简述 GFS & Chubby & Bigtable & Mapreduce
- 分布式文件系统GFS
- Chubby锁服务
- Bigtable的数据模型和系统架构
- 分布式计算编程模型Mapreduce
Google文件系统(Google File System,GFS)是一个大型的分布式文件系统。它为 Google云计算提供海量存储,并且与Chubby、MapReduce 及 Bigtable 等技术结合十分紧密,处于所有核心技术的底层。

GFS 的系统架构
GFS将系统节点分为三类角色:

Chubby 是 Google 设计的提供粗粒度锁服务的一个文件系统,它基于松耦合分布式系统,解决了分布的一致性问题。通过使用Chubby 的锁服务,用户可以确保数据操作过程中的一致性。Chubby 还可以作为一个稳定的存储系统存储包括元数据在内的小数据。同时 Google 内部还使用 Chubby 进行名字服务(Name Server)。

Chubby 的基本架构
Bigtable 是 Goole 开发的机遇 GFS 和 Chubby 的分布式存储系统。
Bigtable 数据的存储格式:
Bigtable是一个分布式多维映射表,表中的数据通过一个行关键字(Row Key)、一个列关键字(Column Key)以及一个时间戳(Time Stamp)进行索引。
Bigtable的存储逻辑可以表示为:
(row:string,column:string, time:int64)→string

WorkQueue 是一个分布式的任务调度器,它主要被用来处理分布式系统队列分组和任务调度。(关于其实现Google并没有公开)
Bigtable 主要由三个部分组成:客户端程序库(Client Library)、一个主服务器(Master Server)和多个子表服务器(Tablet Server)。客户访问 Bigtable 服务时,首先要利用其函数执行 Open()操作来打开一个锁(实际上就是获取了文件目录),锁打开以后客户端就可以和子表服务器进行通信了。客户端主要与子表服务器通信,主服务主要进行一些元数据的操作以及子表服务器之间的负载调度问题,实际的数据是存储在子表服务器上的。

Bigtable 基本架构
MapReduce 是 Goole 提出的一个软件架构,是一种处理海量数据的并行编程模式,勇于大规模数据集(通常大于1TB)的并行运算。
Map函数——对一部分原始数据进行指定的操作。每个Map操作都针对不同的原始数据,因此Map与Map之间是互相独立的,这使得它们可以充分并行化。
Reduce操作——对每个Map所产生的一部分中间结果进行合并操作,每个Reduce所处理的Map中间结果是互不交叉的,所有Reduce产生的最终结果经过简单连接就形成了完整的结果集。
Map: (in_key, in_value) à {(keyj, valuej) | j= 1…k}
Reduce: (key, [value1,…,valuem]) à (key, final_value)
Map输入参数:in_key和in_value,它指明了Map需要处理的原始数据。
Map输出结果:一组<key,value>对,这是经过Map操作后所产生的中间结果。
Reduce输入参数:(key,[value1,…,valuem])。
Reduce工作:对这些对应相同key的value值进行归并处理。
Reduce输出结果:(key,final_value),所有Reduce的结果并在一起就是最终结果 。

MapReduce 的运行模型
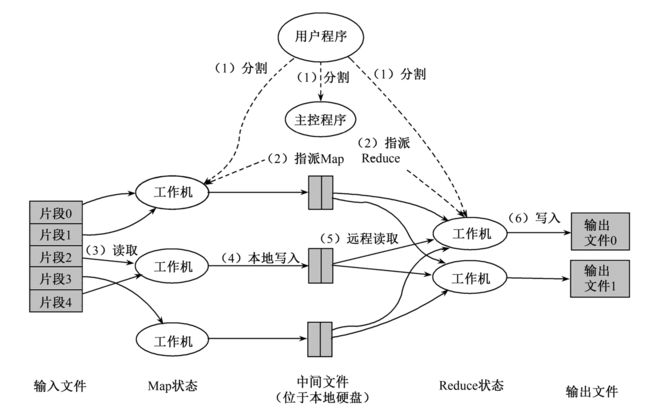
MapReduce 操作的执行流程
实现机制:
(1)MapReduce函数首先把输入文件分成M块;
(2)分派的执行程序中有一个主控程序Master;
(3)一个被分配了Map任务的Worker读取并处理相关的输入块;
(4)这些缓冲到内存的中间结果将被定时写到本地硬盘,这些数据通过分区函数分成R个区;
(5)当Master通知执行Reduce的Worker关于中间<key,value>对的位置时,它调用远程过程,从Map Worker的本地硬盘上读取缓冲的中间数据;
(6)ReduceWorker根据每一个唯一中间key来遍历所有的排序后的中间数据,并且把key和相关的中间结果值集合传递给用户定义的Reduce函数;
(7)当所有的Map任务和Reduce任务都完成的时候,Master激活用户程序。