使用styleGAN-encoder对其他模型进行生成控制
目录
- 前言
- 生成反向模型
- 反算潜码并生成头像
- 改进重生成
- 特征混合
- TODO
前言
上篇文章说到由于储存库的作者只给出了针对karras2019stylegan-ffhq-1024x1024.pkl这个人脸生成模型的反向模型.我尝试了对2019-03-08-stylegan-animefaces-network-02051-021980.pkl使用该方法重生成动漫人脸,却发现生成出来的效果很差.于是打算自己训练个针对2019-03-08-stylegan-animefaces-network-02051-021980.pkl的反向模型出来.
2019-03-08-stylegan-animefaces-network-02051-021980.pkl是个能生成512*512大小的动漫人物头像的预训练模型.下载链接如下:
https://pan.baidu.com/s/1bPUZW_H3Xd55ftNvCAfWgg 提取码: 1926
下好后放在./models/文件夹下.
我们的目的是用这个新的模型来完成上一篇文章中的效果,由于我们要使用新的StyleGAN模型,因此我们需要注意的有以下几点.
- 该模型生成的是512*512的图像(而不是默认的1024*1024),对应的潜码大小为16*512(而不是默认的18*512)
- 需要生成对应于该模型的反向模型(
finetuned_resnet.h5)
生成反向模型
我们的反向模型是以resnet为基础,使用StyleGAN的生成进行微调得到的.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 256, 256, 3) 0
_________________________________________________________________
resnet50v2 (Model) (None, 8, 8, 2048) 23564800
_________________________________________________________________
conv2d_1 (Conv2D) (None, 8, 8, 512) 1049088
_________________________________________________________________
reshape_1 (Reshape) (None, 128, 256) 0
_________________________________________________________________
locally_connected1d_1 (Local (None, 128, 64) 2105344
_________________________________________________________________
permute_1 (Permute) (None, 64, 128) 0
_________________________________________________________________
locally_connected1d_2 (Local (None, 64, 128) 1056768
_________________________________________________________________
permute_2 (Permute) (None, 128, 64) 0
_________________________________________________________________
reshape_2 (Reshape) (None, 16, 512) 0
=================================================================
Total params: 27,776,000
Trainable params: 27,730,560
Non-trainable params: 45,440
_________________________________________________________________
接下来我们需要训练(微调)一个针对2019-03-08-stylegan-animefaces-network-02051-021980.pkl的反向模型
先将./data/中之前下载的的finetuned_resnet.h5移除或改名.
修改train_resnet.py
"""
with dnnlib.util.open_url(args.model_url, cache_dir=config.cache_dir) as f:
generator_network, discriminator_network, Gs_network = pickle.load(f)
"""
# 加载StyleGAN模型
# Model = './models/karras2019stylegan-ffhq-1024x1024.pkl'
Model = './models/2019-03-08-stylegan-animefaces-network-02051-021980.pkl'
model_file = glob.glob(Model)
if len(model_file) == 1:
model_file = open(model_file[0], "rb")
else:
raise Exception('Failed to find the model')
generator_network, discriminator_network, Gs_network = pickle.load(model_file)
在项目根目录下运行
python train_resnet.py --model_res 512 --test_size 256 --batch_size 1024 --loop 1 --max_patience 1
等待运行完毕,就可以在./data/中找到新生成的finetuned_resnet.h5
也可以下载我训练好的finetuned_resnet_anime.h5
https://pan.baidu.com/s/1PrguxJpGM1dlw_3enRGY7A 提取码: 1926
下载完成后放到./data/中并改名为finetuned_resnet.h5
反算潜码并生成头像
先修改.\encode_images.py中的Model路径
# Initialize generator and perceptual model
tflib.init_tf()
"""
with dnnlib.util.open_url(args.model_url, cache_dir=config.cache_dir) as f:
generator_network, discriminator_network, Gs_network = pickle.load(f)
"""
# 加载StyleGAN模型
# Model = './models/karras2019stylegan-ffhq-1024x1024.pkl'
Model = './models/2019-03-08-stylegan-animefaces-network-02051-021980.pkl'
model_file = glob.glob(Model)
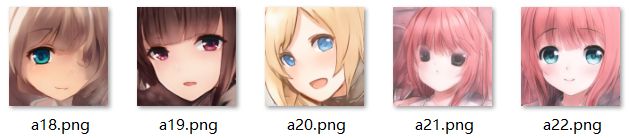
将截好的动漫人物头像直接放置在aligned_images文件夹中.

你问我为什么要把脸截得那么大?这你就要问训练2019-03-08-stylegan-animefaces-network-02051-021980.pkl这个模型的人了,为什么截取的训练样本都是这么大的.顺便图a21.png和图a22.png可以对比下截得不同尺寸的重生成效果.
在项目根目录下运行
python encode_images.py aligned_images/ generated_images/ latent_representations/ --model_res 512
注意多了个参数--model_res 512
在latent_representations文件夹中查看提取的潜码
在generated_images文件夹中查看重生成的人脸
改进重生成
由于感觉重生成的效果不是很好,于是思考了几个问题
- 是不是反向模型训练得不够?
刚刚我们训练反向模型的时候只训练了一个迭代--loop 1(毕竟要做的是finetune)
所以这次我给它设置了个无限迭代,然后去睡觉了(毕竟动漫头像和人脸差别还是有点大的,微调不行就粗调吧).
python train_resnet.py --model_res 512 --test_size 256 --batch_size 1024 --loop -1 --max_patience 3
大概十个小时过去后,模型的test loss下降到0.00588,称为粗调模型.
https://pan.baidu.com/s/1dhZb5DvhSMnaOkqLkibnwA 提取码: 1926
又训练了个迭代了10次,test loss为0.00695的模型,称为中调模型.
https://pan.baidu.com/s/11dbEKsgIpWlvkHinJvR_cQ 提取码: 1926
拿几张之前训练得不好的图像试一下
微调模型(默认)+100迭代(默认)

中调模型+100迭代(默认)

粗调模型+100迭代(默认)

- 是不是求解潜码时迭代不够多?
encode_images.py中设置的默认迭代数是--iterations 100,我们尝试增加迭代数到1000,降低了学习率并且降低对dlatents的L1惩罚.
pbaylies/stylegan-encoder储存库的作者认为,这么做可以在StyleGAN所熟知的范围之外允许更大的变化,使得重生成的图像更接近原始图像.
python encode_images.py --model_res 512 --output_video=True --lr=0.002 --iterations=1000 --use_l1_penalty=0.2 aligned_images/ generated_images/ latent_representations/
微调模型(默认)+1000迭代

中调模型+1000迭代

粗调模型+1000迭代

对比发现,对反向模型进行一定程度的训练可以明显提升重生成的质量.
通过储存库原作者的增加迭代数等方法也可以改善生成质量,但是生成速度实在是太慢了.
特征混合
修改mix_style.py(代码在上一篇文章)中的模型路径
# 已训练好的styleGAN模型路径
# Model = './models/karras2019stylegan-ffhq-1024x1024.pkl'
Model = './models/2019-03-08-stylegan-animefaces-network-02051-021980.pkl'
导入mix_style.py
from mix_style import *
特征混合
change_style_figure('change-style-figure.png', 'a19', 'a22', Gs,
style_ranges=[range(0, 4), range(4, 8), range(8, 16)]) # 混合

逐渐变化
change_style_figure('change-style-figure.png', 'a20', 'a22', Gs,
style_ranges=[range(i, 16) for i in range(9, 0, -3)]) # 逐渐
上一篇文章还提到了使用预置的向量来定向改变图片,理论上来说对应真人的向量对动漫人物应该是无效的,反正先试试
smile_direction = np.load('ffhq_dataset/latent_directions/smile.npy')
gender_direction = np.load('ffhq_dataset/latent_directions/gender.npy')
age_direction = np.load('ffhq_dataset/latent_directions/age.npy')
修改年龄
latent = np.load(os.path.join(config.dlatents_dir, 'a22.npy'))
move_and_show(latent, age_direction[:16], range(-8, 7, 2), Gs)
表情变了

修改性别
latent = np.load(os.path.join(config.dlatents_dir, 'a22.npy'))
move_and_show(latent, gender_direction[:16]*2, range(-3, 4), Gs)
样子变了

修改笑容
latent = np.load(os.path.join(config.dlatents_dir, 'a2.npy'))
move_and_show(latent, smile_direction[:16]*2, range(-2, 5), Gs)
…反正不是根据我们要求改变的,这样是不行的.

TODO
接下来打算研究下如何生成能定向控制图片生成的向量.