百度AI studio安装Tensorflow-gpu 2.0.0
1.注册百度AIStudio平台账号
完成任务(两三分钟)可以获得100小时的GPU
地址 https://aistudio.baidu.com/ (创建项目,上传数据集,启动项目很快就能学会使用)
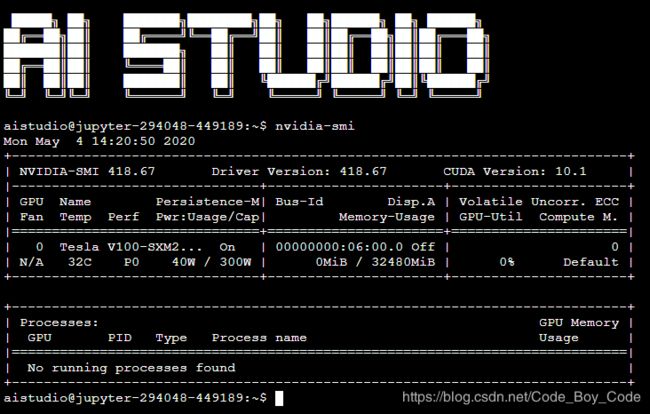
tensorflow-gpu 2.0所依赖的cuda要求10.0版本,但是AIStudio启动项目的时候自带的显卡驱动的版本是随机的,有时候是396.37版本有时候是418.67版本,410.18以上版本的显卡驱动才能安装,版本为10.0以上的cuda。tensorflow-gpu2.0需要cuda10以上的版本。当启动项目后可以在终端里运行 nvidia-smi查看显卡的驱动版本,当不是410.18以上版本的显卡驱动时,就关闭项目重新启动项目。
进入项目
2.创建项目
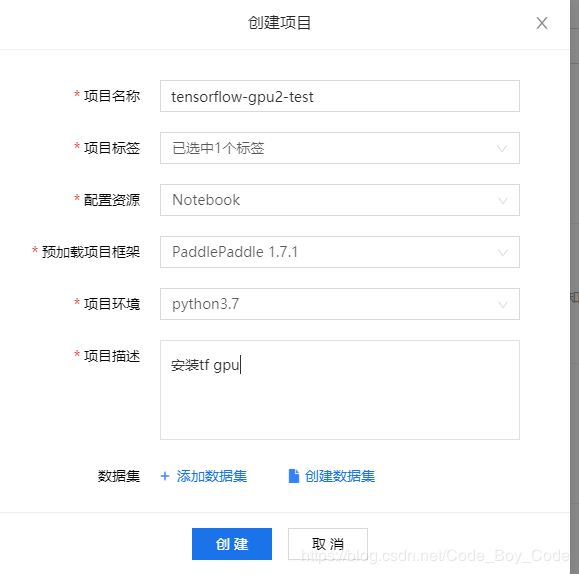
填好有关内容然后点击创建
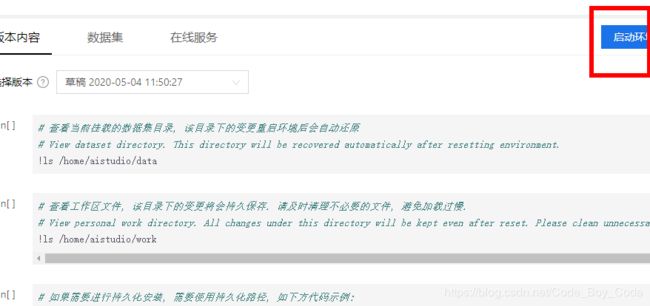
点击启动环境进入环境
3.开始配置cuda cudnn
安装cuda之前要先查看需要安装的tensorflow-GPU的版本,然后根据要求安装cuda和cudnn
3.1查看显卡驱动
在终端里运行 nvidia-smi
3.2查看驱动对应的cuda版本
地址:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
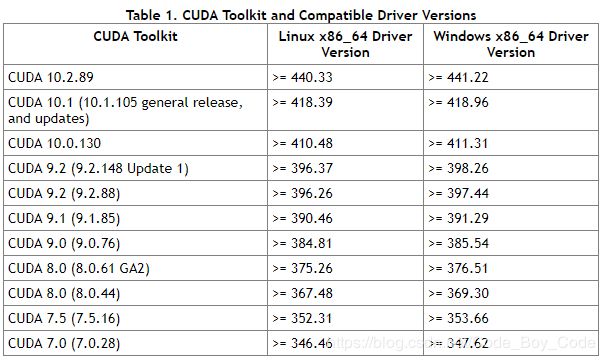
第一列是cuda的版本,后面的是不同系统下要求的显卡驱动的版本
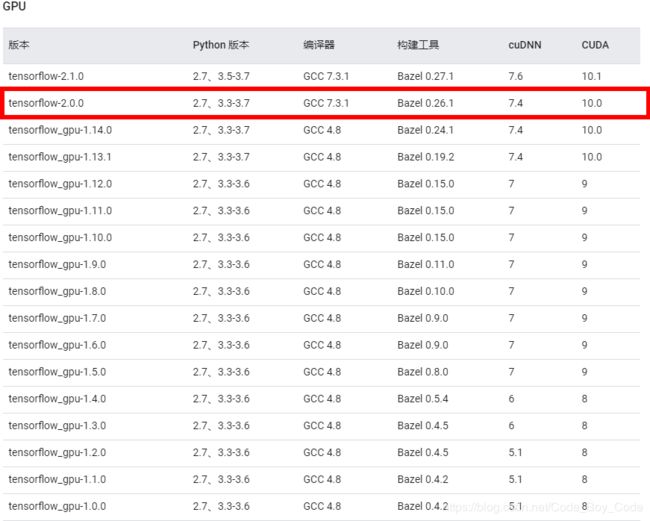
3.3选择cudnn 版本
查看cuda 和Tenforflow 对应版本 https://tensorflow.google.cn/install/source#linux
4.安装
4.1 下载 cuda
cuda下载地址:https://developer.nvidia.com/cuda-toolkit-archive
通过查看cuda和tensorflow对应的版本,了解tensorflow-gpu2.0需要cuda 10.0的版本
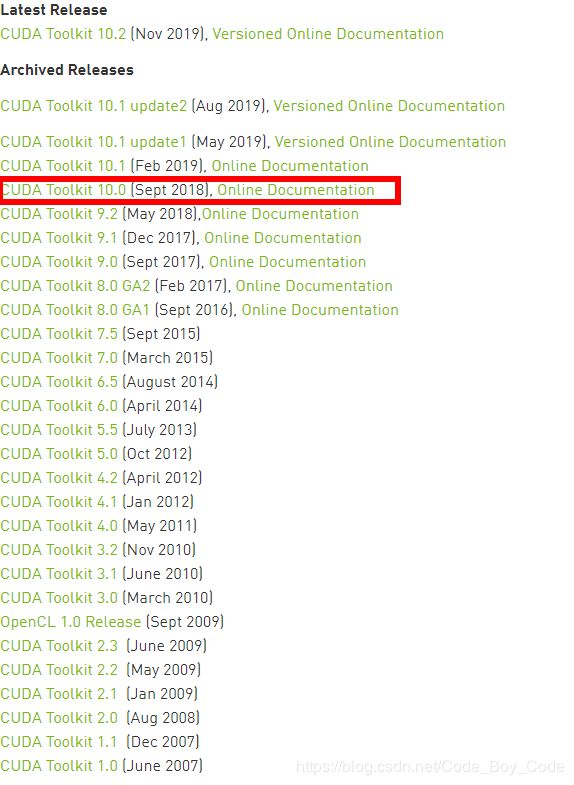
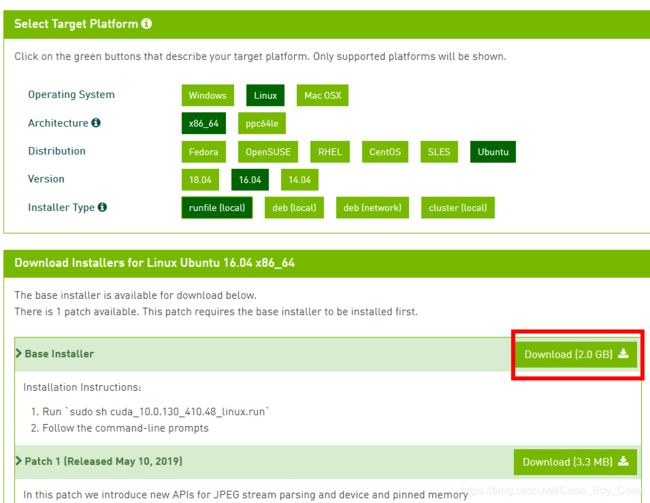
通过上面的操作获取cuda 10.0的下载链接,然后在终端里运行命令进行下载
wget https://developer.nvidia.com/compute/cuda/10.0/Prod/local_installers/cuda_10.0.130_410.48_linux名字太长了改一下名字,改成 cuda_10.0.130_410.48_linux.run
4.2 下载 cudnn
查看cuda cudnn 对应版本 https://tensorflow.google.cn/install/source#linux
cudnn下载地址:https://developer.nvidia.com/rdp/cudnn-archive 需要注册登录
cudnn 需要和linux系统版本对应 查看linux版本,
按理说这里我们应该安装 CuDnn 的版本是 7.4的才对,但是在运行程序的时候这样会报错
“oaded runtime CuDNN library: 7.3.1 but source was compiled with: 7.6.0. CuDNN library major and minor version needs to match or have higher minor version in case of CuDNN 7.0 or later version.”
所以根据提示我们这里安装 CuDNN 7.6的版本
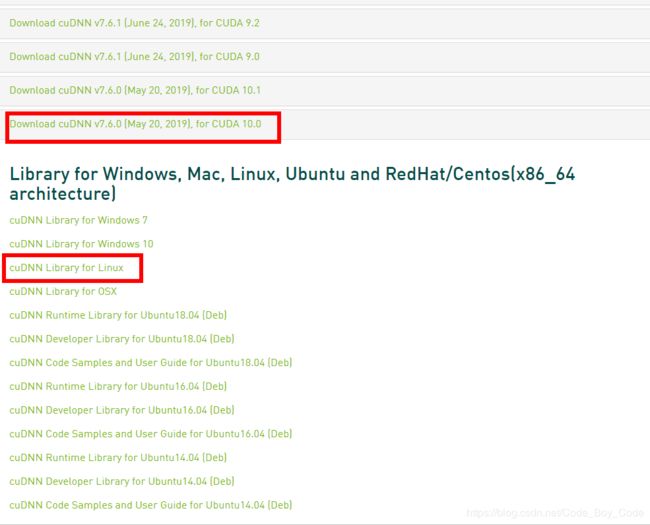
获取下载链接后
造终端里运行命令进行下载
wget https://developer.download.nvidia.cn/compute/machine-learning/cudnn/secure/v7.6.0.64/prod/10.0_20190516/cudnn-10.0-linux-x64-v7.6.0.64.tgz?jNv-Pw6JG-MCWG5kQyY154SuM6x82Zmtb9KuNjXFEQ4w0nWzesv5v5x51oZdOkJtnsWVjlXd-z9JLFboXP_eFTzhX3q2sArUW8iTWYgcnkC1kr8Qb7U_TchBDc_g4gcC1fRAFWBYDt7SS6dvvpg7vtrQSVMjrDPGlSEmDYIh-M88kFQaqzlaFX53XFNOG9Niu19DvmIBh_5IDxpTVWc_A0tIpoU下载之后把名字改一下,改成cudnn-10.0-linux-x64-v7.6.0.64.tgz
4.3 安装
新建一个目录 : mkdir cuda-10.0
安装cuda :
sh cuda_10.0.130_410.48_linux.run --silent --toolkit --toolkitpath=$HOME/cuda-10.0安装cudnn
解压下载的cudnn,默认会解压到cuda文件夹中
tar -zxvf ./cudnn-10.0-linux-x64-v7.6.0.64.tgz解压把cudnn的指定文件copy到cuda安装文件对应的目录中,注意目录要对,这一步只需要做一次就可以
cp cuda/include/cudnn.h cuda-10.0/include/cp cuda/lib64/libcudnn* cuda-10.0/lib64/4.4 修改权限
chmod a+r ~/cuda-10.0/include/cudnn.hchmod a+r ~/cuda-10.0/lib64/libcudnn*4.5 配置环境
vi ~/.bashrc
export PATH=/home/aistudio/cuda-10.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/home/aistudio/cuda-10.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export CUDA_HOME=/home/aistudio/cuda-10.0
source ~/.bashrc5 安装TensorFlow-GPU 2.0
在按照自己的需要安装 Python包时不要直接安装,就是说不要把包安装在 base 环境和 paddle 的环境中,因为这样不会持久,当我们关闭项目重新启动时,我们自己安装的包就都没有了。
持久化的问题在我们创建项目的时候自带的Notebook中已经给出了解决方法
首先创建一个文件夹来放我们自己的 Python 包
mkdir /home/aistudio/external-libraries然后把我们需要的包都安装在这个文件夹中,如安装 beautifulsoup4
pip install beautifulsoup4 -t /home/aistudio/external-libraries当我们要使用beautifulsoup4时需要在Python代码中添加如下代码就可以了。
import sys
sys.path.append('/home/aistudio/external-libraries')所以我们也要把TensorFlow-gpu 2.0安装在这个文件夹中
pip install tensorflow-gpu==2.0.0 -t /home/aistudio/external-libraries这样就可以持久化了。
6 训练自己的模型
在终端中执行自己的程序

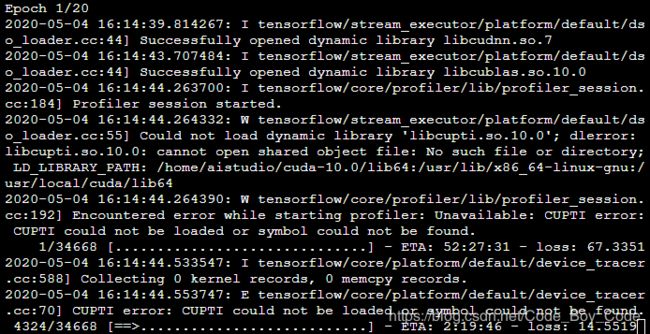
7 注意
我们这样设置的tensorflow的环境是不能使用AiStudio自带的notebook的,但是我们可以在终端里执行自己的代码。
当我们重新启动项目后发现不能正常使用了,怎么搞的呢?
1.首先我们要检测显卡的驱动程序的版本是不是 418.67或以上,
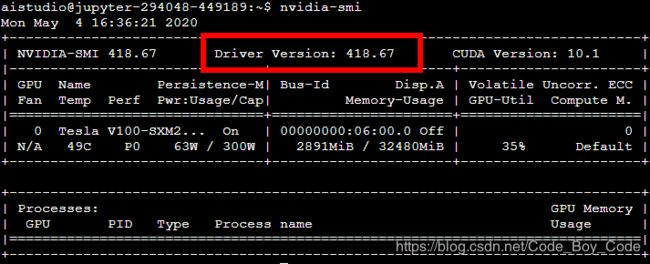
如果不是就重新启动项目,直到分配到这个版本的环境为止,
2.需要重新修改有关文件的权限和配置环境变量,怎么设置的参考上面的 4.4 修改权限 和 4.5 配置环境。
然后就可以正常执行自己的代码了。但是感觉这样还是有点麻烦,那就搞个脚本吧把修改权限和配置环境放在脚本里
创建一个文件 auto_chmod_env.sh ,点击打开,填入一下内容
#!/bin/bash
chmod a+r ~/cuda-10.0/include/cudnn.h
chmod a+r ~/cuda-10.0/lib64/libcudnn*
echo 'export PATH=/home/aistudio/cuda-10.0/bin${PATH:+:${PATH}};export LD_LIBRARY_PATH=/home/aistudio/cuda-10.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}};export CUDA_HOME=/home/aistudio/cuda-10.0' > ~/envm
source ~/envm当项目重新启动后只要在终端里执行一下语句
source auto_chmod_env.sh就自动修改了有关文件的权限和配置好了环境,然后自己运行自己的代码就行了。
注意
在执行代码时,一定要在要执行的代码中添加
import sys
sys.path.append('/home/aistudio/external-libraries')引用
百度AI studio配置cuda +cudnn(详细教程)
百度AI studio配置tensorflow环境