Python wordcloud词云及文件读写操作
wordcloud词云及文件读写操作
- 1.wordcloud词云
- 1.概述
- 2.用到的第三方库
- 3.wordcloud使用说明
- 4.创建词云的步骤
- 5.配置词云的参数(在创建词云对象的时候配置,各参数用逗分隔)
- 6.中文词云
- 2.文件读写
- 1.将文件内容读取之后再生成词云
- 2.文件的概述
- 3.文件操作步骤
- 3.将文件操作与词云生成结合
1.wordcloud词云
1.概述
wordcloud是优秀的词云展示第三方库。所谓词云就是通过形成“关键词云层”或“关键词渲染”,对网络文本中出现频率较高的“关键词”的视觉上的突出,词云图过滤掉大量的文本信息,使浏览网页者只要一眼扫过文本就可以领略文本的主旨。
例如: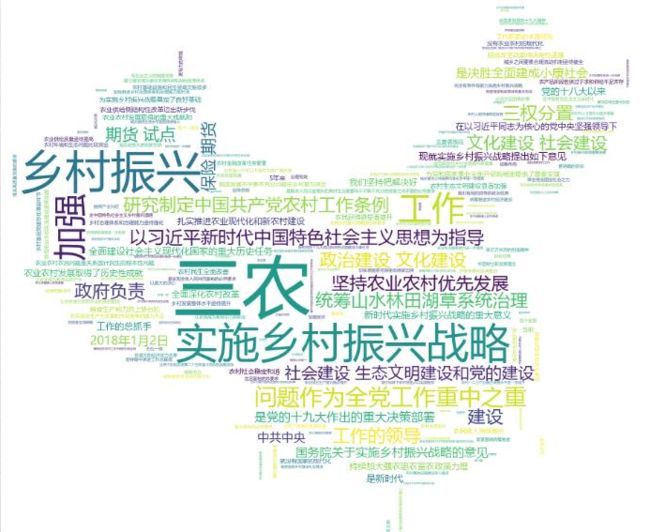
2.用到的第三方库
(cmd命令行) pip install wordcloud
(cmd命令行) pip install imageio
注意在安装wordcloud库时可能会出现报错,需要去网上下载VS组件,再进行安装。
3.wordcloud使用说明
wordcloud把词云当做一个WordCloud对象
wordcloud.WordCloud()代表一段文本对应的词云*。- 可以根据文本中词语出现的频率等参数绘制词云。
- 词云的绘制形状,尺寸和颜色都可以设定。
4.创建词云的步骤
- 创建对象并配置参数:
w=wordcloud.WordCloud(...) - 加载文本:
w.genertae(txt) - 输出文件(.png或者.jpg) :
w.to_file(filename)
由文本变成词云的详细步骤为:
- 分隔:以空格分隔单词
- 统计:单词出现次数并过滤
- 字体:根据统计配置字号
- 布局:颜色环境尺寸
示例代码:
import wordcloud
w=wordcloud.WordCloud() //——1.创建对象
txt='Anti Tracks is a complete solution ernet tracks'
w.generate(txt) //——2.加载文本
w.to_file('cy1.png') //——3.输出文件
输出的文件cy1.png:

注意同一段文本每次运行得到的词云都有可能不一样(颜色,位置会变),因为这里并没有固定的配置参数,但是字号是不变的,因为对于同一段文本来说,词频统计得到的结果是一样的。并且最新的结果会覆盖掉上一次的结果。
5.配置词云的参数(在创建词云对象的时候配置,各参数用逗分隔)
width:指定词云对象生成的图片的宽度,默认400px。
例如:w=wordcloud.WordCloud(width=600)height:指定词云对象生成的图片的高度,默认200px。
例如:w=wordcloud.WordCloud(height=400)min_font_size:指定词云中字体的最小字号,默认4号。
例如:w=wordcloud.WordCloud(min_font_size=10)max_font_size:指定词云中字体的最大字号,根据高度自动调节。
例如:w=wordcloud.WordCloud(max_font_size=20)font_step:指定词云中字体字号的步进间隔,默认为1。
例如:w=wordcloud.WordCloud(font_step=2)font_path:指定字体文件的路径,默认None。
例如:w=wordcloud.WordCloud(font_path="msyh.ttc")设置微软雅黑(必须是计算机中存在的字体)max_words:指定词云显示的最大单词数量,默认为200。
例如:w=wordcloud.WordCloud(max_words=20)stop_words:指定词云的排除词列表,即不显示的单词列表,这跟jieba分词中的禁用词类似。
例如:w=wordcloud.WordCloud(stop_words={"Python"})maxk:指定词云的形状,默认为长方形,需要引用imread()函数。

例如:
from imageio import imread
mk=imread("chinamap.jpg")
w=wordcloud.WordCloud(mask=mk)
background_color:指定词图片的背景颜色,默认为黑色。
例如:w=wordcloud.WordCloud(background_color="white")
6.中文词云
当给定的txt是含中文的字符串时,需要配置font_path参数,而且因为中文句子或文章不存在空格分隔,需要利用之前的jieba分词库来对文本进行分词(列表)并转换为字符串。例如:
import jieba
import wordcloud
w=wordcloud.WordCloud(width=800,height=600,background_color="white",font_path="msyh.ttc")
txt='2016年4月14日,勇士主场125-104轻取灰熊,斯蒂芬·库里全场得到46分,其中三分球19投10中,赛季三分球命中数累计达到402个,成为NBA历史上首位单季三分球命中数突破400大关的球员,帮助勇士队以73胜9负的常规赛战绩,打破公牛在1995-96赛季创下的纪录(72胜10负),成为NBA历史单赛季常规赛战绩最好的球队。2015-16赛季,库里代表勇士出场79次,场均上场34.2分钟得到30.1分5.4篮板6.7助攻,命中5.1个三分球,成为NBA历史上首位单赛季场均至少30分5篮板6助攻并命中5三分的球员。此外,库里场均得分和抢断均位列全联盟第一,职业生涯首次成为单赛季得分王和抢断王。'
txt1=" ".join(jieba.lcut(txt))
w.generate(txt1)
w.to_file('cy4.png')
运行之后生成的词云图为:

2.文件读写
1.将文件内容读取之后再生成词云
- 步骤1:读取文件,分词整理
- 步骤2:设置并输出词云
- 步骤3:观察结果,优化迭代
2.文件的概述
- 文件是存储在辅助存储器上的数据序列
- 文件是数据存储的一种形式
- 文件的展现形态:文本文件和二进制文件
文件文件和二进制文件只是文件的展示方式不同,本质上,所有文件都是二进制形式存储,形式上,所有文件采用两种方式展示。

3.文件操作步骤
1.打开文件:open()
格式为:<变量名> = open(<文件名>,<打开模式>)文件名可以是绝对路径也可以是相对路径。
打开模式:

例如:

2.操作文件:
- 读文件:
f.read(size):读入全部内容,如果给出参数,读入前size长度
例如:s=f.read(2)结果为:中国
f.readline(size):读入一行内容,如果给出参数,读入该行前size长度
例如:s=f.read()结果为:中国是一个伟大的国家
f.readlines(hint):读入文件所有行,以每行为元素形成列表,如果给出参数,读入前hint个字符所在的行
例如:s=f.readlines()结果为:['中国是一个伟大的国家!']
注意当我们要读的文件中含有中文时,需要在
open()函数里面加上encoding="utf-8"。另外,readline()和readlines()默认在读完每一行时会有一个换行,如果不想要,可以利用print(...,end =" ")或者切片将每一行的字符串的最后一个换行符舍去,readlines()之后在循环体写print(s[0:-1])。其实在打开文件open的时候就已经隐藏了readlines这个方法,因此可以省略readlines这一步。
综上所述,遍历全文本的方法有以下几种:




- 写文件:
f.write(s):向文件写入一个字符串或字节流
例如:f.write("中国是一个伟大的国家")
f.writelines(lines):将一个元素全为字符串的列表写入文件,例如:
ls=["中国","法国","美国"]
f.writelines(ls)
f.seek(offset,whence):改变当前文件操作指针的位置(当我们在写入文件的时候,默认情况下光标是在最开始的位置,光标随着写入字符而移动),offset表示位移量,whence的含义为:0—文件开头,1—当前位置,2—文件结尾。whence其实就是设置在开始移动时的起始位置。例如:f.seek(0)回到文件开头,f.seek(0,2)回到文件尾

例如在上面这段程序执行后不会输出任何内容,因为在你写入了列表之后,光标指针在你写的内容的末尾,再往后移是读不到内容的,因此需要用到
f.seek()方法来让光标回到文件开头位置,代码如下:

3.关闭文件:close()
3.将文件操作与词云生成结合
题目:读取与项目文件同目录下的关于实施乡村振兴战略的意见.txt文件并将其转换为词云。
示例代码:
import jieba
import wordcloud
r=open("关于实施乡村振兴战略的意见.txt","r",encoding="utf-8")
t=r.read()
r.close()
ls=jieba.lcut(t)
txt=" ".join(ls)
w=wordcloud.WordCloud(width=1000,height=800,background_color="black",font_path="msyh.ttc")
w.generate(txt)
w.to_file('cp2.png')
运行结果为:

在上题的基础上,使生成的词云具有指定的形状:
import jieba
import wordcloud
from imageio import imread
mk=imread("chinamap.jpg")
r=open("关于实施乡村振兴战略的意见.txt","r",encoding="utf-8")
t=r.read()
r.close()
ls=jieba.lcut(t)
txt=" ".join(ls)
w=wordcloud.WordCloud(width=1000,height=800,background_color="white",font_path="msyh.ttc",mask=mk)
w.generate(txt)
w.to_file('cp3.png')
运行结果为:
