10 分钟解释 StyleGAN
一、说明
StyleGAN是一种真正推动 GAN 最先进技术向前发展的 GAN 类型。当Karras 等人的论文 介绍 StyleGAN 时,“一种基于样式的生成对抗网络生成器架构”。(2018)出现后,GAN 需要大量的正则化,并且无法产生今天所熟知的令人惊叹的结果。其他人都建立在 StyleGAN1 成功的基础上,我们现在已经达到了 StyleGAN3,并进行了进一步的细化和改进。
在本文中,我们将深入探讨 StyleGAN 架构。然后,我们将查看每个单独的 StyleGAN 组件并详细讨论它。通过这种方式,您还将了解高级细节之外的内容,并了解每个单独组件的影响。
你准备好了吗?我们走吧!
二、StyleGAN,高级概述
下图展示了 StyleGAN 的高级架构,如 Karras 等人所述。(2018)。
涉及两个垂直块:
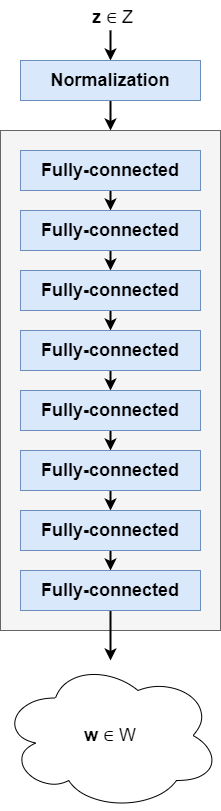
- 映射网络(称为 f)在左侧可见。它将一个(归一化的)潜在向量z ε Z 映射到中间潜在空间中的另一个向量w ,称为 W。该映射网络是一组简单的全连接前馈层。
- 合成网络称为 g(在右侧可见),它使用w生成控制图像合成过程的“样式”。它以一个常量、4 *4 * 512 维向量开始。生成缩放噪声样本 (B) 并将其添加到该常量张量中。随后,通过自适应实例归一化 (AdaIN) 操作添加样式 (A),然后应用卷积运算。接下来是另一个噪声添加和基于 AdaIN 的造型操作。然后我们得到一个 4x4 像素分辨率的图像。在下一个块中,对图像进行上采样,并再次执行相同的操作,达到 8x8 像素分辨率。重复此操作,直到图像达到 1024x1024 像素。
显然,我们已经可以看到经典 GAN 和 StyleGAN 之间的巨大差异。潜在向量z不再直接用于图像合成过程。有趣的是,甚至让 StyleGAN 论文的作者感到惊讶的是,从恒定张量开始是可能的,甚至产生了良好的结果。
z现在不再是图像合成过程的基础,而是用于生成控制合成过程的样式。
如果您不理解上面所写的所有内容,请不要担心。这是一个极端的总结,只强调了高层次上发生的事情。如果您想深入了解 StyleGAN,现在让我们花一些时间查看细节。但是,如果您无法理解基本的 GAN 概念(例如潜在空间或潜在向量),那么最好先阅读我关于 GAN 的文章。

StyleGAN 架构:来源 Kerras at al.,2018
2.1 StyleGAN 的更多细节
现在,我们将更详细地研究映射和合成网络及其各个组件。这可以让您详细了解 StyleGAN 的工作原理。
2.1.1 映射网络f
我们从映射网络开始,也称为 f。它采用从原始潜在分布中采样的潜在向量z并执行到中间潜在向量w的学习映射。这种映射是通过神经网络中的一堆全连接层来执行的。
潜在向量 z 采样
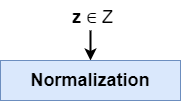
在任何前向传递之前(无论是在训练还是推理期间),潜在向量z都是从原始潜在分布中采样的。
标准正态分布用于映射 StyleGAN 中的潜在向量z。这是 GAN 中常见的采样分布。根据论文,其潜在空间是 512 维(Karras et al., 2018)。
潜在向量归一化
当输入没有标准化或者更好的是标准化时,神经网络会因表现不佳而臭名昭著。通过标准化 步骤,向量可以准备好输入。最小-最大归一化是选项之一。标准化也是如此。
如果您在 StyleGAN 实现中使用标准 正态分布,则是否需要此标准化步骤是值得怀疑的 - 因为您的输入已经具有零均值和单位方差。不过,保留它并没有什么坏处。
用于生成中间潜在向量 w 的全连接前馈层堆栈
您的(可能标准化的)采样潜在向量z现在已准备好输入。它被馈送到实际的映射网络,该网络是一个具有 8 个可训练的全连接(或密集)层的神经网络,也称为多层感知器或 MLP。它产生另一个向量,一个中间潜在向量w。这是合成网络将用于生成输出图像的潜在向量。
该映射是非线性的,这意味着每个全连接层都有一个激活函数,通常是 ReLU 或 LeakyReLU 函数。
中间潜在向量 w 也是 512 维(Karras 等人,2018)。
现在,您可能会问的问题是:为什么我们首先需要这样的映射?
为此,我们必须了解一个称为纠缠的概念(与量子力学中的纠缠无关)。当某物纠缠在一起时,它“已被扭曲在一起或被卡住”。
如果潜在空间被解开,它将包含线性子空间(Karras 等人,2018)。在普通英语中,这意味着潜在空间的某些维度控制着图像的某些方面。
例如,如果我们的 512 维潜在空间 Z 完全解开并成为在面部上训练的 GAN 的一部分,则维度 1 将控制眼镜,维度 2 控制头发,维度 3 面部形状等。通过简单地在一个维度上移动,人们就可以完全控制一小部分,并且生成选择的图像将非常容易。
不幸的是,GAN 通常没有解开的空间。我们之前就看到过——经典的 GAN 无法让机器学习工程师对其潜在空间进行控制。这是潜在空间纠缠的一种更简单的写法。
作者提出,让映射网络将最初采样的潜在向量z从学习到的中间潜在分布 W 转换为中间向量w,确保合成过程的采样不是从固定分布完成的——例如标准正态分布它的所有特征和特质。相反,它是根据学习的分布执行的。这种学习到的分布是通过尽可能解开的方式学习的,这源于来自生成器的压力,因为这样做会产生更好的结果(Karras 等人,2018)。
事实上,与真实图像的数据分布相比,拥有这样的网络可以改善描述分布纠缠的所有指标以及根据学习的潜在分布执行的最终合成。由于映射网络中的 8 层产生了最佳结果,因此选择 8 层(Karras 等人,2018)。
所以,换句话说:
- 潜在向量z是从选定的分布(通常是标准正态分布)中采样的,并且是 512 维的。
- 它通过 8 层非线性 MLP 馈送,产生 512 维中间潜在向量w,合成网络将使用该向量来控制所生成图像的样式。
- 非线性学习映射对于减少合成网络(生成器)使用的潜在空间的纠缠是必要的。这使得 StyleGAN 能够显着提高对潜在空间的控制并产生更好的结果。
2.1.2 合成网络g
现在我们了解了映射网络为何产生中间潜在向量以及它是如何做到的,现在是时候看看它如何用于生成输出图像了。换句话说,我们来看看合成网络。该网络也称为 g。

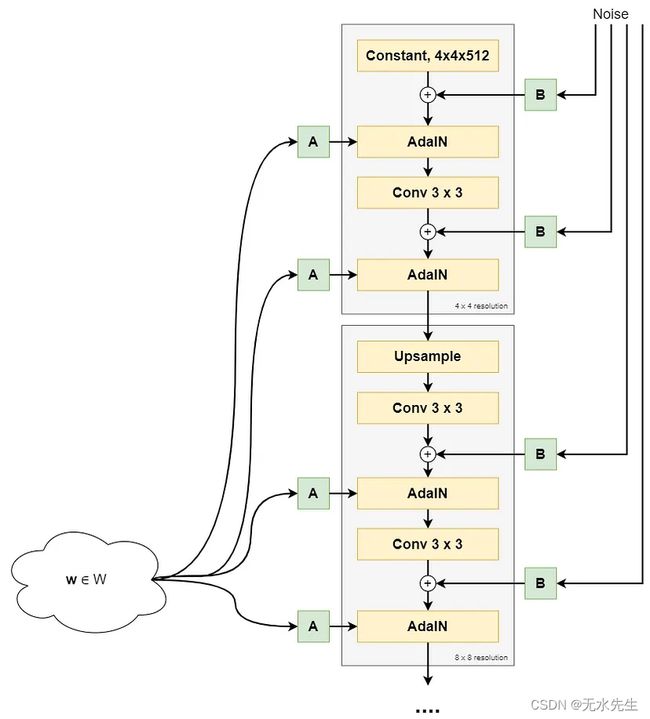
综合网络第一部分的高级概述,高达并包括 8x8 分辨率
2.1.3 合成块
在上图中,您可以看到 StyleGAN 的合成网络利用合成块,通过将图像分辨率从 4x4 上采样到 8x8、16x16……最终到 1024x1024 像素来逐步构建图像。
每个 StyleGAN 合成模块的核心组件是:
- 上采样(第一个合成块除外)。前一个合成块的输出变大,以便随后进行处理。
- 卷积层。
- 自适应实例标准化(AdaIN)。
- 风格向量 (A) 和噪声向量 (B)。
接下来我们将更详细地了解每个单独的组件。然后您将发现 StyleGAN 中每个组件的作用。让我们首先从第一个合成块的起点开始:Constant构建图像的张量!
第一个综合块中的恒定起点
是的,你没听错——StyleGAN 的合成块的起点是一个常数值。
与之前的 GAN 相比,这是一个完全不同的设计,之前的 GAN 都是从潜在空间中抽取样本开始的。
该输入被学习并初始化为 1(Karras 等人,2018)。换句话说,在每个纪元之后,常数都会略有变化 - 但在每个纪元内,它保持不变。
风格和噪音,两个重要的合成元素
常数张量现在由合成块的其余部分处理。尽管我们现在将更详细地讨论该块中的每个组件,但重要的是要知道将返回两个高级概念:
- 风格。常量就像用于任何类型合成的“主干”。就像具有特定风格的画家一样,生成的图像中的高级组件由所谓的“风格”进行调整。
- 噪音。如果您将相同的常量张量提供给具有相同样式的合成块,您将一次又一次地获得完全相同的图像。这是不现实的:您会读到风对某人的形象产生影响。换句话说,生成图片存在随机性,这是通过噪声实现的。
2.2 噪声是如何产生和添加的

Constant 值发生的第一件事是向其中添加了噪声。当人们注意到图片中的头发时,就可以最好地解释对噪点的需求。
假设下图是由StyleGAN生成的。事实并非如此,但假设是这样。您可以看到它包含各种具有不同粒度的组件:
- 较低粒度的组件,例如头部(特别是其位置)、躯干等。对于human类的每个实例,它们都是相对平等的。
- 相反,更高粒度的组件(例如头发)在人与人之间不同,而且在同一个人的照片之间也不同。头发在图片中的位置取决于相对确定的选择(例如发型),但也取决于看似随机的影响(例如风)。
噪声决定了这些更高粒度的组件。下图中女人的头发在什么位置?如果它是由 StyleGAN 生成的,那么它就不会由您接下来会听到的样式驱动,而是由随机性驱动,从而产生噪声。
噪声张量是从高斯分布中得出的(Karras 等人,2018)。

2.3 w 如何转换为样式
现在我们知道噪声如何为生成的图片添加随机性,是时候了解样式以及它们如何控制图像合成过程了。
这从映射网络生成的潜在向量w开始。
该向量被馈送到下面概述中称为A 的部分——神经网络的学习仿射变换部分。
在欧几里得几何中,仿射变换或亲和力(来自拉丁语,affinis, “连接”)是保留直线和平行度(但不一定是距离和角度)的几何变换。
维基百科
例如,如果我们有向量2 \\ 3,仿射变换将能够产生向量4 \\ 6(尺度 2 在空间中具有相同的线,但只是更长,因此没有保留距离)。
从概念上讲,这意味着仿射变换可以在不彻底修改图像的情况下改变图像分量,因为仿射变换的输出必须与输入“连接”,即潜在向量w。
输入向量w转换为样式y,其中y = ( y _s, y _b)。这些分别是样式的比例和偏差组件(您将在下面了解它们的使用方式)。它们具有与它们将控制的合成张量相同的形状。
仿射变换是在训练期间学习的,因此是可用于控制较低粒度组件(例如发型、肤色等)的图像合成过程的组件,而请记住,使用的是随机性例如,控制单根毛发的位置。
您现在应该能够解释样式和随机性如何使我们能够生成独特的图像。现在让我们更精确地了解样式如何控制图像生成。
基于自适应实例标准化的样式添加
与样式加法相关的是两个向量的向量加法:
- 添加噪声的常量张量(在第一个 4x4 像素合成块中)或到目前为止生成的张量(对于其他合成块)。
- 仿射变换,然后进行自适应实例标准化(AdaIN)标准化。
这是 AdaIN 的样子:

这里,x_i是输入Tensor的第i个特征图(即向量的第i个元素), y是仿射变换生成的样式。
您可以在中间部分看到,特征图首先被归一化(或者更确切地说,标准化)为零均值、单位方差,然后通过样式缩放组件中的第i个元素进行缩放,并添加第i个偏差组件随后。
换句话说,AdaIN 确保生成的样式可以通过改变比例和/或偏差来控制(标准化)合成输入。这就是样式如何控制添加噪声的输入张量上的图像合成过程!
第二个和更高的合成块 - 上采样,然后控制
上面的文本主要关注第一个合成块 - 其输出是 4 x 4 像素图像。正如你可以想象的那样,这还不足以给人留下深刻的印象。

后续合成块(8x8、16x16、最高 1024x1024 像素)的工作方式与第一个合成块略有不同:
- 首先,应用双线性上采样对图像进行上采样,然后使用具有 3x3 内核的 2d 卷积层进行学习下采样。
- 随后,添加噪声,之后执行用于风格控制的AdaIn操作。
- 然后,使用类似的卷积层进行另一个下采样,之后执行另一个噪声和风格控制。
对于第一层,这会生成 8x8 像素的图像,依此类推。
最终结果
StyleGAN 在面部训练时的最终结果非常惊人!
在我的下一篇文章中,我们将了解如何使用 PyTorch 实现 StyleGAN。感谢您的阅读!

资料参考
Karras, T.、Laine, S. 和 Aila, T. (2018)。用于生成对抗网络的基于样式的生成器架构。 arXiv 预印本 arXiv:1812.04948。
Goodfellow, IJ、Pouget-Abadie, J.、Mirza, M.、Xu, B.、Warde-Farley, D.、Ozair, S.……和 Bengio, Y. (2014)。生成对抗网络。 arXiv 预印本 arXiv:1406.2661。