Linux0.11小结
第一部分 基础内容
1.操作系统基础
操作系统是计算机硬件系统与用户程序间重要环节,理解操作系统的原理是编写优秀代码的基础。教课书中阐述的操作系统一般由5部分组成。
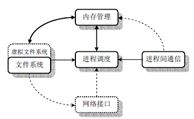
一个最简单的操作系统,可以不需要文件,不需要网络,只要实现多进程,且进程间也不需要通信,相互独立。那么这样一个简单的OS仅需要两块内容:进程管理、内存管理。这两方面内容是相辅相成,不可分割的,因为现在计算机系统的基本架构仍是指令存储-执行。内存管理很大程度上依赖处理器的硬件支持,而进程管理则是在这个基础上,用软件的方式虚拟化出的一套机制,使得多个程序能同时使用计算机。
下面先介绍一些与操作系统相关的基础知识。
1.1操作系统的启动简介
计算机中最初始的是硬件,理解操作系统的启动虽不难,但却可以让人去除对操作系统的敬畏之情,给我印象最深的就是《自己动手写操作系统》开篇讲的,10分钟写出一个OS,也正是这个才鼓励我学习了下面的内容。
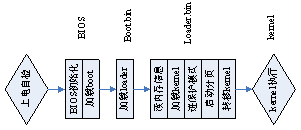
一般PC机的启动过程如下:
-
上电自检,当电压稳定后,释放reset,控制权交给CPU(一般由一些特定的控制芯片完成);
-
CPU的地址指针首先指向BIOS,由BIOS执行一些必要的检查和初始化,BIOS最后把启动盘中的第一个扇区加载到0x7C00处(即boot.bin),并跳转到此处执行;
-
Boot.bin主要是把loader.bin加载到0x9000:0x200处,并跳转到此处执行;
-
Loader.bin读出内存信息,并把kernel.bin加载到0x8000:0处,然后进入保护模式,在保护模式下初始化页目录页表,并启动分页机制,然后把kernel.bin按照elf头信息以及ld –Text xx的参数移到正确的位置,并跳入内核起始点;
-
操作系统内核开始工作。
b)是计算机转由软件控制的关键,可以直接写一个显示的小例子,然后dd到硬盘的引导扇区(即第一个扇区),重启计算机就会发现屏幕上显示你所要的字符。
至于boot.bin为什么要加载一个loader.bin进来,主要是boot.bin只有512byte,太小了,做不了太多事。Loader.bin则没有限制,可以做很多工作,把kernel.bin加载到内存中,利用BOIS中断服务获得系统的一些硬件信息,如内存大小、硬盘信息等,并存放在内存相应位置,供OS以后使用。然后最重要的就是使计算机进入保护模式,做一些初始化工作:gdt,idt,A20线,分页等, 并把控制权交给kernel.bin。
注意进保护模式前,内存中主要是BOIS(固化在ROM中)及BOIS初始化出来的一些数据结构,如实模式下的中断向量表等。因此在进保护模式前,BOIS服务(即软中断int xx)仍是可用的,事实上启动过程中加载、显示两大操作正是利用的BOIS的int 13和int 10中断服务例程,另外初始化硬件,获得诸如内存信息、硬盘信息等都是通过BOIS服务完成的。
进入保护模式后,中断向量的方式和实模式完全不一样了,此时BOIS不再有用,而是真正要靠OS来接管一切,从头开始。
1.2保护模式下的存储机制
在实模式下,采用分段的存储机制,寻址以seg:offset方式寻址。其中seg是段描述符16bit,offset为16bit,总地址为seg<<4+offset,最大地址为1M。
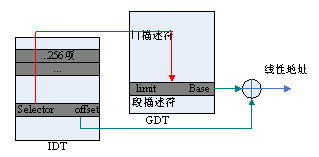
在保护模式下,寻址也采用seg:offset方式,seg仍为16bit,但offset为32bit,且实现的机制也大不相同。其中最关键的是GDT表,如下图所示

GDT表放在内存中,其地址有GDTR寄存器标识。Seg中存放的为一个索引值,指向GDT表中的某一项。GDT表中的每一项称为描述符DESCRIPTOR,它里面包含了该段的base基址即该段的limit。其中base为32bit的,加上offset即为所要寻址的线性地址。
GDT表只有一个,光靠它来实现多进程的地址空间分割还不够,处理器还提供LDT机制,如下图所示:
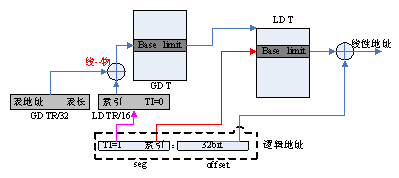
寄存器GDTR是一个32bit的,标识了GDT表的地址,LDTR寄存器是16bit的,其中存放的却是一个选择子SELECTOR,索引GDT表中的某一项。Seg中的TI=1,则表明这是一个LDT寻址,根据LDTR中的索引值找到GDT表中的相应项,得到LDT表的基址base。Seg中的索引值在LDT表中索引到相应项,得到实际base,加上offset就是线性地址了。
GDT表只有一个,LDT表却可以有很多,事实上是每个进程都有自己的LDT表,且它们都在GDT表中有相应项对应。在切换进程时,只要改变LDTR寄存器的值,就可以轻易实现各个进程使用自己的LDT表。这样就可以实现多进程的地址空间分割了,因为各个进程可以使用相同的seg段,但所指向的实际地址却可不同,不相冲突,就好像每个进程都独享了所有地址段。
上面说了分段机制得到的是线性地址,要变为实际的物理地址,还需要分页机制。如果说GDT+LDT方式的分段,使得多进程在表面上实现了地址空间分割,那么分页机制则在表面上是地址空间分割的情况下,实现了物理地址并不需要分割,不需要连续,甚至可以重叠。

如上图所示,内存中有一个页目录表,其地址有CR3寄存器标识,页目录表中有1024项PDE,由线性地址的高10bit索引;每个PDE为32bit,指向一个页表,每个页表中有1024项PTE,有线性地址的中间10bit索引;每个PTE为32bit,指向该页框的基址,每个页框有4KB大小,由线性地址的低12bit寻址。
分段机制使得各个进程使用相同的段,但由于各个进程的LDT表项所指的基址base不同,从而实现了线性空间的分割。但分页机制使得分割的线性空间可以随意映射到任意物理地址。这在后面详讲。
1.3特权级与堆栈问题
X86架构的CPU分了4个特权级,linux只用了0级作内核级,3级作用户级。一般情况下,jmp和call的转移,代码段数据段的访问遵循以下规则:
低---高 |
高---低 |
相同 |
适用情况 |
|
一致代码段 |
Y |
N |
Y |
供用户使用的代码资源,及某些异常处理的系统代码 |
非一致代码段 |
N |
N |
Y |
避免被用户破坏而保护起来的系统代码 |
数据段(非一致) |
N |
Y |
Y |
系统内核可以查看用户数据 |
特权级的表现形式有3种,所有光说低、高还不够明确,而且上述的只是一般的转移,必要时还可以通过调用门来实现不同特权级间的切换。更为确切的比较方法将在下面讲述,首先看一下特权级的3种表现形式。
CPL:正在执行的程序或任务的特权级,有CS、SS的1~0bit体现;
DPL:段或门的特权级,被存储在段描述符或门描述符的DPL字段中;
RPL:由段选择子的1~0bit体现。
下面主要关心在不同特权级间切换时,堆栈的情况。代码在相同特权级间跳转时,堆栈不变,在不同特权级间跳转时,则会用到两个不同的堆栈。
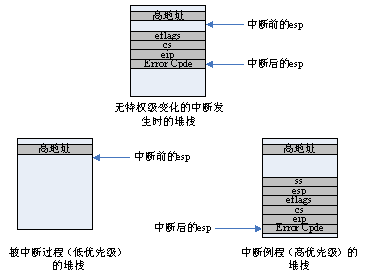
如上图所示,无特权级变化的情况主要发生在内核态的进程被中断时,而用户态下的进程被中断则会发生特权级变化。
从低优先级切换到高优先级,会使用另一个堆栈,并把之前的ss、esp压入新的堆栈,以便返回时可以直接找到以前的堆栈。但是怎么找到高优先级的堆栈的呢?这就需要用到TSS段,每个进程都有自己的TSS段,和LDT一样,TSS段在GDT表中也有相应的描述项,该项由TR寄存器索引,所以进程切换时,和LDTR寄存器一样,TR寄存器也要相应地改。
1.4中断
进程间的切换当然要各种各样的中断来支持。中断一般指程序执行过程中因硬件而随机发生,通常用来处理外部事件,当然软件通过执行int n指令也可以产生中断;异常一般指处理器执行过程中检测到错误,如除零等。总之,它们都是程序执行过程中的强制性转移,转移到相应的处理程序。
保护模式下,x86处理器支持共256个中断异常处理。
0~19 |
是各种异常的向量号,特例,其中2号为非屏蔽中断,9、15号为intel保留的。 |
20~31 |
Intel保留的。 |
32~255 |
用户定义的中断,包括外部中断和int n指令 |
首先看看机器的中断异常的实现机制。异常及软件中断int n,都是程序执行时,遇到相应的指令就跳转,与硬件无关。另外,机器提供两个引脚,实现外部中断,一个是NMI,不可屏蔽中断,一般用作灾难性的处理,如断电等,另一个是INTR引脚,一般连接中断处理芯片8259A来实现外部中断。
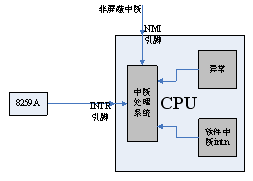
然后看中断向量表IDT,里面有256项,每一项定义了该号中断发生时,应执行的内容。在实模式下,中断向量表中没一项可能就是一条跳转指令,跳到中断处理程序处。而在保护模式下,中断向量表IDT里有256个门描述符,即中断门。每一个中断对应一个中断门描述符,从而找到相应的处理程序,中断门的结构功能与前面讲的调用门几乎是一样的。
所有的中断处理程序都是内核态下的函数,所以我们这里所有的selector都指向唯一的代码段描述符SELECTOR_KERNEL_CS = 0x8,只要设置好每项的offset,指向各个中断处理程序的函数入口。
2.linux0.11内核运行框架
这里致力于弄清楚内核是如何运转起来的,先不关心以什么策略使它运转得更高效。内核运转的关键就是多进程,理清楚进程的几方面是关键。
-
由哪些部分构成
-
何时切换(哪些机制使它切换)
-
怎么切换并保证空间地址、数据不发生错误
进程运行离不开内存,或者说是建立在内存管理之上的,那么内存的情况是怎么样的?针对这两方面,总结出下面这张图。

针对这张图需要说明的几点是:
-
内核kernel本身不会运行,它包含一组内核函数库,为所有进程所共享。系统中时刻都有一个进程在运行,或运行于用户态,或运行于内核态,在内核态下时可用内核函数库。大部分内核函数会设计成可重入的(只有局部变量、堆栈实现),所以允许多个进程同时运行在内核态;但有些函数不可避免的用到全局变量,这时有两种方法,一是运行这些函数的进程不允许被抢占,二是精心设计同步方法。
-
GDT表中有K_CS/K_DS,供进程在内核态下时使用。因为进程进入内核态只有一种可能,就是发生中断,1.4节已经说明了IDG表中所有门描述符的SELECTOR都是SELECTOR_KERNEL_CS = 0x8,因此K_CS/K_DS是被所有进程共用的内核态描述符(基址),即整个内核函数空间是所有进程共享的。
-
内核为每个进程维护了一个task_struct和k_stack,它们通常放在一个页框内,有union结构生成。k_stack则供进程在内核态时用(1.3节已说明不同特权级间的切换会造成堆栈的切换)。Task_struct为进程管理用,主要包含了进程所管理的资源如文件、IO、信号等;还包含了各种运行时的变量属性如优先级、时间片、进程号组等;与运行框架最紧密相关的是LDT表段、TSS段,GDT表中还为每个进程准备了一个LDTn描述符,和一个TSSn描述符,与这两个私有段对应。
-
进程创建时,就在GDT表中为它初始化好LDTn和TSSn,且基址分别指向task_struct中的LDT表段和TSS段。
-
TSS段是支持进程运行、切换的关键,它主要包含3部分关键的内容:1)进程的运行状态(各种寄存器),当要切换到一个进程时,通过ljmp tss_sel指令,tss_sel是TSSn在GDT表中的索引,这可以由进程组号直接得到,处理器首先将该tss_sel装入TR寄存器,然后由GDT表中TSSn找到进程task_struct中的TSS段,弹出TSS段中保存的状态;2)ldt_sel选择子,它是LDTn在GDT表中的索引,ljmp tss_sel指令也会将它装载到LDTR寄存器中,从而使进程正确寻址;3)ss0、esp0指向进程的内核栈顶,若进程在内核态时被中断,堆栈不会切换,用不到esp0,当进程要从内核态切回用户态时,一定保证内核栈中为空了,下次再切到内核态时,仍有esp0指向内核栈顶,所有esp0不需要变化。
-
LDT表段为进程提供正确的线性基址。如一共64个进程,所有进程共享一个页目录表,每个可有16项PDE,16个页表,16*1024项PTE,指向16*1024个页框,共64M的线性地址空间。这样就将线性空间有效分割开了,互不相关,用户程序编译时只需关心offset地址。
-
上述方案共用一个页目录表,从而限制每个进程只有64M线性空间,目前的linux系统通常是每个进程有自己的页目录表,即每个进程完全有一套自己的线性空间,这才是真正的分割、互补相关。此时每个进程可有4G空间,但每次切换进程时应改变CR3寄存器的值(它应该会保存在task_struct中),LDT将不再需要。事实上,目前的linux系统进程状态采用软件保存,TSS段也是不需要的,只要仅一个全局TSS段,用于用户态内核态切换时堆栈的切换,可想而知,每次切换到一个新进程,该全局TSS段的esp0应修改为该进程的k_stack。
-
各个进程有自己的线性空间,但他们对应的物理空间却可以重合。事实上fork出新进程时,它的数据段和代码段是完全父进程重合的(是完全复制了所有页表项)。对于共用的代码,重合当然没有问题,但对于要写的数据段(如堆栈),共享当然不行了,linux采取了写时复制(copy on write)技术,即fork时复制的所有页表项的属性都设为了只读RD,若一个进程试图写时,会发生页故障中断,中断处理程序(参加page.s)会寻找一个新的物理页,修改页表项使其映射到新的物理页,同时把原页中的数据复制到新页上来(这比较耗时的)。
-
如何管理物理页。有K_CS/K_DS可见(基址为0,且limit为整个内存空间),内核态下线性空间和物理空间是一样的,可以用一个数组,记录每个线性页框(实际也对应物理页框)被映射了几次,每次分配页及撤销页时都要维护这个数组。若一个页框被映射了0次,那么它就是空闲的,可用。
上述是我读了一遍代码后,总结而成的。在这探寻过程,实际上是按照一个路径来的,重点看懂几个关键函数后,就能对内核运行框架有一个很好的理解。下面主要来阐述这几个函数。
2.1创建进程fork()
创建进程这样的工作应该是在用户控件调用的,所以这里就不得不提到sys_call系统调用。下面就以fork为例,说明系统调用的工作机制。
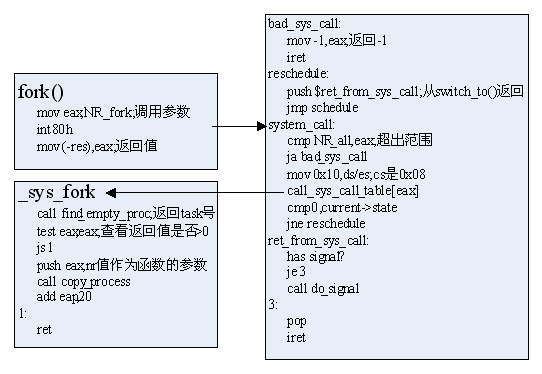
如上图所示,首先将调用号写入eax,比如fork的调用号为NR_fork=2,然后int 80h进入软中断,IGDT表的对应项会指示程序运行到system_call函数;
system_call函数首先判断调用是否在范围内,如linux 0.11版系统调用总数为72;
把ds,es的值设为0x10,即KERNEL_DS。要注意的是,此时的cs已经是0x08(即KERNEL_CS)了,因为IDT表中的所有SELECTOR都是0x08;
根据调用号,从sys_call_table中选择相应的函数执行;
因为系统调用很可能是该进程变为中断状态(如资源的问题),因此必须判断是否要schedule一下。若真schedule了,则会切到另一个进程去执行。当该进程再次被执行时,是从schedule的switch_to函数末尾开始执行的(参见switch_to),它要返回的是ret_from_sys_call,所以事先把该返回地址压栈;
最后还要看一下该进程是否收到信号(查看task_struct中的signal项),若有信号,就去执行do_signal,这是进程间通信的基础,以后再讲。
好了,了解了系统调用,现在来看_sys_fork,它首先找一个空任务,linux0.11最多允许64个进程,内核中维护一个task[64]数组,标示某个task是否存在了。
然后把任务号压栈(注意任务号和进程号的区别),然后调用最关键的函数copy_process。由名字就可知,创建进程实际上是复制了父进程。
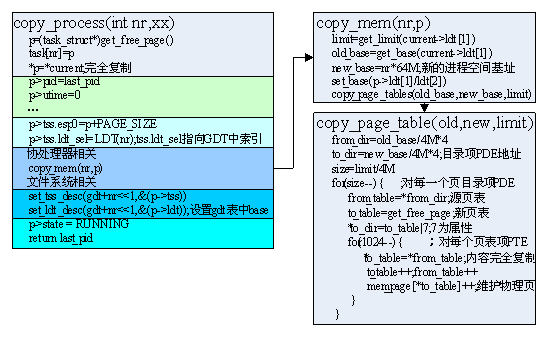
首先获得一个新物理页作为新进程的task_struct,然后其内容完全复制current的;
修改属性值,包括pid,utime等;
修改运行状态值(tss段),主要是esp0指向新进程的内核栈,而且以后都不用变,前面讲过,另外就是ldt_sel,应索引到该进程在GDT中的ldt_sel,其它的如寄存器之类的基本不用改,不过要注意的是eax需改为0,即子进程fork返回的是0;
复制进程空间,这里不是复制内容,而只是复制PDE和页表,使新进程的地址空间与父进程映射到相同的物理页,还有一个很重要的工作就是修改p中LDT段的内容,使其指向新进程空间的基址。
设置gdt表中对应该进程的TSS,LDT描述符,使其指向task_struct中的TSS段和LDT段;
最后设置state为RUNNING,子进程就可以被调度执行了。
关键来看一下copy_mem(nr,p)的工作:
首先获得源基址和段长,新基址为nr*64M,然后修改task_struct中ldt段为新基址。此时新基址有了,但新进程寻址所需的PDE和页表还没有,下面就创建;
获得源PDE和新PDE的地址,注意了这里是内核空间,页目录表的基址为0,base/4M即为第几项,每项大小为4Byte。
获得PDE的总项数,一般就为16项(每项4M,共64M),对每一项,若为空则跳过(可能为空的),若不为空,则:
获得该PDE项对应的页表from_table,新页表需重新获取物理页(每个页表的大小也为一个页框4K),并使新PDE项指向该新页表,但属性设置为只读,为的是写时复制;
新页表中的1024项全部复制源页表的内容,即映射到相同地址空间;
最后,对每个PTE项映射的物理页,都要维护其mem_page[*to_table],即使该物理页的映射次数++。
2.2执行用户程序execve()
execve()函数也要进行一次系统调用,来打造一个全新的进程空间,执行新的程序,它执行完之后,新进程就和原父进程完全不相干了,就连父进程原先为子进程安排在execve()调用之后的那些代码页不存在了。那么首先看看一个新打造出来的进程空间是什么样的呢?主要包括
-
code代码;
-
data全局数据;
-
bss未初始化的全局数据;
-
stack堆栈供进程内函数调用参数、局部变量用;
-
参数即该进程运行的参数,包括程序名,附加参数argv,参数个数argc等。
![]()
相比较这个模型而言,其实execve()所做的事情非常少。
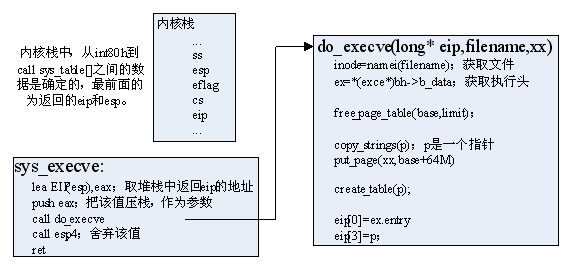 如上图所示,call sys_call_table[]选择了sys_execve执行,首先把内核栈中存放返回eip值的地址赋给eax,并压栈作为参数调用do_execve();
如上图所示,call sys_call_table[]选择了sys_execve执行,首先把内核栈中存放返回eip值的地址赋给eax,并压栈作为参数调用do_execve();
do_execve()首先根据文件名,找到该文件,并获得它的执行头ex;
释放该进程的原地址空间,包括使相应的PDE项清零,相应的页表释放;
获取32个物理页,把程序的运行参数赋值到这些页中,一般而言肯定是绰绰有余的,需注意的是,这里是在内核态,把数据复制到用户态的页表中,需一定的技巧。然后把这32页安排在该进程空间的末尾,这里当然就会填写相应的PDE项,并重新分配页表来指向这些页框;
末尾32页,最末存放的是运行参数,多余的部分作为stack,且此时p指针指向该stack的头。create_table(p)把各运行参数argv,argc的地址写入该stack中,并使p指针相应前移;
最后是神奇的一步,是内核栈中返回eip的值为ex.entry程序入口,esp值为p,即用户态堆栈中。然后该系统调用返回后,就会去执行新的程序了。

可见,execve执行完之后,只是提供了程序的执行入口,并让该进程eip指向该入口处开始执行,但实际的程序却并未加载到进程空间内。执行时,当然会发生缺页错误,这是再到磁盘中的文件中去找所缺的部分加载。这里就要提高linux下可执行文件的格式了,0.11版时用的是a.out格式,现在已经不用了,现在普遍用的是elf格式,它把整个文件分为多个段program,并有一个elf头标示所有这些段头,每个段头又会标识该段应被加载到进程空间中的偏移地址,这些都是编译器自动完成的。所以缺页中断程序只要根据所缺页的偏移地址去文件中找相应的program来加载即可,对于有些没有执行的分支,就不会加载,这样也提高了效率。堆栈也一样,当末128K用完后,会分配新的物理页作为堆栈。
2.3进程退出exit()及等待wait()
进程的退出也是一个系统调用,最终调用的函数实体为do_exit()。在我们写应用程序的时候,有时候中间判断出现异常时,会调用exit(-1)这样的函数来终止进程,但往往我们的main程序不会调用exit,而只是在最后return 1。但实际上,编译器编译时运自动为每个应用程序的末尾加上glibc运行时库中的exit函数来执行exit的系统调用。另外一般父进程会等待子进程的结束,利用wait系统调用。

do_exit()函数比较简单,首先使该进程的PDE清零,释放其占用的页表;
第二步比较关键,遍历所有进程,找到它的所有子进程,将其父重设为task[1],即init进程。若该子进程还在运行,则不用管,它exit时会自动发信号,若该子进程已经处于ZOMBIE状态(但还没有销毁,可能是该父亲并未调用wait),则应重新向新父亲init进程发送SIGCHLD信号(它之前可能已经发过了,但是发给原父亲的),可见init进程会处理所有没被处理的ZOMBIE进程;
释放该进程占用的文件、tty等系统资源,并将其状态设为ZOMBIE;
最后通知父进程,即向父进程发送SIGCHLD信号,由上面可知,父进程至少为init进程,然后执行调度。
有do_exit()的实现来看,有两点需注意:
-
作为子进程,它调用exit后,其实并未真正销毁,而是变为了ZOMBIE状态,不会再次被调用,等待其父进程来销毁;
-
作为父进程,它调用exit时,要么其所有子进程都被他调用wait时销毁了,而若还没全销毁,或压根它就没调用wait去处理它的子进程,那么它在exit是也至少会将这些子进程的父亲指向init进程。
父进程一般调用waitpid来等待子进程结束,并销毁其task_struct。其工作情况如上图所示,这段代码有点别扭。
首先置flag=0,根据pid值找相应的进程,或者是一个特定的子进程、或是一组、或pid=-1时就找所有的进程;
若该进程的状态为ZOMBIE了,则releas它的task_struct,并返回其pid。这里可见它只要销毁一个进程就会返回,所以一般父进程有多个子进程时,会循环调用wait直到销毁了它想要销毁的那个;
若该进程还没终止,则置flag=1,然后执行下面的if()框架:置自己的state为中断状态,即挂起自己,然后调用执行其它进程;
直到它再次被唤醒时(是被信号唤醒的),它继续从schedule()下面开始执行,若仅是被SIGCHLD唤醒,则继续回去寻找子进程来销毁,否则就返回-1。这里也说明,父进程中需循环调用wait。
2.4初始函数main()
前面讲了进程的创建、打造、终止,任何事物都要有个最原始的,那么最原始的进程哪来的呢?上面多次提到的init进程又是怎么回事呢?那就要去看main函数,它是内核执行完head.s代码后就开始执行的,事实上我是先看它,再寻这看完上面的那些函数的,看完之后再回头来看它,会发现结构更加清晰了。

main()之前是head.s代码,整个系统还是串行控制,还不存在多进程。进行一些初始化initial()后,执行关键的一步mov_to_user_model(),它假装push了esp、eip等值到堆栈中,然后iret,弹出堆栈中的数据到相应寄存器中,注意这里的ss、cs都是LDT选择子,LDT段应该在task_struct中,task[0]的task_struct在initial中就准备好了,其中的LDT段的base都为0。这里就有几点需注意的地方了:
-
先看esp、eip的值就不难发现,0号task的进程体和内核是重合的,用户态堆栈就是head.s用的堆栈;
-
而0号task的内核态堆栈是和其task_struct联合union在一起的,而这个union体是认为地初始化在内核空间的(低1M地址内),这是一个特殊,以后所有的进程的task_struct都会在主存(高于1M)中分配新页框;
-
这以后就不存在串行控制路劲了,即head.s用的那个堆栈却是不会再被内核用了,而只是作为task0的用户堆栈,以后任意时刻,系统中都是一个进程在执行,或在用户态,或在内核态,整个内核空间的函数是被所有进程共享的;
然后task0会fork出task1,即为init进程,这之后task0就进入休眠,循环执行pause(),事实上,一个进程执行pause()系统调用后,会变为挂起状态INTERRUPTIBLE,然后调用schedule(),直到被信号唤醒,而实际上不会有进程发信号给task0,那么task0到底会不会被执行呢?会!这就需看schedule()函数中的一个编程小技巧了,它在调度时,是从task1开始遍历的,但最后若发现没有可运行的进程,则会启动task0,与task0一直是INTERRUPTIBLE无关。Task0也不干事,反正就是一直再挂起,再schedule(),直到有可运行的其它进程。
再来看init进程,它首先fork出一个子进程去执行/bin/sh程序,然后等待该子进程退出,该子进程会退出吗?会的!应该执行参数argv1不对,这只是为了初始化一下环境,详细参加sh程序;
然后它重新fork出一个子进程,以正确的参数执行/bin/sh程序,然后等待子进程的退出,注意了,它用的是wait,实际上是waitpid的一个封转,即参数pid=-1,找所有的子进程。所有失去父亲未被销毁的进程都会指向init进程,所以它循环调用wait来销毁所有ZOMBIE进程,直到它本身的那个子进程,即sh程序终止,才退出这个循环。
Sh程序会终止吗?会的,输入命令exit它就终止啦!终止后init进程又会进while(1)循环,即再次fork来运行sh程序,那时候还没有用户界面,linux反正就是一直运行sh,sh可以创建进程来执行。
第二部分 内核的血肉
上面讲了内核的运行框架,有了这个框架,内核就可以运转了,上述内容阐述了,用户可以方便地通过内核(系统调用)创建进程、打造进程、销毁进程。但一个OS内核要能被用户使用,还必须包含一个具体的系统调用接口,这些接口主要分为几个大部分,也就是教科书上讲的如文件系统、设备驱动、网络等,另外要使内核运转得高效,满足用户的需求,还必须为它设计各种运行策略,如调度方法、进程间通信方法等。
总的来讲,这些内容一般都是教课书上津津乐道的内容,在前面学习内容的基础上,再来看这里的内容,会觉得更清晰一点。
看的也不深入,讲的不多。
3.进程调度
Linux0.11版本的进程调度比较简单,效率比较低,它实际上就是遍历所有可运行进程,是一个O(n)复杂度的算法,现代linux的调度算法已相当成熟,引入了等待队列的思想,利用红黑树实现了一种O(1)时间复杂度的调度算法。但通过对0.11版的调度程序的学习,可以很好的理解调度程序时干嘛的,什么时候、怎么样来完成这样的事情。
首先看进程调度发生在那些情况下。总结一下,主要有3个地方会发生schedule:1)时钟中断,这是最重要的一项,把保证一个进程不会永远占用CPU;2)在sys_call中,执行完相应的sys_call_table[]的函数后,sys_call主体函数会判断current->state是否还是RUNNING,因为这过程中可能因为资源、信号等是该进程阻塞,若不是了,就schedule;3)一个sys_call_table[]函数本身就是专门为了调度的,如pause()、exit()、sleep_on()、waitpid()等,它们往往使该进程state变为非RUNNING,然后直接调用scheduel,注意与第二种稍有区别。
进程调度总体上分为两部分内容,一个各进程状态的转换,二是调度。
3.1进程状态转换
进程调度是指,在所有RUNNING状态的进程中选择一个最合适的进程来执行。那其它状态的呢?ZOMBIE就不看了,已经是将死,不会再被调度,STOP在0.11版还没用,另外就是INTERRUPTIBLE和UNINTERRUPTIBLE。
UNTERRUPTIBLE状态是不能被信号唤醒的,它一般是进程执行时需要用到某个资源如文件IO等,而此时此资源被其它进程占用,那它就调用sleep_on()进入UNINTERRUPTIBLE,只有当该资源释放时,才会调用wake_up()唤醒该进程。它不能被信号唤醒。
INTERRUPTION则是和资源无关,它更多是为了兼顾多进程执行的顺序安排而设置的,最简单的就是前面讲的wait()调用,使父进程处于INTERRUPTION状态,直到子进程终止发送SIGCHLD信号给它,它才被唤醒。它当然可以被wake_up()唤醒。
3.2进程调度
下面看schedule函数的总体框架:

首先遍历所有进程,找出过期进程,置SIGALARM信号。Jiffies是内核维护的全局变量,是系统启动开始所经过的滴答数,10ms/滴答。若一个进程预期在一个时间之前完成,过期的则会进行相应处理,那就是SIGALARM信号的处理,这里就不多讲了。并且还找所有state为INTERRUPTIBLE的进程,若它受到信号,则置RUNNING。
然后遍历所有进程,找出具有最大counter值的进程作为下一个执行进程。若所有task的counter都为0了,就将所有task的counter重置为f(priority)(关于priority的函数)。这里的counter就是常常说的动态优先级,进程每执行一次,counter--,priority就是常说的静态优先级。
上面的过程还清楚地显示出INTERRUPTIBLE进程如何被信号唤醒的过程,但对UNINTERRUPTIBLE却不涉及,那它的状态转换又是在哪呢?
前面也提到UNINTERRUPTIBLE是和资源息息相关的,原来每个资源如文件(0.11版内核所有进程的打开文件和<64,由file_table[64]维护,每个进程最多有20个文件,有每个task_struct中的filp[20]维护),内核中都为它维护一个等待队列,该队列对所有进程可见(通过file_table[64])。
每当进程去使用一个正被其它进程使用的资源时(一定在内核态中),该进程就会执行到sleep_on()分支上去,变为UNINTERRUPTIBLE状态。当另一个进程(在内核态中)释放了该资源,那么它也会执行到一个分支上去,查看该资源的等待队列,对其中一个调用wake_up()唤醒。
4进程间通信
前面讲了信号的唤醒机制,而实际上,信号并不是专门为唤醒设计的,它最主要的设计意图是为了实现一套进程间通信机制。比如两个都是RUNNING状态的进程,其中一个向另一个发送一个信号,该进程收到信号时,就可以执行一段相应的功能代码。
4.1用户态执行模型分析
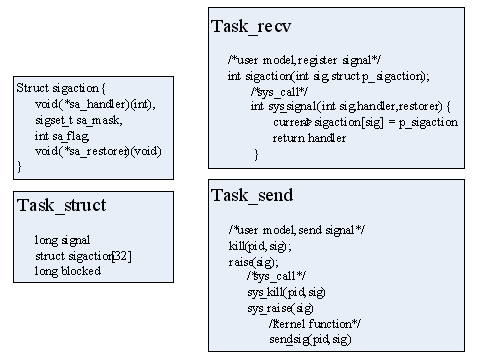
首先看用户怎么使用这套机制的,一般在linux下多进程编程,会使用信号通信。首先要知道的是,信号中最重要的一个数据结构时sigaction,它包括一个sa_handler处理函数和sa_restorer返回函数;每个进程的task_struct中有三项信号相关的,signal为一个32bit的信号位图,blocked是阻塞位图,sigaction[32]对应每个信号。
一般一个进程task-receve中需注册某信号的处理函数,int sigaction(int sig,struct sigaction)是一个用户态函数,定义在glibc中,它实际上是执行一个系统调用sys_signal,把该sigaction写到task_struct中。要注意的是这里的sa_handler和sa_restorer是处理函数的指针,即一个函数入口地址,且是用户态下的地址。在系统调用中(内核态下),仅是用的这个用户态地址(实际上只是把这个地址压入栈中eip位置,后面会看到),而并不会去执行这个用户态函数,所以这里是没问题的。
另一个进程task-send向该进程发送信号,一般用glibc中的函数kill(pid,sig),raise(sig)等,它们最终也是系统调用sys_kill(),sys_raise()等,并最终会调用内核函数send_sig(pid,sig),将pid所指进程的task_struct中的signal字段的相应bit置位。
这样,当task-receve发现收到信号后(一般是在sys_call中发现的),就会根据它注册过的sigaction来对进程进行一番打造,使得它执行一个sa_handler,然后继续沿原路径执行。
4.2内核态打造过程分析
关键就是看进程如何发现信号,并如何让进程插入一段执行sa_handler,且不影响原进程的控制路径(即只是在原路径中插入一段sa_handler)。
前面讲了信号是内核控制的task_struct中的组成部分,用户是不可见的,所以发现信号一定要进程在内核态下,也就是说,用户进程一定要在运行到内核态后才会执行信号处理工作,各个能使进程进入内核态的点,一般称为陷入点(这个名词好像不对,记不清了)。实际上在讲sys_call的时候,略去了ret_from_sys_call部分的关于信号处理的部分,现在来看。
 系统调用sys_call的最后部分首先判断是否是在内核态下调用该sys_call的(好像这种情况不存在),是的话就不处理信号,因为信号是要处理用户态堆栈的。
系统调用sys_call的最后部分首先判断是否是在内核态下调用该sys_call的(好像这种情况不存在),是的话就不处理信号,因为信号是要处理用户态堆栈的。
然后判断有无收到信号,即看task_struct中的位图有无置位的,有的话则取最低一位的信号,转化成数型,压入堆栈,作为参数调用do_signal。为什么只取最低一位呢?其它信号就无效了吗?0.11版貌似这里做的不完善。
和之前execve函数一样,从sys_call到这里的call do_signal,内核态堆栈中的数据是固定的,最开头是返回到用户态的(一定是用户态,前面提到了内核态下系统调用是不处理信号的)eip、cs、eflag、esp、ss,它们都作为do_signal的参数。其中eip是设为了long型,esp是设为了long *型,其实都一样,都是32bit的数(一个地址),这样做只是方便c语言的编程。
Do_signal()函数首先根据signr值在task_struct中找到相应的sigaction,然后进行最重要的两步:
-
一是把内核栈中eip的值该为sa_handler(函数入口地址);
-
二是把内核栈中esp值减去7或8,即在返回后的用户态堆栈开辟一小段,并在其中填入一系列数据,注意这里是在内核态向用户态空间写数据,需要一定的技巧,这里封装了put_fs_long()。
这样一打造后,情况如下图所示:

可以看到打造之后,从sys_call返回后,eip指向用户空间的sa_handler函数体,且esp指向新用户堆栈的新处,进程就开始执行sa_handler;
执行完之后,返回ret,因为这是在一个空间内,是short jmp,所以只需要堆栈中弹出eip值即可,而这个值正是do_signal写入的sa_restorer的入口地址,那么程序就开始执行sa_restorer;
Sa_restorer也是一个用户态的函数,不过一般不需要用户定义,其功能单一固定,就是让进程回到原来位置处,glibc中已经为我们定义好了,如上图右侧所示。
它弹出先前do_signal中写入用户堆栈的一些列数据,直到old_eip(那些写入的数据好像没用到,可能只是linus想测试一下),然后ret,同样是short jmp,堆栈中的old_eip正好就是指向原进程断点的位置,则进程又会回到原地方继续执行了。
5.文件系统
Linux0.11版完全借用了minix的文件系统,现代linux的文件系统已有了很大发展,尤其是加入了虚拟文件系统后,功能更加完善,可以识别多种文件系统。这部分内容以后再慢慢学。不过从minix文件系统还是可以学到一些最基础的文件系统方面的内容。
在磁盘中,文件系统包括超级快,节点映射,区映射,节点,数据等,前几部分的内容固定,且存放在磁盘固定位置,一般是磁盘开始位置,操作系统挂载一个磁盘文件系统时,就是通过读取这些磁盘块的内容,然后再去索引各个文件的。因此若磁盘的这些关键部分坏了,则文件很可能读不到,就如引导扇区坏了则无法引导OS一样。
在内存中,内核长期维护着每个文件系统的超级块,另外内存中有一块区域成为缓存,它有一块一块组成,用来存放读到内存中的磁盘块,且一一对应,满了之后会交换出去。在频繁对某些文件操作时,这样做可以提高效率。
在进程级别,每个进程的task_struct中有filp[20],即每个进程最多可以打开20个文件,另外整个内核维护一个file_table[64],即整个系统中最多同时存在64个打开文件,它们之间有映射关系。对进程而言,它自认为是独享20个文件的,每次进程要使用文件时,它必是系统调用进入内核态,然后内核会在file_table中找到与它对应的文件,若发现该文件正在被其它进程使用,则会挂起这个进程。前面也提到了,每个文件资源(这里指file_table中的)都有一个和它对应的等待队列。
另外一点,linux中设备也被当成是特殊文件的,设备驱动的编写。