论文索引记录1
StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators
Training generators with limited data
Transfer learning
In the transfer-learning scenario, ‘few’ typically refers to numbers ranging from several hundred to as few as five.
When training with extremely limited data, a primary concern is staving off mode-collapse or overfitting, to successfully transfer the diversity of the source generator to the target domain.
[35]Few-shot image generation via cross-domain correspondence.2021
Some place restrictions on the space of modified weights.
[31]Sangwoo Mo, Minsu Cho, and Jinwoo Shin. Freeze the discriminator: a simple baseline for fine-tuning gans. In CVPR AI for Content Creation Workshop, 2020.
[38] Justin NM Pinkney and Doron Adler. Resolution
dependent gan interpolation for controllable image
synthesis between domains. arXiv preprint
arXiv:2010.05334, 2020.
[41] Esther Robb, Wen-Sheng Chu, Abhishek Kumar, and Jia-Bin Huang. Few-shot adaptation of generative adversarial networks. ArXiv, abs/2010.11943, 2020.
Others introduce new parameters to control channel-wise statistics [34], steer sampling towards suitable regions of the latent space [55], add regularization terms [28, 51] or enforce cross-domain consistency while adapting to a target style [35].
[34] Atsuhiro Noguchi and Tatsuya Harada. Image generation from small datasets via batch statistics adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2750–2758, 2019.
[55] Yaxing Wang, Abel Gonzalez-Garcia, David Berga,Luis Herranz, Fahad Shahbaz Khan, and Joost van de Weijer. Minegan: Effective knowledge transfer from gans to target domains with few images. In The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
[28] Yijun Li, Richard Zhang, Jingwan Lu, and Eli Shechtman. Few-shot image generation with elastic weight consolidation. arXiv preprint arXiv:2012.02780,
2020.
[51] Hung-Yu Tseng, Lu Jiang, Ce Liu, Ming-Hsuan
Yang, and Weilong Yang. Regularizing generative
adversarial networks under limited data. ArXiv,
abs/2104.03310, 2021.
[35] Utkarsh Ojha, Yijun Li, Jingwan Lu, Alexei A Efros,Yong Jae Lee, Eli Shechtman, and Richard Zhang. Few-shot image generation via cross-domain correspondence.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,pages 10743–10752, 2021.
问题
what is adversarial solutions?
why name is stylegan-NADA?
引入
The third approach, which we adapt, uses CLIP to discover global directions of disentangled change in the latent space.They modify individual latent-code entries, and determine which ones induce an image-space change that is co-linear with the direction between two textual descriptors (denoting the source and desired target) in CLIP-space.
However, these approaches all share the limitation common to latent space editing methods - the modifications that they can apply are largely constrained to the domain of the pre-trained generator. As such, they can allow for changes in hairstyle, expressions, or even convert a wolf to a lion if the generator has seen both - but they cannot convert a photo to a painting, or produce cats when trained on dogs.
问题
Our goal is to shift a pre-trained generator from a given source domain to a new target domain, described only through textual prompts, with no images. As a source ofsupervision, we use only a pre-trained CLIP model.
We approach the task through two key questions:
(1) How can we best distill the semantic information encapsulated in CLIP?
(2) How should we regularize the optimization process to avoid adversarial solutions and mode collapse?


Second, it is harder for the network to converge to adversarial solutions, because it has to engineer perturbations that fool CLIP across an infinite set of different instances.
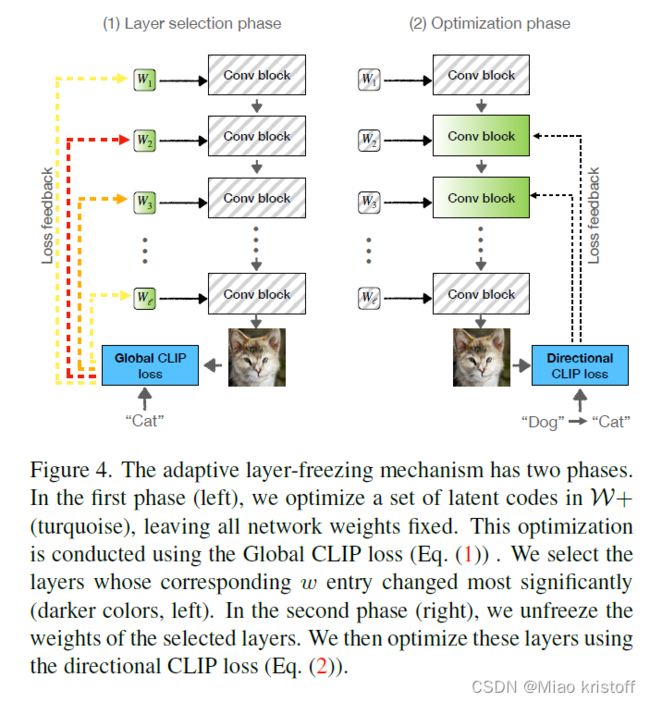
Prior works on few-shot domain adaptation observed that the quality of synthesized results can be significantly improved by restricting training to a subset of network weights[31, 41].
In the case of StyleGAN, it has been shown that codes provided to different network layers, influence different semantic attributes. Thus, by considering editing directions in the W+ space [2] – the latent space where each layer of StyleGAN can be provided with a different code w i w_i wi– we can identify which layers are most strongly tied to a given change.
In all cases we additionally freeze StyleGAN’s mapping network, affine code transformations, and all toRGB layers.
Building on this intuition, we suggest a training scheme, where at each iteration we (i) select the k most relevant layers, and (ii) perform a single training step where we optimize only these layers, while freezing all others.