022 Hive的udf入门 Hive的udf使用 Hive的文件存储格式 Hive的serde记录格式
Hive的udf入门


1.写这个代码时 需要继承UDF 但Maven里没有

2.所以需要再pom.xml配置文件配置如下信息
org.apache.hive
hive-exec
1.2.1
3.但是加入后会出现头文件报错
就是这一行报错 现在没有错了

找了好久没找到错误 因为没找到提示信息
最后还是pom.xml这个文件
点击了下面的Dependencies
就在蓝色的Dependencies后面出现错误提示信息(现在没有了) 具体提示信息参考下面网址 就是没有jar包
 **
**
https://blog.csdn.net/Young_____Hu/article/details/86290227
https://blog.csdn.net/CSDN19970806/article/details/81986007
https://mvnrepository.com/artifact/org.pentaho/pentaho-aggdesigner-algorithm/5.1.5-jhyde下载地址
具体参考这两个
还要一个我加上jar包后 还是报错 不知道怎么刷新
eigenbase
eigenbase-properties
1.1.5
根据解决办法加了这个之后头文件不报错了
这个配置dependency又报错 然后我就删了 竟然好了
最后是这样的

package qf.com.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
/*
*@author Shishuai E-mail:[email protected]
*@version Create time : 2019年6月7日下午11:18:53
*类说明:online -> online_class
*将字符串动态拼接上一个 “_class”
*/
public class MyconcatUdf extends UDF{
public String evaluate(String word) {
if(word == null) {
return "NULL";
}
return word + "_class";
}
public static void main(String[] args) {
System.out.println(new MyconcatUdf().evaluate("online"));
}
}
这样写好后

1.
add jar /home/wc.jar;
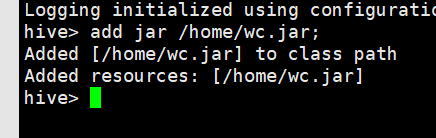
create temporary function myconcat as ‘qf.com.udf.MyconcatUdf’;

show functions;

desc function myconcat;

测试使用

select myconcat(s.sclass) from rn s;

注意这样的方法只是当前session有效
quit后再进入hive就无效了
4.drop function if exists myconcat;(出现问题了· 没解决)
下面我们使用另一种方式部署udf

package qf.com.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.json.JSONException;
import org.json.JSONObject;
/*
*@author Shishuai E-mail:[email protected]
*@version Create time : 2019年6月8日下午1:50:07
*类说明:
*/
public class KeyToValue extends UDF {
public String evaluate(String av, String key) throws JSONException {
if(av == null|| key == null) {
return "NULL";
}
//正常取值
//sex=1&weight=128&height=180&sla=30000
// 使用json来解析字符串
// 首先要将其转换为json格式再解析
av = av.replaceAll("&", ",");
av = av.replaceAll("=", ":");
av = "{" + av + "}";
//System.out.println(av);
//将符合json格式的av转换成joson对象
JSONObject jo = new JSONObject(av);
return jo.get(key).toString();
}
public static void main(String[] args) throws JSONException {
System.out.println(new KeyToValue().evaluate("sex=1&weight=128&height=180&sla=30000", "sla"));
}
}
这个配置文件的是另一种方式了 就是下面截图的配置 配置好了就是hive加载时会将auxlib文件夹一起加载 就不用add了
这里就不演示了 因为视频也没弄

cd /usr/local/hive-1.2.1
vi ./bin/.hiverc

add jar /home/wc.jar;
create temporary function ktv as ‘qf.com.udf.KeyToValue’;

然后我们需要重新进入hive才能生效
show functions;

select ktv(“sex=1&weight=128&height=180&sla=30000”, “sex”);

没有问题
如果输入的key字符串没有 就会抛异常

Hive的文件存储格式




hive 存储
一.textfile可以配合压缩使用
create table if not exists tf(
name String,
score String
)
row format delimited fields terminated by '\t'
stored as textfile
;
load data local inpath ‘/home/olddata/tf’ into table tf;

二、sequencefile:
create table if not exists sf(
name String,
score String
)
row format delimited fields terminated by '\t'
stored as sequencefile
;
加载数据 不能使用load方式加载
load data local inpath ‘/home/olddata/tf’ into table sf;这种报错 格式不对
使用这个方法:
insert into table sf
select name, score from tf;


看大小 压缩算法是占用一定空间的.
看时间 查询的话 比普通的textfile是要快的

三、rcfile行列混合存储
create table if not exists rf(
name String,
score String
)
row format delimited fields terminated by '\t'
stored as rcfile
;
加载数据 不能使用load方式加载
load data local inpath ‘/home/olddata/tf’ into table rf;这种报错 格式不对
使用这个方法:
insert into table rf
select name, score from tf;
存储格式 show create table rf;
set hive.exec.compress.output=true;这是默认的
还可以自己改 不演示了
set mapred.output.compression.code=org.apache.hadoop.io.compress.GZipCodec;

四、orc:优化的行列混合存储
create table if not exists orf(
name String,
score String
)
row format delimited fields terminated by '\t'
stored as orc
;
insert into table orf
select name, score from tf;


四个的大小

看查询时间

这样看不严谨
应该多跑几次找平均值




还有一个
parqut格式 自己到官网看一下
还有一个hive自带的 。自定义格式
也可以到官网看一下
truncate table orf;
小方法 清空表内数据

Hive的serde记录格式
serde 序列化和反序列化

创建记录为csv格式的表
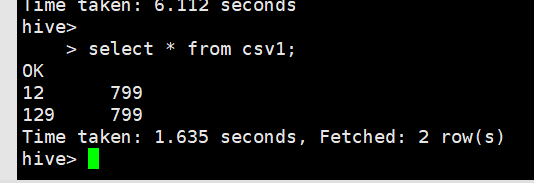
create table if not exists csv1(
name String,
score String
)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
stored as textfile
;
load data local inpath '/home/olddata/csv1.csv' into table csv1;
除了OpenCSVSerde属性
还有其他属性 具体参考那个源码去看看



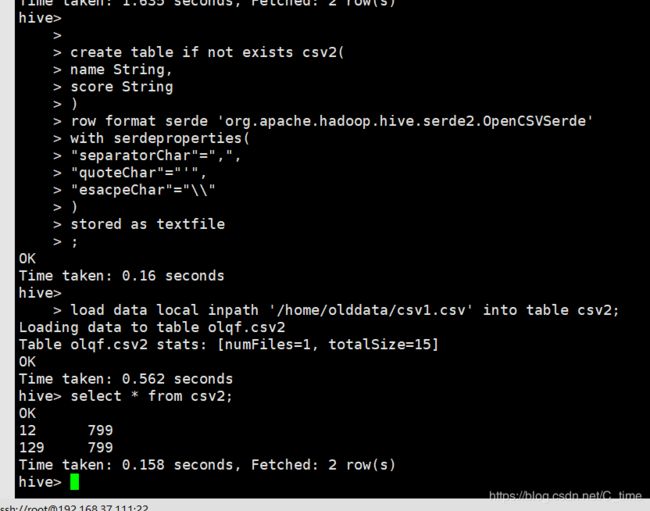
create table if not exists csv2(
name String,
score String
)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties(
"separatorChar"=",",
"quoteChar"="'",
"esacpeChar"="\\"
)
stored as textfile
;
load data local inpath '/home/olddata/csv1.csv' into table csv2;
json serde
使用json serde
需要下载 并 添加第三方jar包
http://www.congiu.net/hive-json-serde/
下载地址

然后就可以创建了

select j.name, j.qq, j.wechat, size(j.score)
from json1 j
where j.score[0]["lyd"][0] > 80;

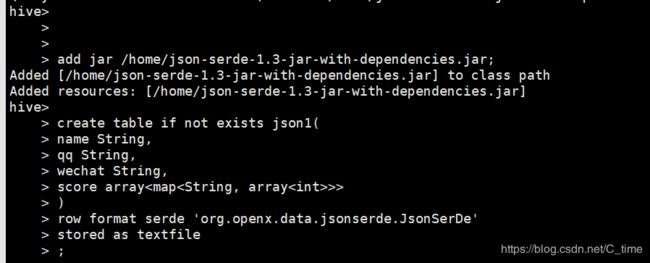
json serde:
将第三方的jar包添加到hive中:
add jar /home/json-serde-1.3-jar-with-dependencies.jar;
{"name":"lyd","qq":"775600040","wechat":"15901108226","score":[{"lyd":[66,28,62],"old":[99,78,88]}]}
{"name":"laidon","qq":"775600040","wechat":"15901108226","score":[{"lyd":[89,87,88],"old":[39,58,88]}]}
create table if not exists json1(
name String,
qq String,
wechat String,
score array>>
)
row format serde 'org.openx.data.jsonserde.JsonSerDe'
stored as textfile
;
load data local inpath '/home/olddata/json1' into table json1;
select j.name, j.qq, j.wechat, size(j.score)
from json1 j
where j.score[0]["lyd"][0] > 80;
regex serde
regex serde:
数据:
220.181.108.151 [31/Jan/2012:00:02:32 +0800]
220.81.108.151 [31/Jan/2012:00:02:32 +0800]
220.c1.108.151 [31/Jan/2012:00:02:32 +0800]
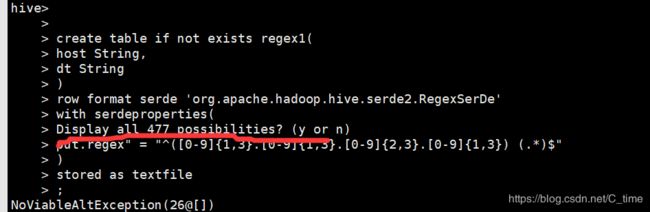
create table if not exists regex1(
host String,
dt String
)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serderproperties(
"input.regex" = "^([0-9]{1,3}.[0-9]{1,3}.[0-9]{2,3}.[0-9]{1,3}) (.*)$"
)
stored as textfile
;
load data local inpath '/home/olddata/regex1' into table regex1;
不知道怎么回事
一下复制上 会出来这么一句
所以我就分隔一半一半复制
所以就好了
或者直接敲上

三行数据 只有两行符合正则表达式
