scrapy修改源码生成Pipelines、spider文件添加作者时间注释
修改pipeline、item
1、当我们编写的爬虫量非常大时,而且他们都具有特定的规律,每次我们都需要复制相同的pipelines元素,或者其他重复的工作,那么我们就可以通过修改scrapy源码中的template模板,让他创建时自动生成你需要的Pipelines文件格式,简化工作
class ExcelPipeline(object):
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['标题', '来源', '发布时间', '内容链接', '内容'])
def process_item(self, item, spider):
line = [
item['title'], item['source'], item['publicTime'],
item['url'], item['content']
]
self.ws.append(line)
return item
def close_spider(self, spider):
self.wb.save(spider.zh_name + '(' + str(datetime.date.today()) + ').xlsx')
self.wb.close()
class EmailPipeline(object):
def process_item(self, item, spider):
return item
def close_spider(self, spider):
mailer = MailSender(smtphost="smtp.163.com",
mailfrom="[email protected]",
smtppass="FVDYFCDKVXGTVKNA",
smtpuser="[email protected]",
smtpport=25,
smtptls=True
)
body = '招标邮件,及时查收'
subject = spider.output_excel_filename
attach_mime = "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"
f = open(spider.output_excel_filename, "rb")
return mailer.send(to=["[email protected]"], subject=subject, body=body, cc=["[email protected]"],
attachs=[(spider.output_excel_filename, attach_mime, f)], mimetype="text/plain", charset='utf-8')
class KafkaPipeline(object):
def open_spider(self, spider):
self.producer = KafkaProducer(bootstrap_servers=['sentiment01:9092', 'sentiment03:9092'], value_serializer=lambda m: json.dumps(m).encode('ascii'))
def process_item(self, item, spider):
item['index'] = ELASTICSEARCH_INDEX
self.producer.send('sentiment', dict(item))
return item
def close_spider(self, spider):
self.producer.flush()
self.producer.close()
class MongoPipeline(object):
def open_spider(self, spider):
pass
def process_item(self, item, spider):
return item
def close_spider(self, spider):
pass
class ElasticsearchPipeline(object):
def open_spider(self, spider):
self.es = Elasticsearch(([{"host": ELASTICSEARCH_HOST, "port": str(ELASTICSEARCH_PORT)}]))
def process_item(self, item, spider):
actions = [
{
'_op_type': 'index',
'_index': ELASTICSEARCH_INDEX,
'_type': ELASTICSEARCH_TYPE,
'_source': dict(item)
}
]
elasticsearch.helpers.bulk(self.es, actions)
return item
def close_spider(self, spider):
pass
class RedisPipeline(object):
def open_spider(self, spider):
spider.duplicate = Duplicate(spider.name)
spider.duplicate.find_all_url(index=ELASTICSEARCH_INDEX, doc_type=ELASTICSEARCH_TYPE, source='url')
def process_item(self, item, spider):
return item
def close_spider(self, spider):
print('爬虫关闭')
r = redis.Redis(host=REDIS_HOST, port=str(REDIS_PORT), db=0)
r.delete(spider.name)
分析:如果每个爬虫都需要这些pipelines,那么我们可以在源码中提前加上

我们可以直接在这里,提前修改好你需要的文件格式。
方式二:
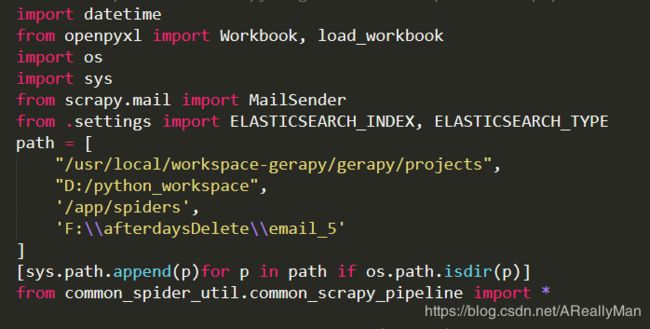
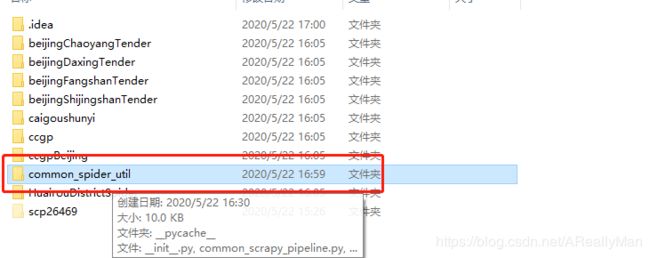
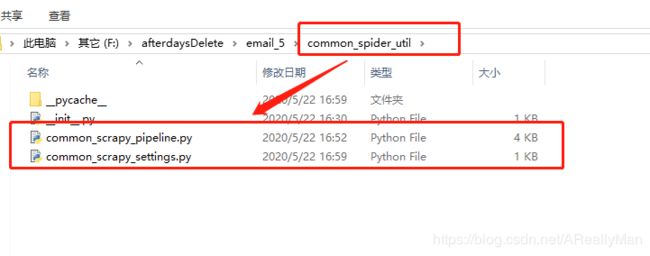
你可以把公共的代码抽离出来,放在一个包下,然后在pipelines文件中直接饮用即可
添加作者注释
scrapy-commands-genspiders.py文件下修改如下:

添加时间注释:

三、生成spider
背景:scrapy startproject xxx时创建自己的模板文件或修改原有模板
1.在python37\Lib\site-packages\scrapy\templates\project\module添加或修改模板文件

2.在startproject时添加须在D:\tools\python\python37\Lib\site-packages\scrapy\commands\startproject.py
TEMPLATES_TO_RENDER = (('scrapy.cfg',),('${project_name}', 'settings.py.tmpl'),('${project_name}', 'items.py.tmpl'),('${project_name}', 'pipelines.py.tmpl'),('${project_name}', 'middlewares.py.tmpl'),//新添加(spider文件)('${project_name}', 'spiders\\spider_news.py.tmpl'),('${project_name}', 'spiders\\spider_paper.py.tmpl'),)