith('coco')):
roidb[i]['width'] = sizes[i][0]
roidb[i]['height'] = sizes[i][1]
# need gt_overlaps as a dense array for argmax
gt_overlaps = roidb[i]['gt_overlaps'].toarray()
# max overlap with gt over classes (columns)
max_overlaps = gt_overlaps.max(axis=1)
# gt class that had the max overlap
max_classes = gt_overlaps.argmax(axis=1)
roidb[i]['max_classes'] = max_classes
roidb[i]['max_overlaps'] = max_overlaps
# sanity checks
# max overlap of 0 => class should be zero (background)
zero_inds = np.where(max_overlaps == 0)[0]
assert all(max_classes[zero_inds] == 0)
# max overlap > 0 => class should not be zero (must be a fg class)
nonzero_inds = np.where(max_overlaps > 0)[0]
assert all(max_classes[nonzero_inds] != 0)
二、特征提取
残差神经网络推荐大家看一下这篇paper https://arxiv.org/abs/1512.03385
本文不深挖,只从代码的实现去简单的阐述一下这个网络。
在计算机视觉图像处理中,普遍认为随着网络的加深,我们可以获取更加高级的“特征”,然而梯度弥散/爆炸导致了深度的网络无法收敛,虽然一些方法可以弥补,例如Batch Normalization,选择合适的激活函数,梯度剪裁,使得可以收敛的网络深度提升为原来的十倍,然而网络性能却开始退化,反而导致了更大的误差,如下图所示:

- 梯度弥散: 很大程度是来源于激活函数的“饱和”。在back propagation(反向传播)的过程中需要计算激活函数的导数,一旦卷积核的输出落入函数的饱和区,它的梯度将会变得非常的小。使用反向传播传递梯度的时候,随着传播的深度加深,梯度的幅度会急剧变小,导致浅层的神经网络元的权重更新变得非常缓慢,学习效率就会降低。
- 梯度爆炸: 情况与梯度弥散相反,梯度在传播过程中大幅增长,导致了在极端情况下权重变得非常大以致溢出,使网络非常不稳定。
- 归一化(Batch Normalization): 可以说是深度学习发展以来提出的最重要成果之一,还是推荐大家自己找资料,仔细了解一些这个技术。简而言之就是对每一层的输出进行规范化,让均值和方差一致,消除了权重带来的放大和缩小的影响,这样一来不仅解决了梯度弥散和爆炸问题,还加快了网络的收敛,可以理解为BN将输出从饱和区拉到了非饱和区。
- 梯度剪切: 这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。这可以防止梯度爆炸。
ResNet允许深度尽可能的加深,且不影响网络的性能,它的具体结构如下:
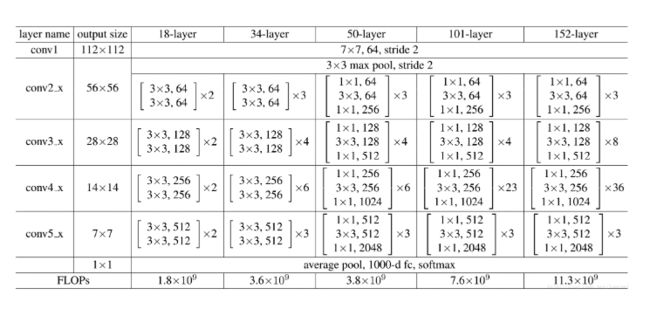
特征提取网路我选择的是深度残差网络(residual network), 层数为101。
tools/trainval_net.py
# load network
if args.net == 'vgg16':
net = vgg16()
elif args.net == 'res50':
net = resnetv1(num_layers=50)
elif args.net == 'res101':
net = resnetv1(num_layers=101)
elif args.net == 'res152':
net = resnetv1(num_layers=152)
elif args.net == 'mobile':
net = mobilenetv1()
else:
raise NotImplementedError
resnetv1是Network的一个实例,下面是初始化的代码
- Network 是特征提取网络的基类,里面提供了一些成员来记录Anchors,loss,layers,图片,训练,回归的一些信息, 还有一些训练神经网络常用的方法, 例如fully connection layer, max pooling layer, dropout layer 以及一些激活函数和loss function, 还有一些专门用于faster rcnn的函数, region proposal, region classification, proposal layer等, 这个大家自己去看源码。
ResNet 101的实现如下(我打算十一月更新一篇文章专门介绍ResNet的实现,faster-rcnn-tf源码里直接用的tensorflow.contrib.slim.python.slim.nets.resnet_v1.resnet_v1_block):
lib/nets/resnet_v1.py
class resnetv1(Network):
def __init__(self, num_layers=50):
Network.__init__(self)
self._feat_stride = [16, ]
self._feat_compress = [1. / float(self._feat_stride[0]), ]
self._num_layers = num_layers
self._scope = 'resnet_v1_%d' % num_layers
self._decide_blocks()
def _decide_blocks(self):
# choose different blocks for different number of layers
if self._num_layers == 50:
self._blocks = [resnet_v1_block('block1', base_depth=64, num_units=3, stride=2),
resnet_v1_block('block2', base_depth=128, num_units=4, stride=2),
# use stride 1 for the last conv4 layer
resnet_v1_block('block3', base_depth=256, num_units=6, stride=1),
resnet_v1_block('block4', base_depth=512, num_units=3, stride=1)]
elif self._num_layers == 101:
self._blocks = [resnet_v1_block('block1', base_depth=64, num_units=3, stride=2),
resnet_v1_block('block2', base_depth=128, num_units=4, stride=2),
# use stride 1 for the last conv4 layer
resnet_v1_block('block3', base_depth=256, num_units=23, stride=1),
resnet_v1_block('block4', base_depth=512, num_units=3, stride=1)]
elif self._num_layers == 152:
self._blocks = [resnet_v1_block('block1', base_depth=64, num_units=3, stride=2),
resnet_v1_block('block2', base_depth=128, num_units=8, stride=2),
# use stride 1 for the last conv4 layer
resnet_v1_block('block3', base_depth=256, num_units=36, stride=1),
resnet_v1_block('block4', base_depth=512, num_units=3, stride=1)]
else:
# other numbers are not supported
raise NotImplementedError
三、训练
当我们准备好训练数据和神经网络后,就可以开始我们的训练
tools/trainval_net.py
train_net(net, imdb, roidb, valroidb, output_dir, tb_dir,
pretrained_model=args.weight,
max_iters=args.max_iters)
首先过滤掉不符合要求的roidb, 然后建立一个包装类SolverWrapper用于训练过程
lib/model/train_val.py
def train_net(network, imdb, roidb, valroidb, output_dir, tb_dir,
pretrained_model=None,
max_iters=40000):
"""Train a Faster R-CNN network."""
roidb = filter_roidb(roidb)
valroidb = filter_roidb(valroidb)
tfconfig = tf.ConfigProto(allow_soft_placement=True)
tfconfig.gpu_options.allow_growth = True
with tf.Session(config=tfconfig) as sess:
sw = SolverWrapper(sess, network, imdb, roidb, valroidb, output_dir, tb_dir,
pretrained_model=pretrained_model)
print('Solving...')
sw.train_model(sess, max_iters)
print('done solving')
def filter_roidb(roidb):
"""Remove roidb entries that have no usable RoIs."""
def is_valid(entry):
# Valid images have:
# (1) At least one foreground RoI OR
# (2) At least one background RoI
overlaps = entry['max_overlaps']
# find boxes with sufficient overlap
fg_inds = np.where(overlaps >= cfg.TRAIN.FG_THRESH)[0]
# Select background RoIs as those within [BG_THRESH_LO, BG_THRESH_HI)
bg_inds = np.where((overlaps < cfg.TRAIN.BG_THRESH_HI) &
(overlaps >= cfg.TRAIN.BG_THRESH_LO))[0]
# image is only valid if such boxes exist
valid = len(fg_inds) > 0 or len(bg_inds) > 0
return valid
num = len(roidb)
filtered_roidb = [entry for entry in roidb if is_valid(entry)]
num_after = len(filtered_roidb)
print('Filtered {} roidb entries: {} -> {}'.format(num - num_after,
num, num_after))
return filtered_roidb
接下来开始训练模型
lib/model/train_val.py
def train_model(self, sess, max_iters):
# Build data layers for both training and validation set
self.data_layer = RoIDataLayer(self.roidb, self.imdb.num_classes)
self.data_layer_val = RoIDataLayer(self.valroidb, self.imdb.num_classes, random=True)
# Construct the computation graph
lr, train_op = self.construct_graph(sess)
# Find previous snapshots if there is any to restore from
lsf, nfiles, sfiles = self.find_previous()
# Initialize the variables or restore them from the last snapshot
if lsf == 0:
rate, last_snapshot_iter, stepsizes, np_paths, ss_paths = self.initialize(sess)
else:
rate, last_snapshot_iter, stepsizes, np_paths, ss_paths = self.restore(sess,
str(sfiles[-1]),
str(nfiles[-1]))
timer = Timer()
iter = last_snapshot_iter + 1
last_summary_time = time.time()
# Make sure the lists are not empty
stepsizes.append(max_iters)
stepsizes.reverse()
next_stepsize = stepsizes.pop()
while iter < max_iters + 1:
# Learning rate
if iter == next_stepsize + 1:
# Add snapshot here before reducing the learning rate
self.snapshot(sess, iter)
rate *= cfg.TRAIN.GAMMA
sess.run(tf.assign(lr, rate))
next_stepsize = stepsizes.pop()
timer.tic()
# Get training data, one batch at a time
blobs = self.data_layer.forward()
now = time.time()
if iter == 1 or now - last_summary_time > cfg.TRAIN.SUMMARY_INTERVAL:
# Compute the graph with summary
rpn_loss_cls, rpn_loss_box, loss_cls, loss_box, total_loss, summary = \
self.net.train_step_with_summary(sess, blobs, train_op)
self.writer.add_summary(summary, float(iter))
# Also check the summary on the validation set
blobs_val = self.data_layer_val.forward()
summary_val = self.net.get_summary(sess, blobs_val)
self.valwriter.add_summary(summary_val, float(iter))
last_summary_time = now
else:
# Compute the graph without summary
rpn_loss_cls, rpn_loss_box, loss_cls, loss_box, total_loss = \
self.net.train_step(sess, blobs, train_op)
timer.toc()
# Display training information
if iter % (cfg.TRAIN.DISPLAY) == 0:
print('iter: %d / %d, total loss: %.6f\n >>> rpn_loss_cls: %.6f\n '
'>>> rpn_loss_box: %.6f\n >>> loss_cls: %.6f\n >>> loss_box: %.6f\n >>> lr: %f' % \
(iter, max_iters, total_loss, rpn_loss_cls, rpn_loss_box, loss_cls, loss_box, lr.eval()))
print('speed: {:.3f}s / iter'.format(timer.average_time))
# Snapshotting
if iter % cfg.TRAIN.SNAPSHOT_ITERS == 0:
last_snapshot_iter = iter
ss_path, np_path = self.snapshot(sess, iter)
np_paths.append(np_path)
ss_paths.append(ss_path)
# Remove the old snapshots if there are too many
if len(np_paths) > cfg.TRAIN.SNAPSHOT_KEPT:
self.remove_snapshot(np_paths, ss_paths)
iter += 1
if last_snapshot_iter != iter - 1:
self.snapshot(sess, iter - 1)
self.writer.close()
self.valwriter.close()
分下来开看这段代码, 我们可以总结出4个阶段:
- 建立数据输入层用于训练和校验(validation)
- 构建计算架构(computation graph)
- 读取训练参数
- 常规训练流程(更新参数,更新学习率,获取下一个训练batch...)
第一个阶段
类ROIDataLayer是输入ground truth roi的层,初始化的时候先打乱一下数据集的顺序(主要用于校验集validation set)。
# Build data layers for both training and validation set
self.data_layer = RoIDataLayer(self.roidb, self.imdb.num_classes)
self.data_layer_val = RoIDataLayer(self.valroidb, self.imdb.num_classes, random=True)
lib/roi_data_layer/layer.py
class RoIDataLayer(object):
"""Fast R-CNN data layer used for training."""
def __init__(self, roidb, num_classes, random=False):
"""Set the roidb to be used by this layer during training."""
self._roidb = roidb
self._num_classes = num_classes
# Also set a random flag
self._random = random
self._shuffle_roidb_inds()
def _shuffle_roidb_inds(self):
"""Randomly permute the training roidb."""
# If the random flag is set,
# then the database is shuffled according to system time
# Useful for the validation set
if self._random:
st0 = np.random.get_state()
millis = int(round(time.time() * 1000)) % 4294967295
np.random.seed(millis)
if cfg.TRAIN.ASPECT_GROUPING:
widths = np.array([r['width'] for r in self._roidb])
heights = np.array([r['height'] for r in self._roidb])
horz = (widths >= heights)
vert = np.logical_not(horz)
horz_inds = np.where(horz)[0]
vert_inds = np.where(vert)[0]
inds = np.hstack((
np.random.permutation(horz_inds),
np.random.permutation(vert_inds)))
inds = np.reshape(inds, (-1, 2))
row_perm = np.random.permutation(np.arange(inds.shape[0]))
inds = np.reshape(inds[row_perm, :], (-1,))
self._perm = inds
else:
self._perm = np.random.permutation(np.arange(len(self._roidb)))
# Restore the random state
if self._random:
np.random.set_state(st0)
self._cur = 0
ROIDataLayer最重要的方法是forward,它的作用就是获取下一个最小批,forward内调用_get_next_minibatch把mini batch小批中的rio[i]的边界框信息提取出来,用一个字典来保存, 详细代码如下:
lib/roi_data_layer/layer.py
def _get_next_minibatch_inds(self):
"""Return the roidb indices for the next minibatch."""
if self._cur + cfg.TRAIN.IMS_PER_BATCH >= len(self._roidb):
self._shuffle_roidb_inds()
db_inds = self._perm[self._cur:self._cur + cfg.TRAIN.IMS_PER_BATCH]
self._cur += cfg.TRAIN.IMS_PER_BATCH
return db_inds
def _get_next_minibatch(self):
"""Return the blobs to be used for the next minibatch.
If cfg.TRAIN.USE_PREFETCH is True, then blobs will be computed in a
separate process and made available through self._blob_queue.
"""
db_inds = self._get_next_minibatch_inds()
minibatch_db = [self._roidb[i] for i in db_inds]
return get_minibatch(minibatch_db, self._num_classes)
def forward(self):
"""Get blobs and copy them into this layer's top blob vector."""
blobs = self._get_next_minibatch()
return blobs
_get_next_minibatch内调用_get_next_minibatch_inds获取下一个最小批的index, 当前+1, 如果超过数据集最大长度,则先"洗牌", 然后从第一张开始, 与stochastic gradient descent(机器学习中的一种迭代算法)的流程类似, 只不过我们这里的最小批为1(cfg.TRAIN.IMS_PER_BATCH = 1),即一次训练一个目标区域。程序最后调用get_minibatch方法来构建一个最小批,返回的数据是一个dictionary
- data: 形状为 [num_img, h, w, 3]. 神经网络的图像输入, 此处的 num_img=1
- gt_boxes: 边界框, 形状为 [num_gt_indexs, 5] 前4列为边界框坐标信息,第5列为目标类别信息
- im_info: 图像信息, 三个元素, 前两个元素为最终输入图像的高和宽, 第三个元素为原始图像缩放为当前图像的比例
lib/roi_data_layer/minibatch.py
def get_minibatch(roidb, num_classes):
"""Given a roidb, construct a minibatch sampled from it."""
num_images = len(roidb)
# Sample random scales to use for each image in this batch
random_scale_inds = npr.randint(0, high=len(cfg.TRAIN.SCALES),
size=num_images)
assert(cfg.TRAIN.BATCH_SIZE % num_images == 0), \
'num_images ({}) must divide BATCH_SIZE ({})'. \
format(num_images, cfg.TRAIN.BATCH_SIZE)
# Get the input image blob, formatted for caffe
im_blob, im_scales = _get_image_blob(roidb, random_scale_inds)
blobs = {'data': im_blob}
assert len(im_scales) == 1, "Single batch only"
assert len(roidb) == 1, "Single batch only"
# gt boxes: (x1, y1, x2, y2, cls)
if cfg.TRAIN.USE_ALL_GT:
# Include all ground truth boxes
gt_inds = np.where(roidb[0]['gt_classes'] != 0)[0]
else:
# For the COCO ground truth boxes, exclude the ones that are ''iscrowd''
gt_inds = np.where(roidb[0]['gt_classes'] != 0 & np.all(roidb[0]['gt_overlaps'].toarray() > -1.0, axis=1))[0]
gt_boxes = np.empty((len(gt_inds), 5), dtype=np.float32)
gt_boxes[:, 0:4] = roidb[0]['boxes'][gt_inds, :] * im_scales[0]
gt_boxes[:, 4] = roidb[0]['gt_classes'][gt_inds]
blobs['gt_boxes'] = gt_boxes
blobs['im_info'] = np.array(
[im_blob.shape[1], im_blob.shape[2], im_scales[0]],
dtype=np.float32)
return blobs
def _get_image_blob(roidb, scale_inds):
"""Builds an input blob from the images in the roidb at the specified
scales.
"""
num_images = len(roidb)
processed_ims = []
im_scales = []
for i in range(num_images):
im = cv2.imread(roidb[i]['image'])
if roidb[i]['flipped']:
im = im[:, ::-1, :]
target_size = cfg.TRAIN.SCALES[scale_inds[i]]
im, im_scale = prep_im_for_blob(im, cfg.PIXEL_MEANS, target_size,
cfg.TRAIN.MAX_SIZE)
im_scales.append(im_scale)
processed_ims.append(im)
# Create a blob to hold the input images
blob = im_list_to_blob(processed_ims)
return blob, im_scales
- im_list_to_blob: 将图片转成像素信息导入输出层
- prep_im_for_blob: 平均缩小以及缩放一张图片
lib/utils/blob.py
def im_list_to_blob(ims):
"""Convert a list of images into a network input.
Assumes images are already prepared (means subtracted, BGR order, ...).
"""
max_shape = np.array([im.shape for im in ims]).max(axis=0)
num_images = len(ims)
blob = np.zeros((num_images, max_shape[0], max_shape[1], 3),
dtype=np.float32)
for i in range(num_images):
im = ims[i]
blob[i, 0:im.shape[0], 0:im.shape[1], :] = im
return blob
def prep_im_for_blob(im, pixel_means, target_size, max_size):
"""Mean subtract and scale an image for use in a blob."""
im = im.astype(np.float32, copy=False)
im -= pixel_means
im_shape = im.shape
im_size_min = np.min(im_shape[0:2])
im_size_max = np.max(im_shape[0:2])
im_scale = float(target_size) / float(im_size_min)
# Prevent the biggest axis from being more than MAX_SIZE
if np.round(im_scale * im_size_max) > max_size:
im_scale = float(max_size) / float(im_size_max)
im = cv2.resize(im, None, None, fx=im_scale, fy=im_scale,
interpolation=cv2.INTER_LINEAR)
return im, im_scale
第二个阶段
第二个阶段是整个faster rcnn的核心部分,包括了PRN, ROI pooling以及最终的object classification和bounding box regression,我打算放在另一篇文章讲,所以先跳过这段,让我们来看整个训练的流程。
Faster RCNN源码解析(2).
第三个阶段
参数读取主要涉及两个函数self.initialize(sess),self.restore(sess, str(sfiles[-1]), str(nfiles[-1]))
- initialize: 预训练的模型中载入权重。首先调用get_variables_in_checkpoint_file方法从checkpoint file中读取参数, 然后调用Network(resnetv1)中的get_variables_to_restore方法过滤一遍参数,忽略第一层固定的参数,接下来调用tensorflow中的方法tf.train.Saver保存参数,接下来调用fix_variables在导入模型前固定参数。
- restore: 从检查点载入权重和学习率。首先从self.saver中读取checkpoint file, 然后还原到最近的快照,如果发现已经训练完一轮,就更行一下学习率 rate *= cfg.TRAIN.GAMMA(0.1)
lib/model/train_val.py
def initialize(self, sess):
# Initial file lists are empty
np_paths = []
ss_paths = []
# Fresh train directly from ImageNet weights
print('Loading initial model weights from {:s}'.format(self.pretrained_model))
variables = tf.global_variables()
# Initialize all variables first
sess.run(tf.variables_initializer(variables, name='init'))
var_keep_dic = self.get_variables_in_checkpoint_file(self.pretrained_model)
# Get the variables to restore, ignoring the variables to fix
variables_to_restore = self.net.get_variables_to_restore(variables, var_keep_dic)
restorer = tf.train.Saver(variables_to_restore)
restorer.restore(sess, self.pretrained_model)
print('Loaded.')
# Need to fix the variables before loading, so that the RGB weights are changed to BGR
# For VGG16 it also changes the convolutional weights fc6 and fc7 to
# fully connected weights
self.net.fix_variables(sess, self.pretrained_model)
print('Fixed.')
last_snapshot_iter = 0
rate = cfg.TRAIN.LEARNING_RATE
stepsizes = list(cfg.TRAIN.STEPSIZE)
return rate, last_snapshot_iter, stepsizes, np_paths, ss_paths
def restore(self, sess, sfile, nfile):
# Get the most recent snapshot and restore
np_paths = [nfile]
ss_paths = [sfile]
# Restore model from snapshots
last_snapshot_iter = self.from_snapshot(sess, sfile, nfile)
# Set the learning rate
rate = cfg.TRAIN.LEARNING_RATE
stepsizes = []
for stepsize in cfg.TRAIN.STEPSIZE:
if last_snapshot_iter > stepsize:
rate *= cfg.TRAIN.GAMMA
else:
stepsizes.append(stepsize)
return rate, last_snapshot_iter, stepsizes, np_paths, ss_paths
def get_variables_in_checkpoint_file(self, file_name):
try:
reader = pywrap_tensorflow.NewCheckpointReader(file_name)
var_to_shape_map = reader.get_variable_to_shape_map()
return var_to_shape_map
except Exception as e: # pylint: disable=broad-except
print(str(e))
if "corrupted compressed block contents" in str(e):
print("It's likely that your checkpoint file has been compressed "
"with SNAPPY.")
########## lib/nets/resnet_v1.py ###################################
def get_variables_to_restore(self, variables, var_keep_dic):
variables_to_restore = []
for v in variables:
# exclude the first conv layer to swap RGB to BGR
if v.name == (self._scope + '/conv1/weights:0'):
self._variables_to_fix[v.name] = v
continue
if v.name.split(':')[0] in var_keep_dic:
print('Variables restored: %s' % v.name)
variables_to_restore.append(v)
return variables_to_restore
######################################################################
def from_snapshot(self, sess, sfile, nfile):
print('Restoring model snapshots from {:s}'.format(sfile))
self.saver.restore(sess, sfile)
print('Restored.')
# Needs to restore the other hyper-parameters/states for training, (TODO xinlei) I have
# tried my best to find the random states so that it can be recovered exactly
# However the Tensorflow state is currently not available
with open(nfile, 'rb') as fid:
st0 = pickle.load(fid)
cur = pickle.load(fid)
perm = pickle.load(fid)
cur_val = pickle.load(fid)
perm_val = pickle.load(fid)
last_snapshot_iter = pickle.load(fid)
np.random.set_state(st0)
self.data_layer._cur = cur
self.data_layer._perm = perm
self.data_layer_val._cur = cur_val
self.data_layer_val._perm = perm_val
return last_snapshot_iter
第四个阶段
迭代训练, 保存检查点, 并且在中间输出,在训练完成后, 保存最后一步的输出。
代码很简单,调用tensorflow的session.run,来运行之前构造的网络,执行计算图的操作。
lib/nets/network.py
def train_step_with_summary(self, sess, blobs, train_op):
feed_dict = {self._image: blobs['data'], self._im_info: blobs['im_info'],
self._gt_boxes: blobs['gt_boxes']}
rpn_loss_cls, rpn_loss_box, loss_cls, loss_box, loss, summary, _ = sess.run([self._losses["rpn_cross_entropy"],
self._losses['rpn_loss_box'],
self._losses['cross_entropy'],
self._losses['loss_box'],
self._losses['total_loss'],
self._summary_op,
train_op],
feed_dict=feed_dict)
return rpn_loss_cls, rpn_loss_box, loss_cls, loss_box, loss, summary
def train_step(self, sess, blobs, train_op):
feed_dict = {self._image: blobs['data'], self._im_info: blobs['im_info'],
self._gt_boxes: blobs['gt_boxes']}
rpn_loss_cls, rpn_loss_box, loss_cls, loss_box, loss, _ = sess.run([self._losses["rpn_cross_entropy"],
self._losses['rpn_loss_box'],
self._losses['cross_entropy'],
self._losses['loss_box'],
self._losses['total_loss'],
train_op],
feed_dict=feed_dict)
return rpn_loss_cls, rpn_loss_box, loss_cls, loss_box, loss
def get_summary(self, sess, blobs):
feed_dict = {self._image: blobs['data'], self._im_info: blobs['im_info'],
self._gt_boxes: blobs['gt_boxes']}
summary = sess.run(self._summary_op_val, feed_dict=feed_dict)
return summary
至此,就是我们整个的训练过程,校验和测试代码就不做介绍了,因为除了一些细微的操作,过程跟一般的神经网络训练流程是一样。
Faster RCNN源码解析(2).