知识干货: GPU关键参数和应用场景


随着云计算,大数据和人工智能技术发展,边缘计算发挥着越来越重要的作用,补充数据中心算力需求。计算架构要求多样化,需要不同的CPU架构来满足不断增长的算力需求,同时需要GPU,NPU和FPGA等技术加速特定领域的算法和专用计算。以此,不同CPU架构,不同加速技术应用而生。
故此,笔者对算力服务器相关知识做了梳理,整理成“数据中心服务器知识全解”电子书,全书共190页,分18个章节。全书简要目录如下(详解目录和内容请通过“阅读原文”获取)
1.1 ARM处理器和厂商介绍 2
1.1.1 ARM处理器架构新进展 8
1.1.2 ARM处理器的主流玩家 10
1.1.3 业界对ARM技术发展态度 10
1.2 RISC-V处理器和厂商介绍 11
1.3 MIPS处理器和厂商介绍 15
1.3.1 龙芯产品和新进展 15
1.4 Alpha处理器和厂商介绍 17
二、 处理器生态和软件堆栈 182.1 处理器软件堆栈架构概述 19
2.2 操作系统和预置软件堆栈 20
2.2.1 原生操作系统支持介绍 20
2.2.2 操作系统预置应用程序 20
2.3 通用应用程序移植分析 20
2.3.1 解释型语言应用程序移植 21
2.3.2 编译型语言应用程序移植 21
2.3.3 应用程序安装包 22
2.3.4 ARM与X86编译差异与解决方法 22
2.3.5 改善应用程序并发计算能力 24
三、 RISC处理器几个关键知识和对比 25 四、 服务器基础知识概述 30 五、 服务器总线知识 50 六、 BIOS/UEFI固件知识 52 七、 服务器认证体系知识 54 八、 服务器CPU基础知识 54 九、 服务器内存基础知识 64 十、 服务器硬盘基础知识 70 十一、RAID基础知识 87 十二、网卡基础知识 93十三、光纤和连接器基础知识 97
十四、光纤交换机基础知识 123
十五、GPU架构和相关知识 135
十六、FPGA架构和相关知识 179
十七、操作系统基础知识介绍
十八、服务器安全基础知识 196
理解 GPU 和 CPU 之间区别的一种简单方式是比较它们如何处理任务。CPU 由专为顺序串行处理而优化的几个核心组成,而 GPU 则拥有一个由数以千计的更小、更高效的核心(专为同时处理多重任务而设计)组成的大规模并行计算架构。
CPU是一个有多种功能的优秀领导者。它的优点在于调度、管理、协调能力强,计算能力则位于其次。而GPU相当于一个接受CPU调度的“拥有大量计算能力”的员工。

GPU可以利用多个CUDA核心来做并行计算,而CPU只能按照顺序进行串行计算,同样运行3000次的简单运算,CPU需要3000个时钟周期,而配有3000个CUDA核心的GPU运行只需要1个时钟周期。
简而言之,CPU擅长统领全局等复杂操作,GPU擅长对大数据进行简单重复操作。CPU是从事复杂脑力劳动的教援,而GPU是进行大量并行计算的体力劳动者。那么,GPU的重要参数有哪些呢?
CUDA核心;CUDA核心数量决定了GPU并行处理的能力,在深度学习、机器学习等并行计算类业务下,CUDA核心多意味着性能好一些
显存容量:其主要功能就是暂时储存GPU要处理的数据和处理完毕的数据。显存容量大小决定了GPU能够加载的数据量大小。(在显存已经可以满足客户业务的情况下,提升显存不会对业务性能带来大的提升。在深度学习、机器学习的训练场景,显存的大小决定了一次能够加载训练数据的量,在大规模训练时,显存会显得比较重要。
显存位宽:显存在一个时钟周期内所能传送数据的位数,位数越大则瞬间所能传输的数据量越大,这是显存的重要参数之一。
显存频率:一定程度上反应着该显存的速度,以MHz(兆赫兹)为单位,显存频率随着显存的类型、性能的不同而不同。显存频率和位宽决定显存带宽。
显存带宽:指显示芯片与显存之间的数据传输速率,它以字节/秒为单位。显存带宽是决定显卡性能和速度最重要的因素之一。
其他指标:除了显卡通用指标外,NVIDIA还有一些针对特定场景优化的指标,例如TsnsoCore、RTCoreRT等能力。例如TensenCore专门用于加速深度学习中的张量运算。
评估一个显卡的性能不能单纯看某一个指标的性能,而是结合显卡的个指标及客户业务需求的综合性能。
GPU是协处理器,与CPU端存储是分离的,故GPU运算时必须先将CPU端的代码和数据传输到GPU,GPU才能执行kernel函数。涉及CPU与GPU通信,其中通信接口PCIe的版本和性能会直接影响通信带宽。
GPU的另一个重要参数是浮点计算能力。浮点计数是利用浮动小数点的方式使用不同长度的二进制来表示一个数字,与之对应的是定点数。同样的长度下浮点数能表达的数字范围相比定点数更大,但浮点数并不能精确表达所有实数,而只能采用更加接近的不同精度来表达。
FP32单精度计算
单精度的浮点数中采用4个字节也就是32位二进制来表达一个数字,1位符号,8位指数,23位小数,有效位数为7位。
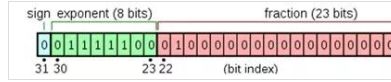
FP64双精度计算
双精度浮点数采用8个字节也就是64位二进制来表达一个数字,1位符号,11位指数,52位小数,有效位数为16位。

FP16半精度计算
半精度浮点数采用2个字节也就是16位二进制来表达一个数字, 1位符号、5位指数、10位小数,有效位数为3位。

因为采用不同位数的浮点数的表达精度不一样,所以造成的计算误差也不一样。
对于需要处理的数字范围大而且需要精确计算的科学计算来说,就要求采用双精度浮点数,例如:计算化学,分子建模,流体动力学。
对于常见的多媒体和图形处理计算、深度学习、人工智能等领域,32位的单精度浮点计算已经足够了。
对于要求精度更低的机器学习等一些应用来说,半精度16位浮点数就可以甚至8位浮点数就已经够用了。
对于浮点计算来说,CPU可以同时支持不同精度的浮点运算,但在GPU里针对单精度和双精度就需要各自独立的计算单元,一般在GPU里支持单精度运算的单精度ALU(算术逻辑单元)称之为FP32 core,而把用作双精度运算的双精度ALU称之为DP unit或者FP64 core,在Nvidia不同架构不同型号的GPU之间,这两者数量的比例差异很大。
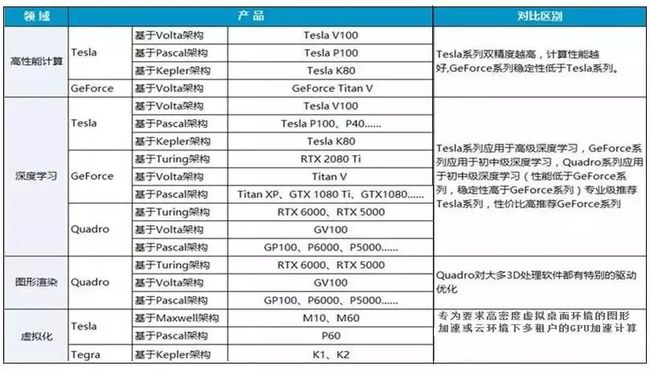
谈到GPU,Nvidia是行业技术的领先者和技术奠基者,其产品主要分以下几个系列,分别面向不同的应用类型和用户群体。
• GeForce系列:主要面向3D游戏应用的GeForce系列,几个高端型号分别是GTX1080TI、Titan XP和GTX1080,分别采用最新的Pascal架构和Maxwell架构;最新的型号RTX 2080TI,Turing架构。因为面向游戏玩家,对双精度计算能力没有需求,出货量也大,单价相比采用相同架构的Tesla系列产品要便宜很多,也经常被用于深度学习、人工智能、计算机视觉等。
• Quadro系列:主要面向专业图形工作站应用,具备强大的数据运算与图形、图像处理能力。因此常常被用在计算机辅助设计及制造CAD/CAM、动画设计、科学研究(城市规划、地理地质勘测、遥感等)、平面图像处理、模拟仿真等。
• GPU加速计算Tesla系列:专用GPU加速计算,Tesla本是第一代产品的架构名称,后来演变成了这个系列产品的名称了,包括V100、P100、K40/K80、M40/M60等几个型号。K系列更适合用作HPC科学计算,M系列则更适合机器学习用途。
Tesla系列高端型号GPU加速器能更快地处理要求超级严格的 HPC 与超大规模数据中心的工作负载。从能源探测到深度学习等应用场合,处理速度比使用传统 CPU 快了一个数量级。
• GPU虚拟化系列:Nvidia专门针对虚拟化环境应用设计GRID GPU产品,该产品采用基于 NVIDIA Kepler 架构的 GPU,首次实现了 GPU 的硬件虚拟化。这意味着,多名用户可以共享单一 GPU。
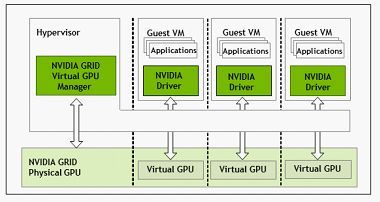
GRID GPU产品主要包含K1和K2两个型号,同样采用Kepler架构,实现了GPU的硬件虚拟化,可以让多个用户共享使用同一张GPU卡,适用于对3D性能有要求的VDI或云环境下多租户的GPU加速计算场景。
GPU散热方式分为散热片和散热片配合风扇的形式,也叫作主动式散热和被动式散热方式。
一般一些工作频率较低的显卡采用的都是被动式散热,这种散热方式就是在显示芯片上安装一个散热片即可,并不需要散热风扇。因为较低工作频率的显卡散热量并不是很大,没有必要使用散热风扇,这样在保障显卡稳定工作的同时,不仅可以降低成本,而且还能减少使用中的噪音。
NVIDIA Tesla Family采用被动散热、QUADRO Family和GeForce Family采用主动散热。
NVIDIA GPU架构的发展类似Intel的CPU,针对不同场景和技术革新,经历了不同架构的演进。
Turing架构里,一个SM中拥有64个半精度,64个单精度,8个Tensor core,1个RT core。
Kepler架构里,FP64单元和FP32单元的比例是1:3或者1:24;K80。
Maxwell架构里,这个比例下降到了只有1:32;型号M10/M40。
Pascal架构里,这个比例又提高到了1:2(P100)但低端型号里仍然保持为1:32,型号Tesla P40、GTX 1080TI/Titan XP、Quadro GP100/P6000/P5000
Votal架构里,FP64单元和FP32单元的比例是1:2;型号有Tesla V100、GeForce TiTan V、Quadro GV100专业卡。
深度学习是模拟人脑神经系统而建立的数学网络模型,这个模型的最大特点是,需要大数据来训练。因此,对电脑处理器的要求,就是需要大量的并行的重复计算,GPU正好有这个专长,时势造英雄,因此,GPU就出山担当重任了。
训练:我们可以把深度学习的训练看成学习过程。人工神经网络是分层的、是在层与层之间互相连接的、网络中数据的传播是有向的。训练神经网络的时候,训练数据被输入到网络的第一层。然后所有的神经元,都会根据任务执行的情况,根据其正确或者错误的程度如何,分配一个权重参数(权值)。
推理:就是深度学习把从训练中学习到的能力应用到工作中去。不难想象,没有训练就没法实现推断。我们人也是这样,通过学习来获取知识、提高能力。深度神经网络也是一样,训练完成后,并不需要其训练时那样的海量资源。
高性能计算应用程序涵盖了物理、生物科学、分子动力学、化学和天气预报等各个领域。也都是通过GPU实现加速的。
通过“阅读原文”获取“数据中心服务器知识全解”电子书详解目录和内容请,全书共190页,分18个章节。
推荐阅读:
详解GPU直通技术和背景
温馨提示:
请识别二维码关注公众号,点击原文链接获取“数据中心服务器知识全解“资料总结。

