Solr快速入门第七讲——使用SolrJ管理索引库
什么是SolrJ?
SolrJ是访问Solr服务的Java客户端,提供索引(这里指的就是创建索引、更新索引以及删除索引)和搜索(这里指的是查询索引)的请求方法,SolrJ通常嵌入在业务系统中,通过SolrJ的API接口操作Solr服务,如下图所示。

使用SolrJ管理索引库
添加文档
初学者不妨思考一下添加文档这一操作的实现步骤,你尽管想,想出来算我输!我还是直接老老实实把实现步骤写出来吧!
- 第一步:创建一个普通的Java工程,例如SolrJ。
- 第二步:向Java工程中导入jar包。你不仅要问,应该导入哪些jar包呢?首先导入SolrJ核心jar包(即solr-solrj-8.4.0.jar)和该核心jar包所依赖的那些jar包。
除此之外,还应导入一些有关日志的jar包,它们位于solr-8.4.0\server\lib\ext目录中。
在导入以上这些jar包的过程中,如果有重复的替换就行了。 - 第三步:和Solr服务器建立连接。由于咱们搭建的是单机版的Solr服务器,所以使用HttpSolrClient对象建立连接即可。
- 第四步:创建一个SolrInputDocument对象,然后添加若干域。
- 第五步:将SolrInputDocument对象添加到索引库中去,然后提交(手动提交)即可。
- 第六步:断开与Solr服务器的连接。
看你能不能对应着以上的实现步骤,将代码给整出来。整不出来也没关系,下面我会直接给出实现代码。
package com.meimeixia.solrj;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.common.SolrInputDocument;
import org.junit.Test;
/**
* 使用SolrJ管理索引库
* 添加文档
* 删除文档
* 修改文档
* 查询文档
* @author liayun
*
*/
public class SolrJManager {
// 添加文档
@Test
public void testAdd() throws Exception {
String baseURL = "http://localhost:8080/solr/collection1"; // Solr服务器的地址,特别指定核1
// String baseURL = "http://localhost:8080/solr/collection2"; // Solr服务器的地址,特别指定核2
// 和单机版Solr服务器建立连接
SolrClient solrClient = new HttpSolrClient.Builder(baseURL)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build(); // 至此,终于连上了Solr服务器
// 创建一个文档对象
SolrInputDocument doc = new SolrInputDocument();
// 向文档中添加域
/*
* setField方法中的两个参数的说明如下:
* 第一个参数:域的名称,域的名称必须是在managed-schema配置文件中定义好的,也就是说这个域必须存在
* 第二个参数:域的值
*/
doc.setField("id", "haha");
doc.setField("name", "范冰冰");
// 把文档对象添加到索引库中
solrClient.add(doc);
solrClient.commit(); // 手动提交,当然了,也可以自动提交
// 断开与Solr服务器的连接
solrClient.close();
}
}
删除文档
根据id删除
要想根据id删除文档,只须在以上SolrJManager类中添加一个如下方法即可。
// 删除文档(根据id删除)
@Test
public void testDeleteDocumentById() throws Exception {
String baseURL = "http://localhost:8080/solr/collection1"; // Solr服务器的地址,特别指定核1
// 和单机版Solr服务器建立连接
SolrClient solrClient = new HttpSolrClient.Builder(baseURL)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build(); // 至此,终于连上了Solr服务器
// 根据id删除文档
solrClient.deleteById("haha");
// 断开与Solr服务器的连接
solrClient.close();
}
根据查询语法删除
Solr中的查询语法完全支持Lucene的查询语法。例如,我们可以根据*:*查询语法来删除全部文档,具体的实现代码如下。
// 删除文档(根据查询语法删除)
@Test
public void testDeleteDocumentByQuery() throws Exception {
String baseURL = "http://localhost:8080/solr/collection1"; // Solr服务器的地址,特别指定核1
// 和单机版Solr服务器建立连接
SolrClient solrClient = new HttpSolrClient.Builder(baseURL)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build(); // 至此,终于连上了Solr服务器
// 根据查询语法(*:*)删除全部文档
solrClient.deleteByQuery("*:*", 1000);
// 断开与Solr服务器的连接
solrClient.close();
}
更新文档
在SolrJ中没有对应的update方法来更新文档,只有add方法,更新文档其实就跟添加文档一模一样,只需要添加一个新的文档,和被修改的文档id一致就可以更新了,本质上就是先删除后添加。
现在,你该知道如何更新文档了吧!那么下面的这个方法的代码你能补充完整了吗?
// 更新文档
@Test
public void testUpdate() throws Exception {
String baseURL = "http://localhost:8080/solr/collection1"; // Solr服务器的地址,特别指定核1
// 和单机版Solr服务器建立连接
SolrClient solrClient = new HttpSolrClient.Builder(baseURL)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build(); // 至此,终于连上了Solr服务器
// 更新文档与添加文档一致,只要文档id相同就是更新,文档id不同就是添加
// 所以,这里就不写下去了
}
查询文档
简单查询
之前使用Solr的后台管理界面来查询所有文档,是怎么做的,不知你还记得吗?

上面的这一操作怎么通过代码来实现呢?不知你有没想过,没想过也没关系,下面我会给出具体的实现代码。
// 查询文档(简单查询)
@Test
public void testSearch() throws Exception {
String baseURL = "http://localhost:8080/solr/collection1"; // Solr服务器的地址,特别指定核1
// 和单机版Solr服务器建立连接
SolrClient solrClient = new HttpSolrClient.Builder(baseURL)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build(); // 至此,终于连上了Solr服务器
// 创建一个SolrQuery对象
SolrQuery solrQuery = new SolrQuery();
// 设置查询条件(查询所有)
solrQuery.setQuery("*:*"); // 其实,这句代码还能写成solrQuery.set("q", "*:*");
// 执行查询
QueryResponse response = solrClient.query(solrQuery); // query方法中需要传入的参数是一个SolrParams抽象类,
// 而SolrQuery就是其一个实现子类,所以,这里传入一个SolrQuery对象
// 获取文档结果集
SolrDocumentList docs = response.getResults();
// 总条数
long numFound = docs.getNumFound();
System.out.println("总条数:" + numFound);
// 遍历文档结果集
for (SolrDocument doc : docs) {
System.out.println(doc.get("id"));
System.out.println(doc.get("product_name"));
System.out.println(doc.get("product_price"));
System.out.println(doc.get("product_catalog_name"));
System.out.println(doc.get("product_picture"));
}
// 断开与Solr服务器的连接
solrClient.close();
}
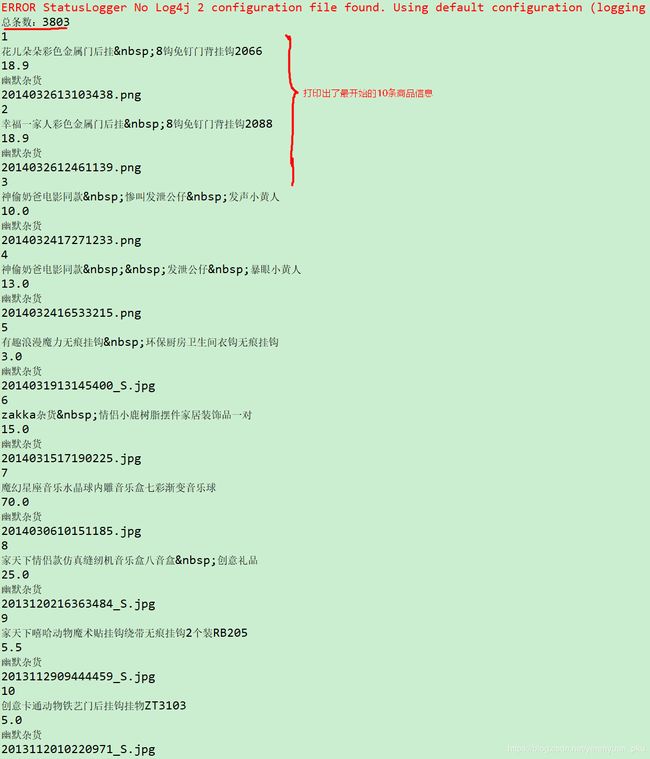
运行以上方法,你将会看到Eclipse控制台打印出了如下图所示的结果。
复杂查询
复杂查询的实现代码写起来就比较复杂了,因为它其中包含了查询、过滤、分页、排序、高亮显示等处理。
想一想,之前要是使用Solr的后台管理界面来实现这样的复杂查询,是不是应该像下面这样子操作呢?
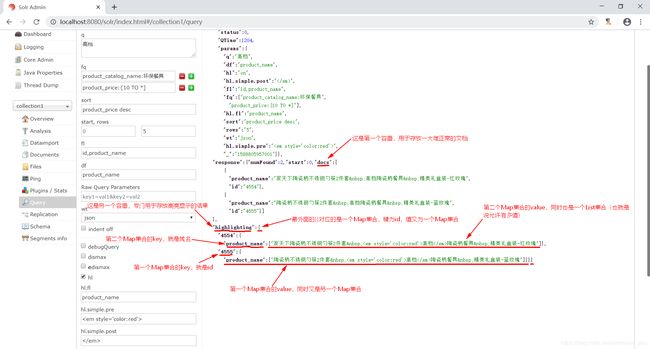
这里我们要注意,一个容器用于存放一大堆正常的文档,另一个容器专门用于存放高亮显示的结果,而且这两个容器不是放在一起的。
那么现在要写代码来实现这样一个比较复杂的查询,包含了按条件查询、条件过滤、排序、分页、高亮显示以及获取部分域信息等,最终的实现代码是怎样子的呢?是不是类似下面这样啊!
// 查询文档(复杂查询)
@Test
public void testSearch2() throws Exception {
String baseURL = "http://localhost:8080/solr/collection1"; // Solr服务器的地址,特别指定核1
// 和单机版Solr服务器建立连接
SolrClient solrClient = new HttpSolrClient.Builder(baseURL)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build(); // 至此,终于连上了Solr服务器
/*
* 需求:在综合查询中,按条件查询、条件过滤、排序、分页、高亮显示、获取部分域信息
*/
SolrQuery solrQuery = new SolrQuery();
// 设置查询条件
// solrQuery.setQuery("product_name:台灯"); // 其实,这句代码还能写成solrQuery.set("q", "product_name:台灯");
solrQuery.setQuery("台灯"); // 因为指定了默认搜索域为product_name,所以product_name:就可以省略不写了
// 过滤条件(要求过滤出商品分类名称为"幽默杂货"的商品信息)
solrQuery.set("fq", "product_catalog_name:幽默杂货");
// 过滤条件(要求过滤出价格在10元以下的商品信息,即按价格区间进行搜索)
solrQuery.set("fq", "product_price:[* TO 10]"); // 10元以下的(包含10元)
// 按照价格进行降序排序
solrQuery.addSort("product_price", ORDER.desc); // 其实,这句代码也可以写成solrQuery.addSort("product_price desc")这样
// 分页
solrQuery.setStart(0); // 从第几条记录开始
solrQuery.setRows(5); // 返回结果最多有多少条记录
// 指定默认搜索域
solrQuery.set("df", "product_name");
// 指定只查询指定域(你不是有5、6个域吗,但是我只想要2个域,行不行?)
solrQuery.set("fl", "id,product_name");
// 高亮
// 1. 首先开启高亮开关
solrQuery.setHighlight(true);
// 2. 指定高亮的域
solrQuery.addHighlightField("product_name");
// 3. 设置高亮前缀
solrQuery.setHighlightSimplePre("");
// 4. 设置高亮后缀
solrQuery.setHighlightSimplePost("");
// 执行查询
QueryResponse response = solrClient.query(solrQuery); // query方法中需要传入的参数是一个SolrParams抽象类,
// 而SolrQuery就是其一个实现子类,所以,这里传入一个SolrQuery对象
// 获取文档结果集
SolrDocumentList docs = response.getResults();
// 获取高亮显示的结果集,高亮显示的结果集和查询结果集是分开放的
Map<String, Map<String, List<String>>> highlighting = response.getHighlighting();
// 第一个Map:key为id,value为Map
// 第二个Map:key为域名,value为List
// List里面可以多个,但本次是一个,即list.get(0)
// 总条数
long numFound = docs.getNumFound();
System.out.println("总条数:" + numFound);
// 遍历
for (SolrDocument doc : docs) {
System.out.println(doc.get("id"));
System.out.println(doc.get("product_name"));
System.out.println(doc.get("product_price"));
System.out.println(doc.get("product_catalog_name"));
System.out.println(doc.get("product_picture"));
System.out.println("-------------------------------------------------------------");
Map<String, List<String>> map = highlighting.get(doc.get("id"));
List<String> list = map.get("product_name");
System.out.println(list.get(0));
}
// 断开与Solr服务器的连接
solrClient.close();
}
运行以上方法,你将会看到Eclipse控制台打印出了如下图所示的结果。
