大数据运维之hadoop的概念单机搭建HDFS集群搭建1
目录
数据运维的概念以及hadoop概念
Hadoop模式:单机,伪分布式,完全分布式和搭建
数据运维的概念以及hadoop概念
运维需要做的工作:收集数据,搭建平台,数据分析,反馈结果

大数据能做什么
企业组织利用相关数据分析帮助他们降低成本,提高效率,开发新产品,做出更明智的业务决策等
把数据集合并后进行分析得出的信息和数据关系性,用来察觉商业趋势,判定研究质量,
大规模并行出来数据库,数据挖掘电网,分布式文件系统或数据库,云计算和可扩展的存储系统等
大数据的特性:数量,速度,种类,真实性,价值
hadoop
一种分析和处理海量数据的软件平台,是开源软件,使用java开发,提供一个分布式基础架构,其特点是高效性,高扩展性,高效性,高容错性,低成本.
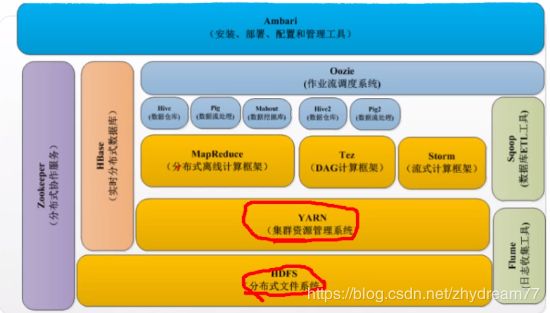
hadoop常用组件(红色是一定需要安装的)
HDFS:hadoop分布式文件系统(核心组件)
MapReduce:分布式计算框架(核心组件)
Yarn:集群资源管理系统(核心组件)
Zookeeper:分布式协助服务
Hbase:分布式列存数据库
Hive:基于Hadoop的数据仓库
Sqoop:数据同步工具
Pig:基于Hadoop的数据流系统
Mahout:数据挖掘算法库
Flume:日志收集工作
HDFS角色及概念
NameNode:Master节点,管理HDFS的名称空间和数据映射信息,配置副本策略,处理所有客户端请求
Secondary NameNode :定期合并fsimage和fsedits,推送给NameNode,紧急情况下,可辅助恢复NameNode.
但是Seconddary NameNode并非NameNode的热备
DataNode:数据存储节点,存储实际数据,汇报存储信息给NameNode
Client:切分文件,访问HDFS,于NameNode交互,获取文件位置信息,与DataNode交互,获取和写入数据
Block:每块缺省128MB大小,每块可以多个副本
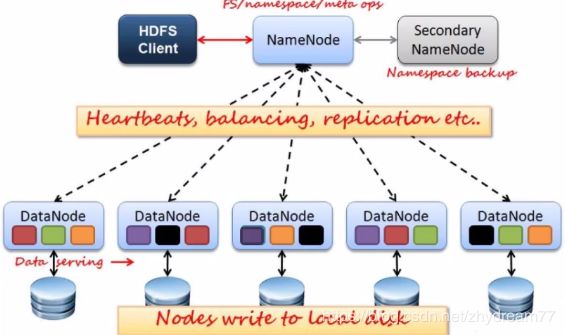
数据在客户端就会被分片,之后访问NameNode节点,之后NameNode会通知客户端,存储在哪里,HDFS Client收到了对应的存储信息,将数据存储到DataNode节点上,当成功存储成功之后,写通知NameNode,并把对应的信息写入到fsimage,fsimage记录了对应的存储的地址.fsedits(文件变更日志)
MapReduce角色及概念
JobTracker :master节点只有一个,管理所有作业/任务的监控\错误处理等,将任务分解成一系列任务,并分派给TaskTracker
TaskTracker:slave节点,一般是多台,运行Map Task和Reduce Task,并与JobTracker交互,汇报任务状态.
Map Task:解析每条数据记录,传递给用户编写的map()并执行,将输出结果写入本次磁盘.如果为map-only作业,直接写入HDFS.
Reduce Task:从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据按照分组传递给用户编写的Reduce函数执行

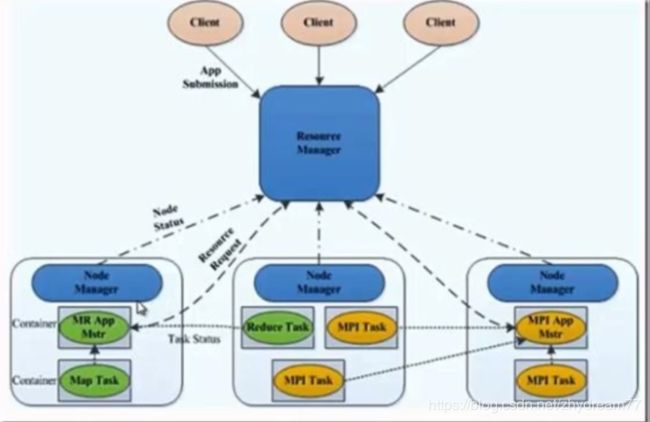
Yarn角色及概念
ResourceManager:处理客户端请求,启动/监控ApplicMaster,监控NodeManager,资源[分配与调度
NodeManager:单个节点上的资源管理,处理来自ResourceManager的命令,处理来自ApplicationMaster的命令
Container:对任务运行环境的抽象,封装了CPU,内存等,多维资源以及环境变量,启动命令等任务运维相关的信息资源分配与调度
ApplicationMaster:数据切分,为了应用程序申请资源,并分配给内部任务,任务监控与容错.
Client:用户与Yarn交互的客户端程序,提交应用程序,监控应用程序状态也,杀死应用程序等.
Hadoop模式:单机,伪分布式,完全分布式和搭建
搭建所用到机器
192.168.1.60 nn01
192.168.1.61 node1
192.168.1.62 node2
192.168.1.63 node3
单机安装:hadoop的单机模式安装很简单,只需要配置好环境变量即可运行,这个模式一般用来学习和测试Hadoop的功能
[root@nn01 ~]# ls
Desktop hadoop-2.7.7.tar.gz
[root@nn01 ~]# tar -xaf hadoop-2.7.7.tar.gz
[root@nn01 ~]# mv hadoop-2.7.7 /usr/local/hadoop
[root@nn01 ~]# cd /usr/local/hadoop/
[root@nn01 hadoop]# ls
bin include libexec NOTICE.txt sbin
etc lib LICENSE.txt README.txt share
[root@nn01 local]# chown -R root.root hadoop
[root@nn01 local]# jps
1169 Jps
[root@nn01 hadoop]# yum -y install java-1.6.0-openjdk
[root@nn01 hadoop]# rpm -ql java-1.6.0-openjdk
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/
[root@nn01 hadoop]# vim hadoop-env.sh
25 export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/"
33 export HADOOP_CONF_DIR="/usr/local/hadoop/etc/hadoop"
[root@nn01 hadoop]# ./bin/hadoop
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
小案例分析:统计文件中哪个单词出现的最多--统计词频
[root@nn01 hadoop]# pwd
/usr/local/hadoop
[root@nn01 hadoop]# mkdir zhy
[root@nn01 hadoop]# cp *.txt zhy/
[root@nn01 hadoop]# cd zhy/
[root@nn01 zhy]# ls
LICENSE.txt NOTICE.txt README.txt
[root@nn01 hadoop]#./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount ./zhy ./zhy1
./zhy为要分析的目录信息./zhy1为分析之后的结果存放路径
[root@nn01 hadoop]# cd zhy1
[root@nn01 zhy1]# ls
part-r-00000 _SUCCESS
[root@nn01 zhy1]# cat part-r-00000
""AS 2
"AS 17
"COPYRIGHTS 1
"Contribution" 2
"Contributor" 2
hadoop常使用的一些分析jar包,因为hadoop是使用java开发的,在开发中是开发一些算法打包成jar包,我们在使用的时候可以直接使用打包使用的算法进行数据分析.
组建分布式集群:伪分布式是讲所有的机子配置在一台上.
搭建思路:需要在nno1节点上配置/etc/hosts,之后传送到每台节点上,在配置免秘钥登录,使得nno1可以免秘钥登录到其他的集群上.
[root@nn01 zhy]# cat /etc/hosts
# ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
192.168.1.60 nn01
192.168.1.61 node1
192.168.1.62 node2
192.168.1.63 node3
[root@nn01 zhy]# for i in 192.168.1.{61..63}; do
> scp /etc/hosts root@$i:/etc/hosts
> done
node1 node2 node3都要安装
[root@node1 ~]# yum -y install java-1.8.0-openjdk-devel
[root@nn01 zhy]# vim /etc/ssh/ssh_config
58 Host *
59 GSSAPIAuthentication yes
60 StrictHostKeyChecking no
[root@nn01 zhy]# ssh-keygen
[root@nn01 zhy]# for i in 192.168.1.{60..63}
> do
> ssh-copy-id $i;
> done
[root@nn01 zhy]# cd /usr/local/hadoop/etc/hadoop/
[root@nn01 hadoop]# ls
capacity-scheduler.xml hadoop-metrics2.properties httpfs-signature.secret log4j.properties ssl-client.xml.example
configuration.xsl hadoop-metrics.properties httpfs-site.xml mapred-env.cmd ssl-server.xml.example
container-executor.cfg hadoop-policy.xml kms-acls.xml mapred-env.sh yarn-env.cmd
core-site.xml hdfs-site.xml kms-env.sh mapred-queues.xml.template yarn-env.sh
hadoop-env.cmd httpfs-env.sh kms-log4j.properties mapred-site.xml.template yarn-site.xml
hadoop-env.sh httpfs-log4j.properties kms-site.xml slaves
[root@nn01 hadoop]# vim slaves
node1
node2
node3
HDFS完全分布式系统配置
环境配置文件:hadoop-env.sh
核心配置文件:core-site.xml (扩展标记性语音)
HDFS配置文件:hdfs-site.xml (扩展标记性语音)
节点配置文件:slaves
[root@nn01 ~]# cd /usr/local/hadoop/etc/hadoop/
[root@nn01 hadoop]# vim core-site.xml ---在配置文件中添加该选项
19
20
21
22
23
24
25
26
27
28
[root@nn01 hadoop]# vim hdfs-site.xml
21
22
23
24
25
26
27
28
29
30
31
32
33
[root@nn01 hadoop]# vim slaves
node1
node2
node3
[root@nn01 hadoop]# vim hadoop-env.sh
25 export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/"
33 export HADOOP_CONF_DIR="/usr/local/hadoop/etc/hadoop"
要求所有的阶段的配置和目录要求一模一样的,所有需要将nno1的配置文件传输到其他的节点上,并检查是否同步
[root@nn01 ~]# for i in node{1..3}; do scp -r /usr/local/hadoop ${i}:/usr/local; done
[root@nn01 ~]# ssh node1 ls /usr/local/hadoop/ |wc -l
12
[root@nn01 ~]# ssh node2 ls /usr/local/hadoop/ |wc -l
12
[root@nn01 ~]# ssh node3 ls /usr/local/hadoop/ |wc -l
12
集群的初始化
格式化文件系统
[root@nn01 ~]# mkdir /var/hadoop ---创建一个空目录,该目录是空白的
[root@nn01 ~]# cd /var/hadoop/
[root@nn01 hadoop]# ls
[root@nn01 hadoop]# cd /usr/local/hadoop/
[root@nn01 hadoop]# ./bin/hdfs namenode -format
20/06/19 10:35:25 INFO common.Storage: Storage directory /var/hadoop/dfs/name has been successfully formatted.
20/06/19 10:35:25 INFO namenode.FSImageFormatProtobuf: Saving image file /var/hadoop/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
20/06/19 10:35:25 INFO namenode.FSImageFormatProtobuf: Image file /var/hadoop/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 321 bytes saved in 0 seconds.
20/06/19 10:35:25 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
20/06/19 10:35:25 INFO util.ExitUtil: Exiting with status 0
20/06/19 10:35:25 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at nn01/192.168.1.60
[root@nn01 hadoop]# cd /var/hadoop/
[root@nn01 hadoop]# ls
dfs
[root@nn01 hadoop]# tree .
.
└── dfs
└── name
└── current
├── fsimage_0000000000000000000
├── fsimage_0000000000000000000.md5
├── seen_txid
└── VERSION
3 directories, 4 files
[root@nn01 hadoop]# cd /usr/local/hadoop/
[root@nn01 hadoop]# ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share zhy zhy1
一般执行文件都存放在bin下,sbin是管理服务,etc是防配置文件的,log是启动的时候动态生成的,
[root@nn01 hadoop]# ./sbin/start-dfs.sh ---启动集群
Starting namenodes on [nn01]
nn01: Warning: Permanently added 'nn01' (ECDSA) to the list of known hosts.
nn01: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-nn01.out
node1: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-node1.out
node3: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-node3.out
node2: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-node2.out
Starting secondary namenodes [nn01]
nn01: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-nn01.out
验证集群构建成功
[root@nn01 hadoop]# jps
1256 NameNode
1548 Jps
1439 SecondaryNameNode
[root@nn01 hadoop]# ssh node1 jps
1092 Jps
1018 DataNode
[root@nn01 hadoop]# ssh node2 jps
1058 Jps
983 DataNode
[root@nn01 hadoop]# ssh node3 jps
1058 Jps
984 DataNode
[root@nn01 hadoop]# ./bin/hdfs dfsadmin -report
Live datanodes (3): 有三个角色则证明成功
如果出现问题,需要多这个目录下去找log的日志文件
[root@nn01 hadoop]# pwd
/usr/local/hadoop
[root@nn01 hadoop]# ls
bin etc include lib libexec LICENSE.txt logs NOTICE.txt README.txt sbin share zhy zhy1